DBWeb 2007講演レポート
次世代検索はグーグルの上に構築
2007/11/27
 京都大学大学院情報学研究科の田中克己教授
京都大学大学院情報学研究科の田中克己教授「インターネットの検索において、Webページ検索というのは、そろそろピークを過ぎるのではないか。人物や商品などドメインを区切ったバーチカルサーチや、Webページではなく知識そのものを検索できるようなナレッジサーチなどが今後の研究テーマになってくる」。2007年11月27日から2日間の予定で開催されている「データベースとWeb情報システムに関するシンポジウム」(DBWeb 2007)において「情報爆発に対処できる次世代サーチ技術」と題した講演を行った京都大学大学院情報学研究科の田中克己教授は、今後のネット検索技術の動向をそう総括する。
既存の検索サービスを使ってできることはまだまだある
田中氏は、2005年から5年間の予定で文部科学省が研究補助金を出すプロジェクト「情報爆発時代に向けた新しいIT基盤技術の研究」において「情報爆発に対応するコンテンツ融合と操作環境融合に関する研究」という研究テーマを担当するグループの代表者を務めている。その田中氏がイメージする次世代検索サービスは、既存の検索に取って代わるようなものではないという。「現行の大手検索サービスに取って代わるようなものではないし、そうした次世代のサーチエンジンをスクラッチで作ろうと思わない。既存のサーチエンジンは質の高いインデックスを持っていて、それを集約することで、まだまだ実現できる新サービスはたくさんある」からだ。例えば「浅間山の標高は?」というクエリに対して、そのものずばりの答えを数字で示すようなサービスは、既存の検索エンジンを利用して作成できる。研究者たちが“Web集約質問処理”と呼ぶこうした応用によって、「渋谷の典型的な印象は?」、「フェラーリのライバルは?」といった検索が可能になるという。
アノテーションをランキングに反映
 京都大学大学院情報学研究科 社会情報学専攻特任助教の中村聡史氏
京都大学大学院情報学研究科 社会情報学専攻特任助教の中村聡史氏田中氏に続いて研究成果を発表した京都大学大学院情報学研究科 社会情報学専攻特任助教の中村聡史氏は「ちょうどWindows上でグーグルが成功しているように、グーグルの上で新しい検索サービスが可能。そうしたものが世界を変えるのでは」という。
「次世代検索は“人”を中心にしたものになるのではないか」と語る中村氏は、アノテーションに基づく検索結果の再ランキングや、ユーザーの行動に基づく集合的アノテーションをランキングに反映する研究をしている(注:アノテーションは英語で注釈のことだが、ここではユーザーが加えるタグや追加情報のこと)。根底にある問題意識は現在の検索サービスの制約だ。「例えば、東京、ホテルで検索すると200万件近いリンクが出るが実際にユーザーが見るのは上位5〜10件。これはUIが困難であるのが問題。また、SEO対策のために精度も高くない」(中村氏)。
こうした背景から中村氏が作成した「rerank.jp」はユーザーがランキングを動的に変えられる検索サービスのプロトタイプだ。rerank.jpでは検索結果や検索結果のタグクラウドからキーワードをユーザーが明示的にピックアップさせて「強調/削除」を選ばせる。例えば「豚肉 ピーマン」で検索した結果から「ニンニク」という語彙を含むリンクのランキングを落としたり、逆に「なす」を含むリンクのランキングを上げることができる。それは「検索結果のなかを自由に歩いているようなもの」(中村氏)という。
中村氏は、利用者自身によるアノテーションだけでなく、集合的アノテーションを取り入れた検索サービス「SBSearch」にも取り組む。SBSearchでは、既存のソーシャルブックマークでのブックマーク数やキーワードをランキングに反映させたり、ある一時期にネット上で話題になったページを重視するのか、逆に長期間にわたって一定の話題を集めているページを重視するのなどをユーザーは選べる。こうすることで「150〜200位のページを手軽に上位に上げられる」(中村氏)といい、検索するユーザーにとって価値のある情報だがランキングの下の方に埋もれていたようなページにたどり着くことができるようになるという。ソーシャルブックマークサービスでは、内容を示す“内容タグ”(例:IT、Web、ソーシャル、検索)と“印象タグ”(例:おもしろい、これはすごい、便利)があるといい、印象タグを生かすことで「コンテンツ自体に含まれていない語彙で検索結果をフィルタ」できるのだという。
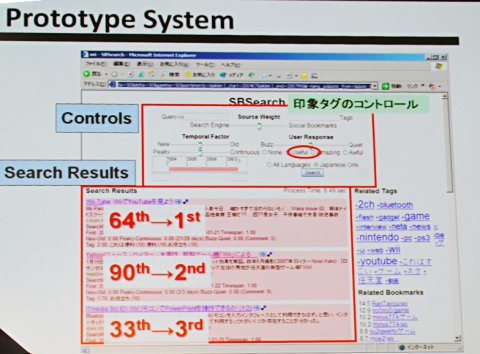 中村氏が開発した「SBSearch」のプロトタイプ。スライドバーでパラメータを変更してアノテーションを検索ランキングに反映させることができる
