元麻布春男の焦点
明らかになるItanium 2の性能とプラットフォーム 1. 大幅に性能が向上するItanium 2 元麻布春男 |
|

2002年夏の正式リリースを控え、Itanium 2(開発コード名:McKinley)関連の情報がかなり豊富に得られるようになってきた。さすがに、最も注目される「いつ(発表日)」や「いくら(価格)」といった情報は直前あるいは当日まで秘密にされるようだが、チップセットの情報、さらには得られるべき性能といった情報まで公開され始めている。また、IDFを始めとする各種のイベントでは、「参考出品」というただし書き付きではあるものの、Itanium 2を搭載した実機のデモンストレーションが「普通に」行われている。ここでは、こうしたItanium 2関連の情報をまとめておくことにしよう。
Itanium 2の改善ポイント
Itanium 2は、Intelの64bitマイクロアーキテクチャに基づく第2世代のプロセッサ製品だ。つまり「第2世代のItaniumプロセッサ・ファミリ製品」ということになる。McKinley(マッキンリー)という開発コード名が与えられていたItanium 2の最大の特徴は、将来にわたる共通したプラットフォームの提供と、2001年5月30日にリリースされた第1世代のItanium(開発コード名:Merced)に対する大幅な性能向上の2点にある。
下図は、最近IntelがItaniumプロセッサ・ファミリのロードマップとして公開しているものだ。この図の要点は、この夏にリリースされるItanium 2は、将来のMontecito(開発コード名:モンテシト)まで続くItaniumプロセッサ・ファミリの共通プラットフォームに対応した最初のプロセッサになる、ということだ。つまり、Itanium 2、Madison(開発コード名:マディソン)、Deerfield(開発コード名:ディアフィールド)、Montecitoの各プロセッサはピン互換性を維持する。図では、この共通プラットフォームがいつごろまで維持されるかを明記しなかったが、現時点では2005年までは維持される予定だ。Itanium 2のプラットフォーム(チップセット)には、Intelだけでなく、Hewlett-Packard、日立製作所、IBM、日本電気など多くのサードパーティが開発投資を行っている。一定期間にわたる共通プラットフォームの保証は、こうした投資の有効性を保護すると同時に、プラットフォームの成熟度を高めることにも寄与するものと思われる。
 |
| Itaniumプロセッサ・ファミリのロードマップ |
| Itanium 2からMontecitoまで同じプラットフォームが利用できることが約束されている。 |
|
■Deerfield(ディアフィールド) ■Montecito(モンテシト) |
もう1つのポイントである高性能化について、IntelやそのOEMであるサーバ・ベンダは、Itanium用にコンパイルされたバイナリ(すなわちItanium 2用に最適化、あるいは再コンパイルされていない既存のバイナリ)ベースで、1.5〜2倍の性能を達成したとしている。そして、この高性能は以下の4つのポイントにより実現したとする。
- コア・クロックの引き上げ
- システム・バス帯域幅の拡大
- キャッシュ・システムの改善
- マイクロアーキテクチャの改善
まずプロッセッサ・コアの動作クロック引き上げだが、Itaniumでは800MHzにとどまっていた最高動作クロックが、Itanium 2では1GHzに引き上げられる(25%の向上)。システム・バスも、64bit幅266MHz(133MHzベース・クロックのダブル・データ・レート)から、128bit幅400MHz(同200MHz)に向上した。データ転送レートでいうと2.1Gbytes/sから6.4Gbytes/sと、3倍向上したことになる。
