
XMLフロンティア探訪
第13回 よく利用されるXML Schemaのデータ型(前編)
RELAX NGでは、外部のデータ型ライブラリとしてXML Schema Part 2で定義されているデータ型を利用できると前回説明した。しかしXML Schemaのデータ型はRELAX NGだけでなく、今後XMLが活躍する多くの場面で利用されるはずだ。そこで今回と次回は、XML Schema Part2のデータ型を詳しく紹介していく。(編集局)
川俣 晶株式会社ピーデー
2002/6/5
| 今回の主な内容 |
前々回「実は新構文になっているRELAX NG 」、前回「どんなデータ型も利用可能なRELAX NG」と、スキーマ言語のRELAX NG(リラクシング)を解説してきた。RELAX NGでは、データ型ライブラリとして「XML Schema Part 2:Datatypes」が利用できるわけだが、そうはいってもXML Schema Part 2のデータ型にどんなものがあるのかが分からなければその利点もさっぱり分からない、というご指摘をいただいた。そこで今回は、XML Schema Part 2の概要を説明したいと思う。なお、XML Schema Part 2は、XMLが利用される場面で広く利用されるデータ型といえる。今回の内容はRELAX NGの利用者だけでなく、XML Schemaやそのほか多くのXML開発者にも意味のある内容だと思う。
さて、データ型といえば、整数型、実数型、文字列型などを思い浮かべる人も多いと思う。プログラム言語(例えばC言語)では、整数型はintという名前で表現されている。通常は、intは整数型という認識でよい。しかし、同じ整数型でもlongのように名前が異なるものがある。これは、一般的には表現するビット数がintよりも多い整数型を意味する。intとlongはどちらも整数型だが、表現力が違うと理解できる。つまり整数型は、整数型というだけでは不十分で、さらに分類される必要があるということだ。
もう1つ注意すべきことは、XMLにおいては、数値であろうと、すべては文字の組み合わせで表現されるということだ。例えば、100という数値を表現するために“1”と“0”と“0”という3文字を並べる。プログラム言語ならビットの組み合わせで表現してしまうので、100という値に対応するビットの組み合わせは1種類しか存在しない。だが、XMLの場合は文字の並びで表現するため、同じ値の表現に異なるバリエーションが生じる場合がある。例えば、実数の100.0は、指数表示の“1.0E2”と書いても、同じ値を表現している。こういった異なる表現をどこまで認めるかは、重要な意味を持つ。さらに、有効な数値の範囲などの制限も、(スキーマ言語としては)もちろん必要である。XMLは文字列で数値を表現するため、数字を並べて書くだけでいくらでも巨大な数値を記述できるのだ。しかし、実際にその数値を処理するプログラム言語の方では、無制限に大きな数値を受け入れ可能というわけではない。それぞれのプログラム言語が持つ最大値と最小値の制限がある。そのような制限事項も付けてやらねばならない。
そこでXML Schema Part 2では、データ型は3つの要素の組として表現される。1つ目は、値空間(value space)と呼ばれ、データ型のための値のセットである。2つ目は、字句空間(lexical space)と呼ばれ、データ型のための適切な文字のセットである。最後は、相(facet)と呼ばれ、値空間に対してさまざまな特徴を付加するものである。
例えば、実数を表す“100.0”と“1.0E2”は、値空間の表現では同じ値と見なされる。指し示す値が同じだからである。しかし、字句空間では別の表現と見なされる。記述された文字が違っているためである。そして相は、この型の最大値と最小値など、値空間に与えられる制限などを指定するために用いられる。この3組の概念がセットになったものが、XML Schema Part 2の型システム(Type System)と呼ばれるものである。
XML Schema Part 2の名前空間は、XML Schema Part 1: Structuresとともに使用する場合は、http://www.w3.org/2001/XMLSchemaであるが、単独で使用する場合は、http://www.w3.org/2001/XMLSchema-datatypesを使用する。RELAX NGでXML Schema Part2のデータ型を使用する場合は後者が相当する。
XML Schemaのデータ型は、主に、組み込み型(Build-in DataType)と、複合型(Complex Type)に分けられる。組み込み型は、XML Schema Part 2であらかじめ定義されているデータ型であり、複合型とは、XML Schema Part 1の構文を用いてスキーマ作成者が自分で定義する型である。
組み込み型はさらに、組み込み基本データ型(build-in primitive type)と、組み込み派生データ型(built-in derived type)の2つに分けられる。組み込み基本データ型は、基本的な数値や文字列を表現するものである。それに対して、組み込み派生データ型とは、組み込み基本データ型より派生して定義されるデータ型である。例えば、トークン(token)は文字列の一種でもあるが、文字列と違った条件が付けられている。この場合、文字列から派生させて、トークンというデータ型を定義するわけである。
データ型の全体像は、XML Schema Part 2に含まれる図によれば、このような形になる。
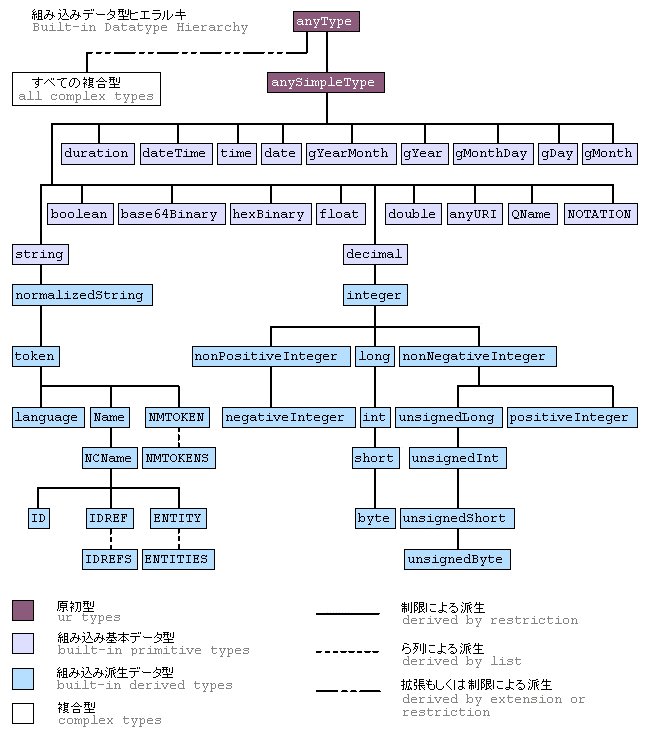 |
| XML Schema Part 2の組み込みデータ型の図(オリジナルを加工し、一部日本語化しました) |
