解説IDF 2007, Beijingレポート
|
 |
2007年4月17日と18日の2日間、中国の北京でIntelの開発者向け会議「Intel Developer Forum(IDF)」が開催された。1997年秋の第1回以来、年に2回のIDFは、最初に米国で開催され、その後に世界各地を巡回するのが常だった。しかし2005年5月に最高経営責任者(CEO)へ就任したポール・オッテリーニ(Paul Otellini)社長のリストラ方針の下、IDFの開催形態も見直された。その結果、開催地、開催回数とも絞られることとなり、2007年の春は北京のみで開催となった。IDFは過去に中国で開催されたことはあるが、いずれも米国での開催後のツアーの一環としてのものであった。グローバル・イベントとして、IDFが米国外で開かれるのはこれが初めてとなる。
IDF開催前に大連への工場建設を発表
IDFが米国外開催となったことは、当然、そこに集まる人たちにも影響を及ぼす。一般の来場者はもちろんのこと、キーノート・スピーチで壇上に招かれるゲストも、中国の検索サイト・トップの「百度(Baidu」)、大手PCベンダの「Lenovo」、ソフトウェア・アウトソーシング事業大手の「Inspur浪潮」など地元中国企業のエグゼクティブが多数を占め、いずれもIntelとのパートナーシップを強調していた。逆にIntelがIDFの開催地に中国を選んだのも、急発展中の中国経済を意識してのことだろう。すでに2カ所にある半導体の後工程工場に加え、前工程工場を大連に建設することをIDFの前に明らかにするなど、中国に対する投資を積極化している(もちろん中国政府に対するアピールの意味もあるだろう)。
大連に建設される新工場は、Fab 68と呼ばれる。Intelの工場はつい最近までは数字の順番に従って建設されてきた。45nm世代の工場(イスラエルのFab 28およびアリゾナ州のFab 32)から、数字が連続しなくなったが、大連工場は数字が一気に68まで飛んでいる。初日のトップ・キーノートを行った最高技術責任者(CTO)のジャスティン・ラトナー(Justin Rattner)氏によると、この数字は単に縁起を担いだだけ、ということだ。6には「Smooth Sailing(順風満帆)」、8には「Prosperity(繁盛)」の意があるとされた。この意味の出典についてはよく分からないが、縁起のよい漢字と音が同じ数字を縁起がいいとするのはポピュラーな風習のようで、六は「禄」(禄高、福禄寿などに使われる字、幸いを示す)、八は「発」(発展や発達)にかかっているといわれており、いずれも現代中国でとても縁起がよいとされる数字のようだ。
現時点でFab 68の製造品目はチップセットとされており、Intelとしては2世代遅れの300mmウエハ/90nmプロセスの工場になるようだ。これは、米国政府が認める範囲内での最先端プロセスを使いたい、というところでのギリギリの線が、90nmプロセスであったようだ。本来ならば、これから建設する工場なので、Intelとしては最先端の45nm/32nmプロセスを導入したいところだが、中国は米国の輸出規制対象国であるため、2世代遅れの製造プロセスで何とか許可が取れたようである。一部の報道では、操業開始時に65nmプロセス化する輸出許可が取れ、すぐに65nmプロセスに移行するのではないかといわれている。このように極めて重要な項目に制約があるにもかかわらず、中国に工場建設の決定を行うあたりに政治的な意図がうかがえる。
2007年内に45nmプロセス製造によるプロセッサの量産開始
こうした地元中国の影響が大きくなる一方で、従来のIDFで中心となっていた米国人の来場者は大幅に減ってしまった。これは報道関係者やアナリストも同様で、やはりアジア圏のメディアや金融機関が中心となっていた。IntelはIDFに先立つ2007年3月末に、45nmプロセス製造によるプロセッサに関して概要を公開しているが、これは中国のIDFに米国のメディアなどがあまり参加しないことに配慮したものかもしれない。
とはいえ、45nmプロセス製造への移行と、45nmプロセス製造のプロセッサとそのプラットフォームが、IDFの話題の中心であったことは間違いない。PC向けのプロセッサについては、あまり情報の上積みはなかったものの、プラットフォームに関する情報や、新セグメント向けのプロセッサについては新しい情報が公開された。
