
XMLデータベース開発方法論(2) Page 3/4
スケーラビリティの重大な誤解、
“大は小を兼ねない”
川俣 晶
株式会社ピーデー
2005/7/22
ここで一度話をまとめよう。
ここまで、情報(ソースコードは情報の一種)の規模が性質の差をもたらすように思える事例を見た。このような事例はほかにもいろいろある。それらが意味するところは、つまり「情報は思いどおりにならない」ということである。情報には形がなく、重さもなければ体積もなく、触れることもできない。それにもかかわらず、情報は現実世界に実在しており、情報を律する独自の法則性に従って振る舞う。その法則は、情報の規模が変わった場合に、性質が変わることを要求することがある。利用者である人間が、変わってほしくないと思っていても、性質は変わってしまう。それを止めることは、人間にはできない。情報を支配しているのは人間ではなく法則だからである。
そう考えると、情報=バーチャルを扱うということと、実在する現実のモノを扱うことは、本質的に変わりがないことが分かる。つまり、対象を律する法則を理解し、それをうまく使うことで目的を達することが必要とされる。例えば飛行機が空を飛ぶことと、何らかの情報処理を実現することは、本質のレベルでは同じだといえる。飛行機が空を飛ぶのは、人間が空を飛べと命じたからではない。自然界には気圧が高いところから低いところへ物体を引っ張る力が発生するという法則を活用して、上下に気圧差を発生させる翼を作り出したからである。
同様に、情報処理も人間が「処理しろ」と命じるだけではうまくいかない。情報の特質を正しく把握し、それを効率良く活用するようにシステムを構築しなければならない。今回のテーマ(規模と性質)に沿って、より具体的にいい直せば、効率の良いシステムにするには、そのシステムが扱う情報の規模を見極め、その規模での情報の特徴、つまり性質をうまく活用するようにシステムを設計していく必要がある。
このような観点から見たときに重要なポイントとなるのは、大は小を兼ねないという認識である。規模の違いが性質の違いをもたらすことがある以上、最善を求めるなら、規模の違いに応じて、最善のシステムの在り方も変わる。つまり、大は小を兼ねない。
- ポイント:大は小を兼ねない
ここでいう「大は小を兼ねない」とは、例えば大規模データの処理に特化して成功したアーキテクチャをスケールダウンして、小規模データの処理用ソフトとして提供した場合、それがうまく機能する保証は存在しないことを意味する。うまく機能する可能性もあるが、常にうまく機能するとは限らない。
ここからは、個別のデータ処理技術に着目した具体的な話題に入っていこう。つまり、大きな一般論から個別論に向けて、階段を1段下りる。
前回、さまざまなデータ処理技法があり、そこから選択する必要性について述べた。そこで、RDBを定型の代表、AWKを不定型の代表と位置付けた。もちろん、定型、不定型とは型が定まっているか否かを示す言葉であって、規模を指し示す言葉ではない。しかし、定型、不定型とは情報の性質を表現する言葉であり、規模の違いが性質の違いにつながるという今回のテーマに即して考えれば、規模とも何らかの関係があるかもしれない。そのように考えて、規模という視点でRDBとAWKを比較してみよう。
まず、RDBは大規模データに強い処理技法であるといえる。おそらく、パソコン上で一般的に使用されるデータベースの中で、最も大きな規模に対応するのはRDBではないかと思う。一方で、AWKは大規模データにはまったく弱い。すべてテキストで処理する関係上、効率は非常に良くない。しかし、規模が小さいデータを扱う場合に限れば、前回見たように、AWKの方がお手軽にデータ処理を実現できる。このように、RDBとAWKは得意とする規模が異なり、相互に棲み分けるべきものだと見ることもできる。この2つは、定型、不定型という相違でもすみ分け可能だが、規模という観点からも棲み分け可能ということである。つまり、RDBとAWKの得意分野は、この2つの基準を用いて示すことができる。規模が大きく定型のデータにRDBは向き、規模が小さく不定型のデータにはAWKが向くということである。
だが、ほかの組み合わせはどうだろうか。ここでは、まだ「規模が小さく定型のデータ」と「規模が大きく不定型のデータ」が、いずれに向くかが語られていない。まず、規模が小さく定型のデータはどうだろうか。これはAWKの得意分野の範囲と考えてよいだろう。なぜなら定型のデータとは、たまたま例外的な記述を含まない不定型のデータの一種と考えられるためである。では、規模が大きく不定型のデータはどうだろうか。このようなデータはRDBにもAWKにも向かない。強いていえば、XMLデータベース向きといえるが、その話題は後で再び取り上げるとして、考察を続けよう。なぜRDBにもAWKにも向かないデータがあり得るのだろうか。その理由は、データを定型の枠にはめるメリットを考えることで見えてくる。