レーテンシが大幅に改善された内蔵キャッシュ
キャッシュ・アーキテクチャの改善で最も目立つのは、オン・ダイ化された3次キャッシュの存在だ。Itaniumでは、4Mbytesの3次キャッシュが搭載されていたものの、プロセッサ・パッケージ内に封入された外部メモリによるものであったため、プロセッサ・コアからキャッシュ・メモリへのアクセス時のレーテンシ(遅延)が20クロックと大きかった(帯域幅は11.7Gbytes/s)。Itanium 2では、容量こそ3Mbytesに減少しているものの、3次キャッシュがオン・ダイ化されたことで、レーテンシが12クロックへと大幅に縮小している。キャッシュ・メモリの帯域幅も32Gbytes/sと拡大された。
加えてItanium 2では、1次キャッシュ(容量はItaniumと同じ32Kbytes)のレーテンシが2クロックから1クロックへと改善される。これにより、15〜25%の性能向上が得られるだけでなく、ロード遅延ペナルティの削減により、コンパイラのスケジューリングが簡易になるとしている(逆にいえば、Itaniumはスケジューリングの難しいプロセッサであった)。と同時に、2次キャッシュのレーテンシも12クロックから、5クロックへと向上している。また、容量もItaniumの96Kbytesから256Kbytesへと拡大された(帯域幅は64Gbytes/s)。いい換えればItanium 2の3次キャッシュは、Itaniumプロセッサの2次キャッシュ並みの短いレーテンシを実現しているということになる。2次キャッシュの容量拡大は、プロセッサの動作クロックの向上に伴い、分岐予測の失敗に対するペナルティが大きくなるのをカバーするためであるという。
Itanium 2で改善されたマイクロアーキテクチャ
マイクロアーキテクチャの改善という点では、命令発行ポートの追加と実行ユニットの追加、の2つが大きなポイントだ。Itaniumプロセッサ・ファミリが採用するEPICアーキテクチャでは、同時実行可能な命令を3つ組み合わせた「バンドル」を単位に処理が進められる。ItaniumもItanium 2も、1クロック当たり最大2バンドルの処理能力を持っているため、最大1クロックあたり6命令の処理が可能ということに変わりはない。
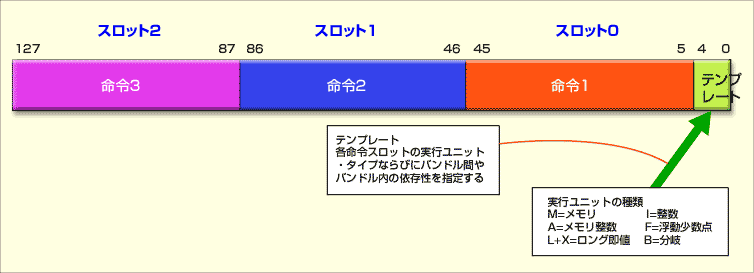 |
| EPICアーキテクチャが採用するバンドル |
| 図のように3つの命令+テンプレートで構成されたバンドルを単位として命令の実行が行われる。テンプレートには、バンドル内の命令の依存関係などが記述される。 |
バンドルに収納された命令は、2バンドルを単位にDispersal Window(ディスパーサル・ウィンドウ)と呼ばれる命令発行ステージに進み、そこで命令発行ポートを経て命令実行ユニットへと送られる。もし、Dispersal Window内にある2つのバンドルの全命令が発行されてしまえば、次の2つのバンドルがバッファから読み込まれる(2バンドル・ローテーション)。しかし、もしどちらかのバンドルの命令が発行できない場合は、2バンドル・ローテーションを行うことができない。2バンドルのうち、最初のバンドルの命令発行が完了しない場合、それが完了するまでDispersal Windowの更新は止まってしまう。また、2番目のバンドルの命令発行が完了しない場合、2番目のバンドルが次のサイクルで最初のバンドルとなり、2番目の位置にバッファからバンドルが1つだけ読み込まれる(シングル・バンドル・ローテーション)。