まずPC向けプロセッサだが、2007年内にも45nmプロセス製造によるプロセッサの量産が始まる。いわば第1世代になる45nmプロセッサは、これまでPenryn(ペンリン)という開発コード名で総称されていたものだ。1つのダイ上に2つのプロセッサ・コアと共有される2次キャッシュを持つ。サーバ向けのデュアルコア(Wolfdale-DP:ウルフデール・ディーピー)とクワッドコア(Harpertown:ハーパータウン)、デスクトップPC向けのデュアルコア(Wolfdale:ウルフデール)とクワッドコア(Yorkfield:ヨークフィールド)、モバイル向けのデュアルコア(Penryn:ペンリン)の合計5種類の存在が明らかにされている。クワッドコア・プロセッサはデュアルコアのダイ2枚を1つのパッケージに封入したマルチチップ・モジュールとなる。これら5種類のうち、モバイル向けに関しては2008年のリリースとなることが確実視されているものの、サーバ向けとデスクトップPC向けについては、全種とは限らないが2007年内に出荷が始まる見込みだ。
| ターゲット | 開発コード名 | コア数 |
| サーバ向け | Wolfdale-DP(ウルフデール・ディーピー) | 2 |
| サーバ向け | Harpertown(ハーパータウン) | 4 |
| デスクトップPC向け | Wolfdale(ウルフデール) | 2 |
| デスクトップPC向け | Yorkfield(ヨークフィールド) | 4 |
| モバイル向け | Penryn(ペンリン) | 2 |
| Penrynファミリのラインアップ | ||
 |
 |
| 45nmプロセスによるDPサーバ向けクワッドコア・プロセッサのHarpertown(上)と現行の65nmプロセスによるClovertown(下) |
| マイクロアーキテクチャの改良に加え、2次キャッシュ容量の増加や動作クロックの引き上げで性能は向上するが、TDP(熱設計電力)は維持される。 |
Penrynファミリは、最初の45nmプロセス製造によるプロセッサということで、基本的には現行のCore 2 Duo/Quadプロセッサと同じCoreマイクロアーキテクチャに基づくものとなる。これは、新マイクロアーキテクチャの開発と、新製造プロセスの採用を同時に行うことによるリスクを回避するための措置である。ただ、同じマイクロアーキテクチャといっても、単純な45nmプロセス製造への縮小(シュリンク)ではない。
Penrynファミリに用いられる45nmプロセスは、初めて金属ゲート材料とHigh-k絶縁膜を用いる(High-kについては頭脳放談「第9回 銅配線にまつわるエトセトラ」参照のこと)。High-k絶縁膜の採用により、リーク電流の削減やトランジスタのスイッチング速度の向上、トランジスタ密度の向上といったメリットが得られる。これを生かしてPenrynファミリでは2次キャッシュの増量(4Mbytesから6Mbytesへ)と、動作クロックおよびFSBクロックの引き上げが行われる。6Mbytesに増量される2次キャッシュが2つのコアで共有される仕様であることは、現行の65nmプロセスのCoreマイクロアーキテクチャと変わらないが、キャッシュの仕組みを改良し、より効率が高められる。製品の最終的な動作クロックについてはまだ明らかにされていないが、IDFの会場やキーノート・スピーチでは、3.2GHzや3.33GHzといった動作クロックでデモが行われていた。またFSBについては、ハイエンド品は1600MHzに達することが明らかにされている。
 |
| Intelの45nmプロセスの概要 |
| 初めてHigh-k絶縁膜と金属ゲートを採用するIntelの45nmプロセス。リーク電流およびスイッチング電流の削減による省電力と、トランジスタのスイッチング速度の向上による高性能化の両立を図る。 |
さらにマイクロアーキテクチャ面での改良として、Super Shuffle(スーパー・シャッフル)エンジンやSSE4命令の追加によるメディア性能の強化、基数を16にした除算器(Radix-16 divider)の追加による除算性能の高速化、ATA命令の搭載などが加えられる。
Super Shuffleエンジンは、SIMD命令に用いる128bitレジスタ内のデータの並べ替え(シャッフル)を高速化するもので、47の命令が拡張されたSSE4命令を高速に実行することにも寄与する。
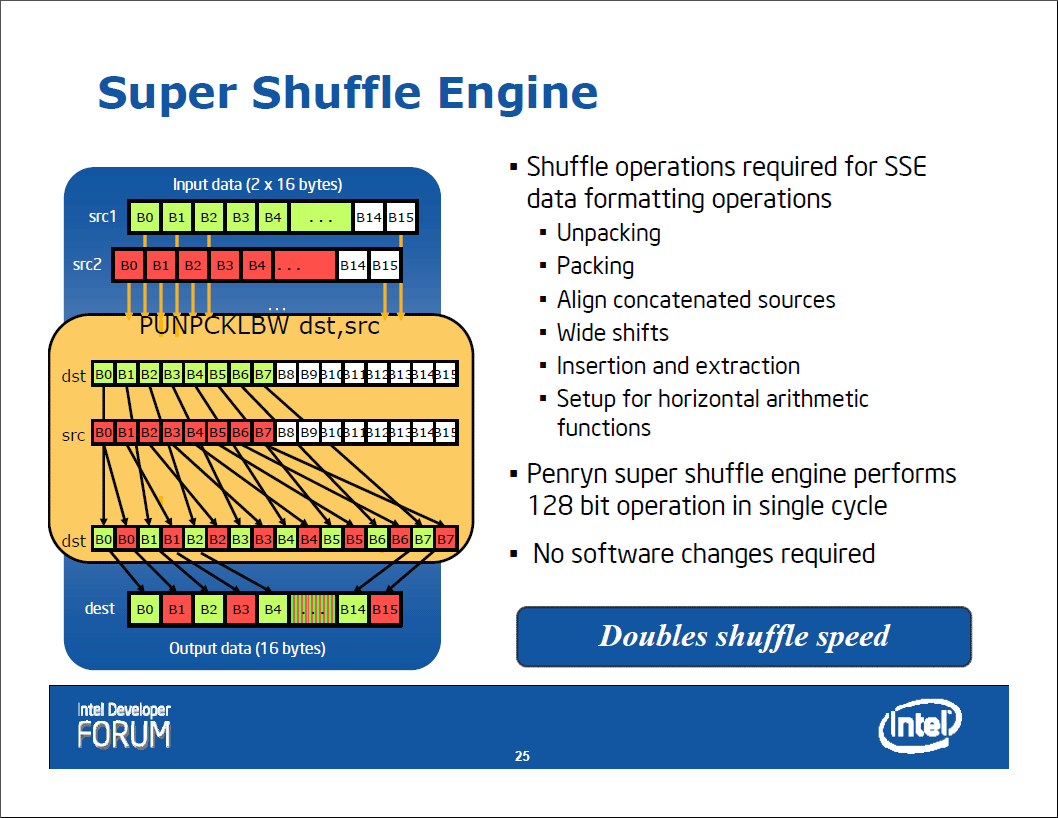 |
| Super Shuffleエンジンの機能 |