定型の枠をはめるとは、例えばあるテーブルのすべてのレコードの特定のフィールドには、必ず整数の数値が格納されているというルールを徹底的に貫徹することである。そのようなルールを貫徹するのは大変な作業ではあるが、もちろんそれによって大きなメリットを得られるから行うのである。このようなデータを処理する場合、そのレコードにそのフィールドが存在するかチェックする必要もなければ、整数になっているかチェックする必要もない。それは必ず存在し、必ず整数なのである。チェックが不要になることで、データ処理の効率が高くなる。つまり、データの定型性を推し進めると、データ処理の効率を上げられるのである。いい換えれば、より少ないCPUパワー注で、より多くのデータを処理できるようになる。データに強い定型の枠をはめるメリットはほかにもいろいろあるが、きりがないのでここでは例を1つ示すだけにとどめておこう。
注:CPUパワー
ここでは、CPUと呼ばれるチップの性能ではなく、PCの総合性能(バスやメモリやHDDの性能も込み)という意味でCPUパワーという言葉を使う。
そして、不定型処理の特徴はこの裏返しとなる。AWKの不定型なデータ処理は、実はCPUの利用効率があまり良くない。テキスト形式のデータを読み込むから効率が悪い、という理由のほかに、データの不定型さそのものが、処理の効率を落とす原因になっている。例えば、あるレコードに何個のデータが含まれるかは、読み込んでみるまで分からない。分からない以上、それをいちいち確認しながら処理を進めねばならない。必然的に、CPUの負担は増える。つまり、不定型データ処理とはCPUの能力を無駄遣いすることによって成立するぜいたく過ぎるやり方だと理解してもよいだろう。それ故に、RDBとAWKを比較したとき、利用可能なCPUパワーによって、RDBなら処理可能であるのに、AWKでは処理できない(CPUパワー不足)となるケースが考えられる。
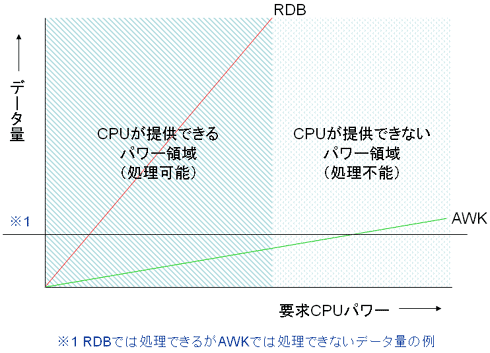 |
| 図9 RDBとAWKの消費CPUパワー (この図はイメージを示すもので具体的な数値を反映したものではない) |
つまり、この図から読み取れる結論はこうである。規模が大きく不定型のデータはCPUパワーの要求量が極めて過大になる傾向にあり、現実に存在するCPUではそもそも処理できないという可能性が考えられる。仮に、データ処理技法の候補がRDBとAWKしかなく、二者択一が迫られているとすれば、手間をかけてデータを分析し、整理し、正規化し、定型データに直したうえでRDBを用いて処理しなければならない。いくら、不定型データ処理に価値があると思ったところで、ない袖(CPUパワー)は振れない。そして、データが極度に大きな不定型性を持っていて定型データに直せない場合は、そもそも処理不可能という結論になることもあり得る。(次ページへ続く)
| 3/4 |
| Index | |
| XMLデータベース開発方法論(2) スケーラビリティの重大な誤解、“大は小を兼ねない” |
|
| Page
1 ・前回のおさらいと今回のテーマ ・自らの最終学歴を語る三重苦 ・化学工学の華はスケールメリット ・層流と乱流、規模(スケール)が変わると性質が変わる例 |
|
| Page 2 ・情報の規模が変わると性質は変わるか? |
|
| Page 3 ・情報は人間の思いどおりにならない ・規模から見たRDBとAWKの違い |
|
| Page 4 ・CPUパワーの拡大と中間領域の拡大 ・次回予告 |
|
| XMLデータベース開発論 |
- Oracleライセンス「SE2」検証 CPUスレッド数制限はどんな仕組みで制御されるのか (2017/7/26)
データベース管理システムの運用でトラブルが発生したらどうするか。DBサポートスペシャリストが現場目線の解決Tipsをお届けします。今回は、Oracle SE2の「CPUスレッド数制限」がどんな仕組みで行われるのかを検証します - ドメイン参加後、SQL Serverが起動しなくなった (2017/7/24)
本連載では、「SQL Server」で発生するトラブルを「どんな方法で」「どのように」解決していくか、正しい対処のためのノウハウを紹介します。今回は、「ドメイン参加後にSQL Serverが起動しなくなった場合の対処方法」を解説します - さらに高度なSQL実行計画の取得」のために理解しておくべきこと (2017/7/21)
日本オラクルのデータベーススペシャリストが「DBAがすぐ実践できる即効テクニック」を紹介する本連載。今回は「より高度なSQL実行計画を取得するために、理解しておいてほしいこと」を解説します - データベースセキュリティが「各種ガイドライン」に記載され始めている事実 (2017/7/20)
本連載では、「データベースセキュリティに必要な対策」を学び、DBMSでの「具体的な実装方法」や「Tips」などを紹介していきます。今回は、「各種ガイドラインが示すコンプライアンス要件に、データベースのセキュリティはどのように記載されているのか」を解説します
|
|