では、まず組み込み基本データ型から見てみよう。なお、ここではそれぞれの型に付加できる相について名前のみ列挙している。それぞれの相の詳細は、後でまとめて解説する。
| string | |
|
最も基本的な、文字列型である。stringの値空間は、XML 1.0勧告で記述されている通常の文字の一連の並びに等しい。つまり、XML 1.0勧告でXML文書に文字として記述が許されているすべての文字が記述できる。すべての文字が使えるので、字句空間を問うことに意味はない。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| boolean | |
|
バイナリ値を表現するデータ型である。この型は、true、falseで表現することも、1、0で表現することもできる。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| decimal | |
|
固定小数点の数値データ型である。固定小数点といっても、小数部がないものとすれば、そのまま整数型を派生できる。固定小数点型を使わないユーザーでも、整数として間接的に利用することが多いかもしれない。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| float | |
|
IEEE単精度32bit浮動小数点型を表現するデータ型である。浮動小数点型にはもう1つ、double型があるが、これらはどちらも組み込み基本データ型であり、相互に継承関係はない。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| double | |
|
IEEE単精度64bit浮動小数点型を表現するデータ型である。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| duration | |
|
時間経過の長さを表現するデータ型である。グレゴリオ暦の年、月、日、時、分、秒の情報を内部に持つ。数秒の時間経過でも、年単位の時間経過でも、どちらでも表現できる。また、ある瞬間の日付時刻を表現するにはdateTime型を使う。つまり、durationは、あるdateTimeと別のdateTimeの差の値を表現するために使用されるものである。 具体的にこれを表現するためには、ISO 8601(Data elements and interchange formats -- Information interchange -- Representation of dates and times)で定義された構文を使用するのだが、これは小さな言語といえるぐらい複雑なもので、数行では要約できない。XML Schema Part 2のAppendix Dに、「ISO 8601 Date and Time Formats」として解説が記述されているので、詳しく知りたい人はまずここから見るとよいだろう。 概要を述べれば、durationは「PnYnMnDTnHnMnS」という書式で表現する。Pは経過を表し、YMDHMSは、それぞれ、年月日時分秒に当たる。Tは、日付と時刻を分離するために表記される。例えば、1年と1秒経過した場合は、「P1YT1S」となる。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| dateTime | |
|
日付時刻を表現するデータ型である。これも、duration型と同じく、ISO 8601で定義された構文を使用する。 概要を述べれば、「CCYY-MM-DDThh:mm:ss」という書式で表現する。CCは世紀、YYは年、MMは月、DDは日、hhは時、mmは分、ssは秒である。Tは、日付と時刻を分離するために表記する。例えば、西暦2002年6月1日の午前10時は、「2002-06-01T10:00:00」と表記される。日本時間を明示するなら、さらに「-09:00」のような時差を示す文字列を付加する。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| time | |
|
dateTime型は日付と時刻をワンセットで表現するが、time型は時刻のみを表現する。これも、dateTime型と同じく、ISO 8601で定義された構文を使用する。 概要を述べれば、「hh:mm:ss.sss」という書式で表現する。タイムゾーンも付加することができる。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| date | |
|
dateTime型は日付と時刻をワンセットで表現するが、date型は日付のみを表現する。これも、dateTime型と同じく、ISO 8601で定義された構文を使用する。 概要を述べれば、「CCYY-MM-DD」という書式で表現する。タイムゾーンも付加することができる。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| gYearMonth | |
|
年と月の情報のみを記述するデータ型である。この値は、指定された1カ月間の全体の範囲を示し、月の初めの瞬間を表現するわけではない。これも、dateTime型と同じく、ISO 8601で定義された構文を使用する。 概要を述べれば、「CCYY-MM」という書式で表現する。タイムゾーンも付加することができる。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| gYear | |
|