つまり、Itaniumプロセッサ・ファミリで高性能を得るには、バンドル内の命令をどんどん発行し、どんどんバンドル・ローテーションさせていくことが重要ということになる。Itanium 2で命令発行ポートと実行ユニットが増えた理由は、もちろんバンドル・ローテーションの促進にある。Dispersal Windowでバンドル内の命令は、ある種の分散ネットワークで命令発行ポートへと導かれるが、どのバンドルのどの命令スロットからも、クロスバー・スイッチのように等しく同じように命令発行ポートを利用できるわけではない。キャッシュ、実行ユニット、命令ポートなど、プロセッサ内のどのリソースにどれだけのシリコンを割くかというのは、プロセッサの性能全体から見るべき問題であり、完全なクロスバー・スイッチの採用はシリコンの利用効率的に必ずしも最善ではない、ということがこうした偏ったネットワークを採用する理由になっているようだ。
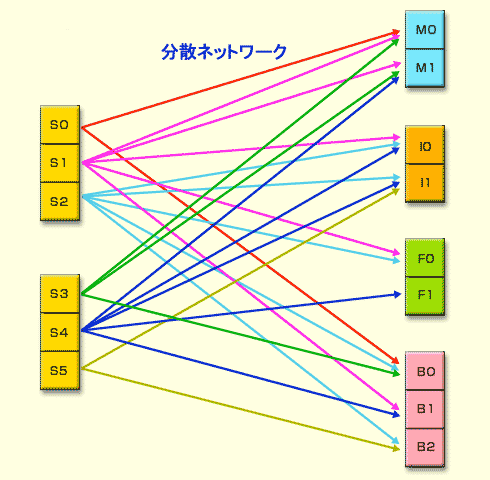 |
| 命令スロット(左側)と実行ユニット(右側)の関係 |
| この図のようにすべての命令スロットが、すべての実行ユニットに命令を発行できるわけではない。 |
| MII | MLI | MMI | MFI | MMF | MIB | MBB | BBB | MMB | MFB | |
| MII | ||||||||||
| MLI | ||||||||||
| MMI | ||||||||||
| MFI | ||||||||||
| MMF | ||||||||||
| MIB | ||||||||||
| MBB | ||||||||||
| BBB | ||||||||||
| MMB | ||||||||||
| MFB | ||||||||||
| Itanium 2が発行可能なバンドルの組み合わせ | ||||||||||
| ItaniumとItanium 2の両方とも発行可能なバンドルの組み合わせ | ||||||||||
| 2つのバンドルの発行可能な組み合わせ | ||||||||||
| このようにItaniumに比べてItanium 2は発行可能なバンドルの組み合わせが増えてはいるものの、すべての組み合わせが可能なわけではない。 | ||||||||||
Itanium 2では、命令ポート数をItaniumの9ポートから11ポートに増やし、実行ユニットの数そのものを増やしたことに加え、分散ネットワークのチューニングを、新しいアプリケーション・プログラムをベースに更新している(命令スロットと命令発行ポートの関係を見直している)。つまりバンドル・ローテーションが停止しにくくなっており、Itanium 2の大幅な性能向上に寄与している。
| 関連リンク | |
| Itanium 2の性能に関するニュースリリース | |
| INDEX | ||
| 明らかになるItanium 2の性能とプラットフォーム | ||
| 1.大幅に性能が向上するItanium 2 | ||
| 2.大規模システムも可能にするItanium 2のチップセット | ||
| 「System Insiderの連載」 |
- Intelと互換プロセッサとの戦いの歴史を振り返る (2017/6/28)
Intelのx86が誕生して約40年たつという。x86プロセッサは、互換プロセッサとの戦いでもあった。その歴史を簡単に振り返ってみよう - 第204回 人工知能がFPGAに恋する理由 (2017/5/25)
最近、人工知能(AI)のアクセラレータとしてFPGAを活用する動きがある。なぜCPUやGPUに加えて、FPGAが人工知能に活用されるのだろうか。その理由は? - IoT実用化への号砲は鳴った (2017/4/27)
スタートの号砲が鳴ったようだ。多くのベンダーからIoTを使った実証実験の発表が相次いでいる。あと半年もすれば、実用化へのゴールも見えてくるのだろうか? - スパコンの新しい潮流は人工知能にあり? (2017/3/29)
スパコン関連の発表が続いている。多くが「人工知能」をターゲットにしているようだ。人工知能向けのスパコンとはどのようなものなのか、最近の発表から見ていこう
|
|