中村氏が開発した「SBSearch」のプロトタイプ。スライドバーでパラメータを変更してアノテーションを検索ランキングに反映させることができる既存検索サービスとSQL文で「浅間山の標高」を求める
もし次世代検索サービスが、既存のインデックスを活用するタイプのものになるとするなら、同じく京都大学大学院情報学研究科社会情報学専攻特任助教の大島裕明氏が発表したWeb検索関連の研究用ライブラリ「Sloth Lib」「EaRDB」はきわめて興味深いツールだ。
検索サービスでいいアイデアを思いついても実装するのは大変だ。「形態素解析だ特徴ベクトルの作成・計算だ、クラスタリングだと長い準備が必要」(大島氏)だからだ。新たに研究室に入ってくる下級生のために既存の各種検索サービスや、よく知られた検索関連のアルゴリズムをライブラリとして作成したSloth Libを使えば「かつて1日かかったことも10分程度でできるようになる」のだという。抽象化レイヤを挟むことで検索サービスやアルゴリズムを切り替えることも「1行書き換えるだけで可能」という。例えば“ライバル検索”(同位語検索)と呼ばれる研究では「与えられた単語の前後に“や”を付けて検索し、文章中で対になる語彙を集計する」というアイデアがある。これは「フェラーリやランボルギーニ」、「ポルシェやランボルギーニ」などと対になって登場する頻度が高いという推測のもとに考えられたアイデアというが、実際に既存検索サービスのインデックスを用いて8割程度は正しい答えを返すことが分かっているという。こうしたアイデアを検証するのに必要な準備はSloth Libを使うことで大幅に削減されるとう。
大島氏が作成したもう1つライブラリ「EaRDB」は検索サービスの結果をデータベースのテーブルのように扱えるようにするソフトウェアだ。EaRDBでは検索結果を仮想的なテーブルとして定義する。このテーブルに対してSQL文を発行することで、既存の検索サービスのインデックスに対して先のライバル検索を行ったり、「浅間山の標高」「渋谷の典型的な印象」を調べるといったことができるのだという。「集合を扱うデータベースとWebのランキングの再構成とは相性がいい」(大島氏)といい、これらのSQLは数行から十数行程度で済むという。
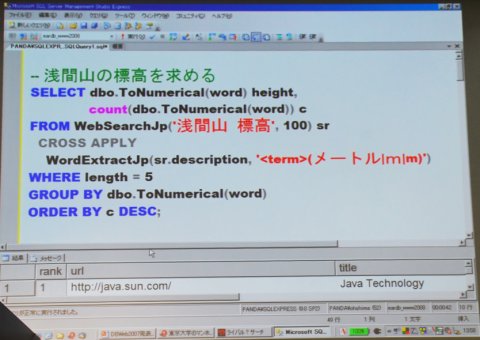 EaRDBを使って浅間山の標高を求めるSQL文。既存の検索サービスのインデックスを活用している
EaRDBを使って浅間山の標高を求めるSQL文。既存の検索サービスのインデックスを活用しているトラスト指向サーチはビジネスとしても成立の可能性
前出の田中氏は、こうした既存検索サービスに対して付加価値を提供する次世代検索サービスの別の方向性として、「信用度が1つのキーになる」と見ているという。「今や検索エンジンは老若男女、誰もが使う情報基盤。その一方、検索結果に対する信頼性を判断できる情報を検索エンジンは出していない」(田中氏)。
現在多くのユーザーは検索結果に多かれ少なかれ満足している。しかし実際には、例えば「黄疸のかゆみにはシジミの煮汁が効く」といった科学的根拠のないページがトップ10内に表示されるなど信憑性の低い情報も多く混ざる。そうしたノイズに自覚的ではないユーザーが多いことも、次世代検索サービスが必要な理由だ。米国で行われたある調査ではページランキングのような検索アルゴリズムを理解しているユーザーは皆無で、約2割のユーザーが「検索ランキングは検索サービス会社に対して支払われた金額に依存する」と回答するなど、ランキングの特性が理解されているとは言い難いという。そうしたことからも田中氏は「トラスト指向サーチというジャンルはビジネスとして成立する可能性があると思っている」のだと話す。
関連記事
情報をお寄せください:
最新記事
アイティメディアの提供サービス
キャリアアップ
転職/派遣情報を探す


「ITmedia マーケティング」新着記事
「サイト内検索」&「ライブチャット」売れ筋TOP5(2025年5月)
今週は、サイト内検索ツールとライブチャットの国内売れ筋TOP5をそれぞれ紹介します。
「ECプラットフォーム」売れ筋TOP10(2025年5月)
今週は、ECプラットフォーム製品(ECサイト構築ツール)の国内売れ筋TOP10を紹介します。
「パーソナライゼーション」&「A/Bテスト」ツール売れ筋TOP5(2025年5月)
今週は、パーソナライゼーション製品と「A/Bテスト」ツールの国内売れ筋各TOP5を紹介し...
著作権はアイティメディア株式会社またはその記事の筆者に属します。(著作権について)
当サイトに掲載されている記事や画像などの無断転載を禁止します。
「@IT」「@IT自分戦略研究所」「@IT情報マネジメント」「JOB@IT」「@ITハイブックス」「ITmedia」は、アイティメディア株式会社の登録商標です。
当サイトに関するお問い合わせは「@ITへのお問い合わせ」をご覧ください。