年の情報のみを記述するデータ型である。この値は、指定された年の全体の範囲を示し、年の初めの瞬間を表現するわけではない。これも、dateTime型と同じく、ISO 8601で定義された構文を使用する。 概要を述べれば、「CCYY」という書式で表現する。タイムゾーンも付加することができる。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| gMonthDay | |
|
月の中の日を表現するデータ型である。この値は、指定された日の全体の範囲を示し、日の初めの瞬間を表現するわけではない。これも、dateTime型と同じく、ISO 8601で定義された構文を使用する。 概要を述べれば、「--MM-DD」という書式で表現する。タイムゾーンも付加することができる。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| gDay | |
|
月の中のある日を表現するデータ型である。月の情報は含まないので、例えば、講習会に出席する日は毎月25日、というような25日を表現するために使用する。この値は、指定された日の全体の範囲を示し、日の初めの瞬間を表現するわけではない。これも、dateTime型と同じく、ISO 8601で定義された構文を使用する。 概要を述べれば、「--DD」という書式で表現する。タイムゾーンも付加することができる。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| gMonth | |
|
年の中のある月を表現するデータ型である。年の情報は含まないので、例えば、新人研修は毎年4月に行う、というような4月を表現するために使用する。この値は、指定された月の全体の範囲を示し、月の初めの瞬間を表現するわけではない。これも、dateTime型と同じく、ISO 8601で定義された構文を使用する。 概要を述べれば、「--MM」という書式で表現する。タイムゾーンも付加することができる。なお、XML Schema Part 2には「--MM--」と書かれているが、訂正(E2-12)として、このような書式にするという修正が入っている。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| hexBinary | |
|
XMLは、文字の並びを扱う言語であるため、バイナリ情報はそのままでは扱うことができない。そこで、バイナリ情報を文字にエンコードして扱うことになる。そのような目的に利用できるエンコード方法は、何種類もあるが、XML Schema Part 2では、2つの方法を用意している。その1つが、このhexBinary型である。この型は、バイナリデータを「0〜9」「a〜f」「A〜F」の文字の並びで16進数として表現する。例えば、「1234ABCD」のような文字列で表現することになる。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| base64Binary | |
|
hexBinary型と同様に、バイナリ情報を表現するデータ型だが、16進表記ではなく、Base64を用いる点が異なっている。いうまでもなく、16進表記よりもBase64の方がより小さな容量で同じ情報を表現することができる。しかしBase64では、元の数値が何であるか、表記された文字から推理するのは難しくなる。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| anyURI | |
|
任意のURIを許すデータ型である。例えば、筆者の会社のホームページを示す「http://www.piedey.co.jp/」は正しいURIである。しかし、これを言葉で説明した「弊社のサイト」は、(読み手に意味は伝わったとしても)正しいURIではない。URIとして正しい文字列ではない場合は、エラーを出すことができる。 この型を深く理解するには、XML Schema Part 2のほかにRFC 2396「Uniform Resource Identifiers (URI): Generic Syntax 」と、XLinik(XML Linking Language)にも目を通す必要がある。また、この型は基本的にすべてのURIを有効とするので、「ftp:」「mail:」などで始まるあらゆるタイプのスキームでも受け付けてしまう。httpだけ有効、などとしたい場合は、pattern相を付加して範囲を限定するといった配慮が必要である。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| QName | |
|
QName(Qualified Name)はNamespace in XMLで定義されているもので、名前空間接頭辞を付けることができる名前である。通常は、要素や属性の名前として利用するものだが、要素や属性の内容として、名前空間接頭辞の付いた名前を記述したい場合がある。そのような場合に、このQName型を指定する。 具体的なQNameの書式などは、Namespace in XMLの解説などを参照していただきたい。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| NOTATION | |
|
記法を示すデータ型である。記法そのものがXMLの世界ではめったに使われない機能なので、詳しい説明は割愛する。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
ここまで見てきた組み込み基本データ型は、それ自体が有益な型であるが、それから派生させた多くのバリエーションも存在する。以下はそのバリエーションを見ていこう。
| normalizedString | |
