 |
||
|
連載 .NETで簡単XML 第4回 DOM(Document Object Model) 株式会社ピーデー 川俣 晶2003/05/08 |
||
|
Back Issue
|
||||||
|
XML文書は一種のテキスト・データであるが、通常、プログラムからはこれをテキスト・ファイルとして開かない。その代わりに、XMLパーサと呼ばれるプログラムを通してXML文書を読み書きする。その際、XMLパーサを呼び出すためのインターフェイスがいくつか存在する。本連載の第2回、第3回では、XmlReader/XmlWriterを取り上げたが、今回はDOM(Document Object Model)を取り上げる。
DOM(Document Object Model)とは何か?
DOM(Document Object Model)は、World Wide Web Consorium(W3C)が勧告する標準技術である。これにはいくつかのレベルがあり、個々のレベルはさらにいくつかの個別の仕様に分かれている。この中には、直接XMLとは関係ないHTMLのための仕様も含まれる。現在、主にLevel 2のDOMが使用されていて、Level 3のDOMに関する各種仕様が策定途上にある。.NET Frameworkに含まれるDOMは、「DOM Level 1およびLevel 2で規定されているAPIを拡張」とされている。つまり、W3CのDOMに、独自の拡張を加えたものとなっている。今回は連載の趣旨から、この独自の拡張も含めた範囲で解説を行っているので注意されたい。
さて、DOMとは具体的にどのようなものだろうか。Document(文書)Object(オブジェクト)Model(モデル)という言葉から分かる通り、DOMはXML文書をオブジェクト指向的な意味でのオブジェクトで表現するモデルである。XML文書を構成するさまざまな部分が、それぞれオブジェクトに対応する形となる。例えば、要素には要素の、属性には属性の固有のクラスが定義されており、それらのインスタンスを作成して利用する。厳密には、W3CのDOMで定義されるものは主にインターフェイスであってクラスではないのだが、ここではそのインターフェイスを実装したクラスを利用することを前提に、クラスということで話を進めよう。
DOMを特徴づけるもう1つの性質は、オブジェクトを木構造(ツリー)として扱うということである。XML文書は、要素などがネストするために階層構造になる。例えば、要素の内容に要素があって、その内容にまた要素があって……というXML文書は珍しくない。これを最もストレートに表現するモデルが木構造というわけである。以下のような図を見ると分かりやすいだろう。
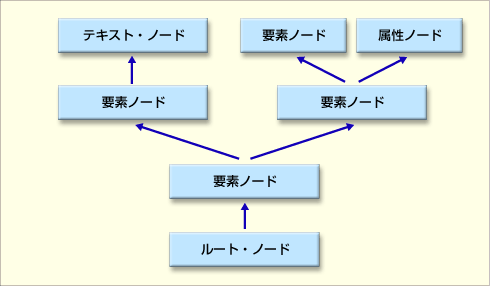 |
| 木構造で表現したXML文書 |
ツリーを構成する各部分はノードと呼ばれる。木の根としてルート・ノードがあり、そこから幹が伸び、枝が伸びるように、さまざまな役割を持つノードが広がっている。文書中のどの部分も、ルート・ノードから順番に枝をたどっていくと到達することができる。また、どのノードからでも、下に向かってたどっていくとルート・ノードに到達することができるのである。
DOMとXmlReader/XmlWriterとの違い
さて、前回、前々回で解説したXmlReader/XmlWriterとはどこが違うのだろうか。XmlReader/XmlWriterは、個々の部分に対して個別のクラスを持つ構造になっていない。例えば、要素を書きたければ、WriteStartElementメソッドなどを呼び出すだけで、特に要素を表現するクラスは扱わない。
また、XmlReader/XmlWriterはデータにアクセスする順番がXML文書の前方から後方に向かって一直線と決まっているのに対して、DOMはどの枝から順番にたどってもよく、アクセス順序に制限はない。XML文書内のどこから処理するか、順番に制限はないということである。それゆえに、DOMの方が自由度は高いといえる。しかし、それはメリットだけをもたらすわけではない。XmlReader/XmlWriterは処理対象となっている部分だけを処理しながら動作するが、DOMは常にXML文書全体を扱いながら動作する。つまり、両者には必要メモリ量という点で大きな差があるということである。例えば、数GBもある巨大なXML文書があったとすると、XmlReader/XmlWriterはわずかなメモリ消費でそれを処理することができるが、DOMはまずそのXML文書全体をメモリ上に読み込んで木構造を作成するので、膨大なメモリを必要とするわけである。
もう1点、これと関連する相違として、読み込みを開始してから最初の情報を処理するまでのタイム・ラグの違いがある。XmlReaderは読み込みを開始してからすぐに最初の情報を処理することができる。しかし、DOMは、XML文書全体の解析が終ったあとでないと、どの情報にもアクセスすることができない。メモリ消費量やタイム・ラグの問題は、もしかしたらDOMの実装方法次第で変わる可能性もあるが、.NET FrameworkのDOMに関しては、これらの問題が生じる思って間違いないだろう。
このように、DOMとXmlReader/XmlWriterには異なる特徴があり、必要に応じて使い分けられるべきものなのである。
今回のサンプル・プログラムについて
今回のサンプル・プログラムは、Visual Basic .NET(以下VB.NET)とC#で記述してある。VB.NETのソースを掲載し、C#のソースはリンクとしているので、必要に応じてダウンロードしてほしい。開発環境としてはVisual Studio .NETを使用することを前提にしている。サンプル・プログラムはすべてWindowsアプリケーションとしてプロジェクトを作成後に、フォームのLoadイベントに実行するコードを書き込み、Trace.WriteLineメソッドで結果を出力し、統合開発環境の出力ウィンドウで結果を確認するように構成されている(一部例外あり)。それぞれのソースの先頭には、以下のコードが書かれているものとする。
|
|
| VB.NET版のサンプルに必要なImportsステートメント | |
| INDEX | ||
| .NETで簡単XML | ||
| 第4回 DOM(Document Object Model) | ||
| 1.DOM(Document Object Model)とは何か? | ||
| 2.DOMを用いてXML文書を作成するプログラム | ||
| 3.DOMを用いてXML文書を読み込むプログラム | ||
| 4.XML文書内のデータを書き換える | ||
| 「連載 :.NETで簡単XML」 |
- 第2回 簡潔なコーディングのために (2017/7/26)
ラムダ式で記述できるメンバの増加、throw式、out変数、タプルなど、C# 7には以前よりもコードを簡潔に記述できるような機能が導入されている - 第1回 Visual Studio Codeデバッグの基礎知識 (2017/7/21)
Node.jsプログラムをデバッグしながら、Visual Studio Codeに統合されているデバッグ機能の基本の「キ」をマスターしよう - 第1回 明瞭なコーディングのために (2017/7/19)
C# 7で追加された新機能の中から、「数値リテラル構文の改善」と「ローカル関数」を紹介する。これらは分かりやすいコードを記述するのに使える - Presentation Translator (2017/7/18)
Presentation TranslatorはPowerPoint用のアドイン。プレゼンテーション時の字幕の付加や、多言語での質疑応答、スライドの翻訳を行える
|
|





