コトバのインフラ整備、著作権処理で法外なコスト
国立国語研究所が大規模コーパスを試験公開
2007/05/28
「風景」と「光景」の意味や使い方の違いは? そんな疑問に答えるためには、用例辞典が役立つ。しかし、文例が少なかったり具体的な使い分けの方法が分からなかったりといったことも少なくない。こうした問題に役立つのは本物の文例を集めた実例集だ。人々が実際にどのように言葉を使っているのかを、その言語の母語話者が話したり書いたりした文例を集めることで解明する。
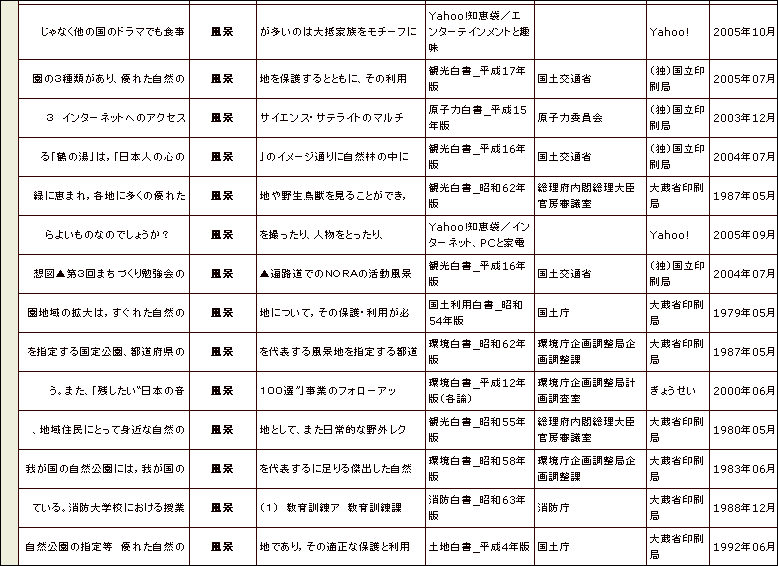
そうした文例集は言語学や情報処理の研究者の間では「コーパス」(corpus)と呼ばれている。コーパスを用いれば、例えば「風景」は、ほかの語彙と結びついて「心象風景」「研修風景」「風景鑑賞」などの合成語を作るのに対して、「光景」のほうは、「日常的光景」「歴史的光景」といった「的」を伴う3例をのぞいて合成語をほとんど作らないという違いが、すぐに分かる。
品詞情報や係り受けといった文法情報を付加することで、言語研究や辞書編纂といった用途ばかりでなく、国語教育や外国人向けの日本語教育への応用、心理学・認知科学の実験における言語刺激の統制、コンピュータを使った言語処理アルゴリズムの評価用データ、常用漢字や表記基準の見直しを検討するための基礎データとなる。
1960年代に英国を中心に開始されたコーパス作りは、欧米を中心にさまざまな言語圏で進められてきた。現在、英語、米語、スペイン語、中国語などで大規模なコーパスが入手できるが、日本語では長らく大規模コーパスが整備されてこなかった。言語研究の世界でも情報処理の世界でもコーパスが果たす役割の重要性は増しているが、コストがかさむことから、大学などの研究機関ではコーパス作成は難しかった。
現在、独立行政法人 国立国語研究所は明治から現代にいたる日本語を電子化して公開する「KOTONOHA計画」を推進している。その一環として現代日本語の書き言葉を集める『現代日本語書き言葉均衡コーパス』を2006年にスタート。完成は2011年を予定しているが、完成時に約1億語となるコーパスの一部分、約1000万語分のデータのインターネット上での試験公開を、5月28日に開始した。一般公開されるのは単純な全文検索だけが可能なWebページだが、学術利用や商用利用に対してはXMLでマークアップされたコーパスも有償で提供していく。
今回収録したデータは、官公庁が発行する白書のデータ約500万語、ヤフーが提供する「Yahoo!知恵袋」のデータ約500万語の合計約1000万語分。役所の堅い文体の日本語と、ネットの掲示板に書かれるカジュアルな日本語の両方を一度に検索対象にできる。白書は最大過去30年前のものまで含むため、いつ頃「ら抜き言葉」が一般化したか、といったこともすぐに分かる。
著作権処理で法外なコスト、“言葉のインフラ整備”に黄色信号
 国立国語研究所 研究開発部門 言語資源グループ長の前川喜久雄氏
国立国語研究所 研究開発部門 言語資源グループ長の前川喜久雄氏現代日本語書き言葉均衡コーパスでは今後、バランスよく現代日本語を収録するために、国会議事録、新聞記事、文芸作品、ブログなどもデータに加える予定だ。
課題は著作権処理だ。今回、ヤフーが提供したネット掲示板の一種であるYahoo!知恵袋では、サービスの利用開始時に投稿者に投稿メッセージの非独占的利用の権利をヤフー側に認めるように確認しているため、今回のコーパスのような2次利用も可能だった。しかし、多くの刊行物については著作権者に許諾を求める必要がある。同研究所 研究開発部門 言語資源グループ長の前川喜久雄氏は「著作権保護、個人情報保護意識の高まりを反映して、著作権者との連絡にかかるコストが著しく増大する傾向にあり、著作権処理の成否がプロジェクト全体に大きく影響する」という。著作権処理団体に属していない個人の場合、連絡先が判明するのが4割で、そのうち約半分からしか回答が戻ってこないという。5年間で7〜8億円というプロジェクト費用の大部分は人件費で、著作権処理の事務処理コストも大きな割合を占める。「現在の日本は世界に例がないほど著作権保護に厳しく、フェアユースという通念もない。著作権保護と公共利用を、どう両立させていくかが課題だ」(前川氏)。大規模コーパスを整備することの社会的意義を訴えるのも、今回の試験公開の目的という。
情報をお寄せください:
最新記事
|
|

