運転データから運転手を特定、機械学習で交通事故を予防できるか:1万人を対象に実験
損害保険ジャパン日本興亜(以下、損保ジャパン日本興亜)と理化学研究所の革新知能統合研究センターは共同で、「運転データによる大規模ドライバー識別技術」と「多重比較補正を利用した統計的軌跡マイニング技術」を開発した。交通事故予測のための研究成果だ。事故リスク評価モデルなどを支える基盤アルゴリズムとして実用化する。
損害保険ジャパン日本興亜と理化学研究所の革新知能統合研究センターは2019年11月14日、「運転データによる大規模ドライバー識別技術」と「多重比較補正を利用した統計的軌跡マイニング技術」を開発したと発表した。
これらは、2018年3月から両者が進めている交通事故予測に向けた共同研究の成果。損保ジャパン日本興亜は、今回の成果を基に、事故リスク評価モデルなどを支える基盤アルゴリズムとしての実用化を目指す。
運転データから運転手を特定
運転データによる大規模ドライバー識別技術は、機械学習を活用して、運転データから対象の運転手を特定する手法。
スマートフォン用のカーナビアプリ「ポータブルスマイリングロード」で収集した運転データを基に、運転手を識別する。最大1万人を対象にした検証実験では、評価用の手法よりも高い精度で識別できたとしている。
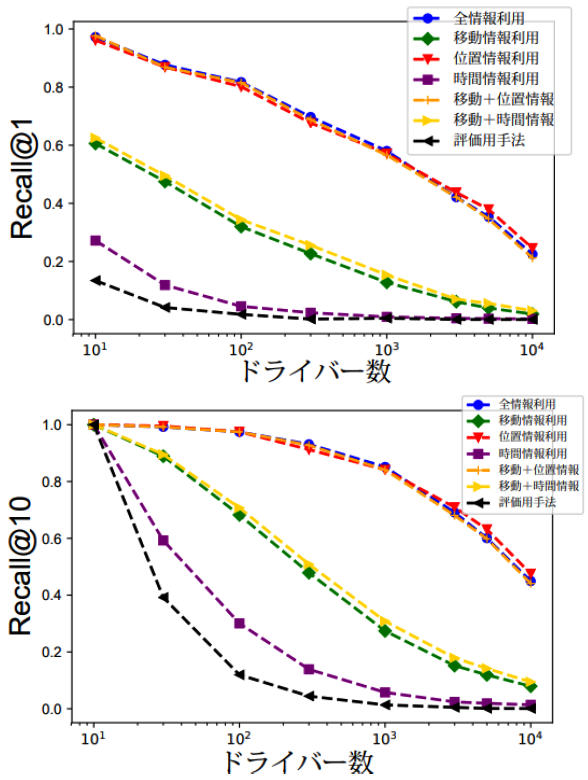
既存のドライブレコーダーを用いた法人向け運転診断では、複数の運転手が同一車両を運転した場合、運転データのみから対象ドライバーを特定することは困難だった。
事故歴のあるドライバーの運転はどこが違うのか
統計的軌跡マイニング技術は、統計的信頼度を評価するための新たなアプローチ「Statistically Discriminative Sub trajectory Mining(Stat DSM)」に基づき、走行データなど移動体の軌跡データを扱う分析手法の一つであるTrajectory Miningを評価する。異なる属性を持つ2つのグループの間にあるパターンの差異を抽出する際に役立つ。
例えば、事故歴がある運転手と事故歴がない運転手の間に、一方のグループで特徴的に発生する軌跡パターンを検出するなどだ。
一般に、実際に観測したデータには観測誤差が含まれることから、こうしたパターンを抽出するには、計算時に統計処理をする必要がある。だが従来の手法では、大規模なデータセットの計算に適用することは困難だったという。

多重比較補正を利用した統計的軌跡マイニング技術では、Statistically Discriminative Sub-trajectory Mining(Stat-DSM)という手法を採用した。Stat-D10SMでは、木構造に軌跡パターンを格納して統計的推論を適用することで、大規模な実データに対する計算を可能にしたとしている。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 第4回 手を動かして強化学習を体験してみよう(自動運転ロボットカーDeepRacer編)
第4回 手を動かして強化学習を体験してみよう(自動運転ロボットカーDeepRacer編)
強化学習が初めての人に最適な「AWS DeepRacerのコンソールとシミュレーション環境」を使って、ディープラーニングを体験してみよう。コンソール上で強化学習の各ハイパーパラメーターを設定してモデルに学習させ、さらに評価し、バーチャルレースにデプロイするまでの手順を解説する。 Lesson 2 機械学習やディープラーニングには、どんな手法があるの?
Lesson 2 機械学習やディープラーニングには、どんな手法があるの?
藍博士とマナブの会話から機械学習とディープラーニングの基礎の基礎を学ぼう。機械学習を始めるための最低限の基礎用語から、ディープラーニングの代表的な学習方法と代表的なアルゴリズムまでをできるだけシンプルに紹介する。 SOMPOホールディングスは、機械学習/AI、クラウドをどう活用しようとしているか
SOMPOホールディングスは、機械学習/AI、クラウドをどう活用しようとしているか
SOMPOホールディングスは、2016年にSOMPO Digital Labを東京とシリコンバレーに設立、これを実働部隊としてデジタル戦略の具体化を急いでいる。その裏には保険業界が根本的な変革を迎えつつあるとの危機感があるという。SOMPOホールディングスのチーフ・データサイエンティスト、中林紀彦氏がAWS Summit 2017で行った講演から、同社の取り組みを探る。