|
string型より派生したデータ型である。空白文字が正規化された文字列を扱う。 normalizedString型の値空間は、キャリッジリターン(#xD)、ラインフィード(#xA)、タブ(#x9)のいずれも含まれない文字列である。normalizedString型の字句空間は、キャリッジリターン(#xD)、タブ(#x9)のいずれも含まれない文字列である(ここで、値空間と字句空間で禁止されている文字の種類が異なっているが、XML Schema Part 2でそのように定義されているものである)。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| token | |
|
normalizedString型より派生したデータ型である。NMTOKENなどをさらに派生させる基になる型であり、これをそのまま使うことは少ないかもしれない。token型は、ラインフィード(#xA)とタブ(#x9)を含まず、前後に空白文字(#x20)を持たず、中間に含まれる空白文字は2文字以上の長さを持たない文字列である。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| language | |
|
token型より派生したデータ型である。RFC 1766で定義された自然言語の識別子を表現する。詳しいことは、XML 1.0勧告の2.12 言語識別(Language Identification)のところを読むとよいだろう。例えば、日本の日本語なら、ja-JPと表記する。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| NMTOKEN | |
|
token型より派生したデータ型である。XML 1.0勧告のNMTOKEN型(名前トークン)に相当するものである。具体的な内容は、XML 1.0勧告の定義に従う。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| NMTOKENS | |
|
NMTOKEN型より派生したデータ型である。XML 1.0勧告のNMTOKENS型(名前トークンの列)に相当するものである。具体的な内容は、XML 1.0勧告の定義に従う。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| Name | |
|
token型より派生したデータ型である。XML 1.0勧告のNameのルールに従う名前を表現するデータ型である。QNameと似ているが、Nameの方は名前空間を意識しない定義となっている。XMLで使われる各種名前と同じルールで付けられた名前を扱う場合に利用できる。つまり、数字で始まらない多種多様な名前文字での名前付けを許すために利用する。なお、この名前にはコロン記号(:)を含んでよいが、この記号は名前を構成する文字の1つと見なされ、区切り文字とは見なされない。具体的な内容は、XML 1.0勧告の定義に従う。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
| NCName | |
|
Name型より派生したデータ型である。Namespace in XMLのNCNameに相当するデータ型である。Nameと異なるのは、コロン記号(:)が名前を構成する文字として利用できないことである。具体的な内容は、Namespace in XMLの定義に従う。 QNameとNameとNCNameはそれぞれ似て非なる役割を持っているので、指定するときには慎重に選ぼう。例えば、abc:defという値があったとき、QNameは、abcを名前空間接頭辞と見なし、defをローカル名と見なす。しかし、Nameの場合はこれを全体で1個の名前と認識する。NCNameとして見た場合は、入ってはならないコロン記号(:)が入っているので、これは検証エラーとなる。 この型に付加できる相の一覧は以下のとおりである。 |
|
|
今回はここまでだが、まだまだXML Schema Part 2のデータ型は続く。残りは次回を請うご期待である。
| ISO化が近づくRELAX NG RELAX NGの開発者の1人である村田真氏が、5月26日に日本XMLユーザーグループのメーリングリストに投稿した内容によると、RELAX NGは、5月18日から22日にかけてバルセロナで行われたISO/IEC JTC1 SC34会議の決議により、 Draft International Standardになったという。この後、6カ月間の投票をへてISOのInternational Standardになることがほぼ確実視されている。 (編集局) |
| 「連載 XMLフロンティア探訪」 |
- QAフレームワーク:仕様ガイドラインが勧告に昇格 (2005/10/21)
データベースの急速なXML対応に後押しされてか、9月に入って「XQuery」や「XPath」に関係したドラフトが一気に11本も更新された - XML勧告を記述するXMLspecとは何か (2005/10/12)
「XML 1.0勧告」はXMLspec DTDで記述され、XSLTによって生成されている。これはXMLが本当に役立っている具体的な証である - 文字符号化方式にまつわるジレンマ (2005/9/13)
文字符号化方式(UTF-8、シフトJISなど)を自動検出するには、ニワトリと卵の関係にあるジレンマを解消する仕組みが必要となる - XMLキー管理仕様(XKMS 2.0)が勧告に昇格 (2005/8/16)
セキュリティ関連のXML仕様に進展あり。また、日本発の新しいXMLソフトウェアアーキテクチャ「xfy technology」の詳細も紹介する
|
|