| Penrynファミリに搭載されるSuper Shuffleエンジンは、データの並べ替えを1サイクルで実現するもの。SSE命令は、Super Shuffleエンジンを内部で利用することで、命令の高速化が実現できるということだ。 |
ATA命令は、「Application Targeted Accelerators」の略で、特定アプリケーションの高速化を意図した追加命令を指す。Penrynではエラー・チェックに幅広く用いられるCRCを高速化する命令が追加された。またRadix-16 dividerによる除算性能の向上は、従来の除算器の約2倍とされ、ソフトウェアからは透過的に利用される(ソフトウェアの対応を必要としない)。ほかにも仮想化支援機能のVT-xの拡張、セキュリティ機能のTrusted eXecution Technology(LaGrande:ラグランデ・テクノロジ)への対応などが図られる。
さらにモバイル向けのプロセッサに関しては、省電力機能を強化する技術として、Deep Power Down TechnologyとEnhanced Dynamic Acceleration Technologyが追加される。Deep Power Down Technologyは、1次キャッシュと2次キャッシュの電源を完全にオフにすることで、従来の最も低消費電力なプロセッサ・ステートであったC4ステートよりもさらに待機時の消費電力を引き下げるものだ。
 |
| Deep Power Down Technologyの概要 |
| Deep Power Down Technologyは、1次/2次キャッシュの電源をオフにすることで、待機時の電力消費をさらに引き下げることを可能にする。ただし待機モードからの復帰には多少時間がかかるようになる。 |
Enhanced Dynamic Acceleration Technologyは、2つあるプロセッサの片方がC3以下の省電力状態になった場合に、動作しているもう片方のコアの動作クロックを1段階引き上げようというものである。アイドルなコアが低消費電力ステートに入ることで生じたTDPの余裕を、動作しているコアの動作クロックを引き上げに用いようというものである。これにより、シングルスレッド・アプリケーションの性能が向上することになるが、問題は現在の利用環境で、2つあるコアの片方がアイドルになる状況がどれだけあるのか、ということだろう。実際、Windows Vistaではバックグラウンドで動作するサービスがWindows XPより増えており、Enhanced Dynamic Acceleration Technologyを活用できるシチュエーションはあまりないのではないかという懸念も聞かれる。
 |
| Enhanced Dynamic Acceleration Technologyの機能 |
| デュアルコアのうち、片方のコアがアイドルになることで生じたTDPの余裕を、動作しているコアの動作クロックの引き上げに用いる。 |
| 関連記事 | |
| 第9回 銅配線にまつわるエトセトラ | |
| INDEX | ||
| [解説]IDF 2007, Beijingレポート IntelがIDFで見せた次世代プラットフォーム | ||
| 1.2007年に45nmプロセス製造への移行を開始するIntel | ||
| 2.見ててきたIntelの次世代プラットフォームの姿 | ||
| 3.次世代マイクロアーキテクチャは2008年に登場予定 | ||
| 「System Insiderの解説」 |
- Intelと互換プロセッサとの戦いの歴史を振り返る (2017/6/28)
Intelのx86が誕生して約40年たつという。x86プロセッサは、互換プロセッサとの戦いでもあった。その歴史を簡単に振り返ってみよう - 第204回 人工知能がFPGAに恋する理由 (2017/5/25)
最近、人工知能(AI)のアクセラレータとしてFPGAを活用する動きがある。なぜCPUやGPUに加えて、FPGAが人工知能に活用されるのだろうか。その理由は? - IoT実用化への号砲は鳴った (2017/4/27)
スタートの号砲が鳴ったようだ。多くのベンダーからIoTを使った実証実験の発表が相次いでいる。あと半年もすれば、実用化へのゴールも見えてくるのだろうか? - スパコンの新しい潮流は人工知能にあり? (2017/3/29)
スパコン関連の発表が続いている。多くが「人工知能」をターゲットにしているようだ。人工知能向けのスパコンとはどのようなものなのか、最近の発表から見ていこう
|
|





