Loading
|
@IT|@IT自分戦略研究所|QA@IT|イベントカレンダー+ログ | |
|
Loading
|

|
| @IT > テキスト・マイニングに活用されるClementine |
| |
|
|
|
|
去る2001年9月14日、第一回Clementineユーザー会「CLUG Japan 2001」(SPSS株式会社主催)が開催された。今回は、多種多彩なプログラムの中から、特別講演「テキスト・マイニングとClementine:ブランド連想データの分析」の発表内容に、講師を務めた豊田裕貴氏(法政大学大学院 社会科学研究科)との個別インタビューの内容を加えたものをベースに、「テキスト・マイニング」の概要とClementineによるテキスト・マイニングの特徴を解説する。
まず、「テキストデータ」だが、文章や単語・句など、デジタル化された文字のことを指す。一般に、データマイニングでは定型的な数値データ(POSデータなど)を扱い、テキストデータは分析対象としない。それは、テキストデータは本来、非定型であいまいなため、分析対象としては扱いにくかったからだ。したがって、テキストデータについては、主に手作業による集計・分析が行われてきており、統計解析ツールやデータマイニングツールを活用した分析はあまり実施されていない。
次に「データマイニング」だが、これは当サイトで連載している「マーケターのためのデータマイニング講座」第1章でも解説されているように、仮説構築に役立つ、新たな知見の発見が狙いである。つまり、仮説の検証を目的とするデータ分析ではなく、大量のデータに潜んでいる思いもしなかったデータの関係性や意味を発掘(発見)するために、さまざまな角度からデータを検討することである。
したがって、「テキスト・マイニング」を上記の説明を元に分かりやすく言い換えると、「大量の文章や文字・句に埋もれている関係性を発掘することで、仮説構築のための新たな知見を得る分析手法」となるだろう。
さて、実務上、最もテキスト・マイニングへ関心を寄せている業界はマーケティング関連の業界である。なぜなら、さまざまな自由回答をはじめ、アンケート調査などで蓄積されたテキストデータの処理に長年頭を悩ませてきたからだ。また、最近多くの企業では、従来のアンケート調査に加え、お客様相談窓口、すなわちコールセンターから、消費者の生の声を得ようとテキストデータをデジタルデータ化して蓄積している。企業は、この膨大なデータをテキスト・マイニングによって分析することで、さまざまな問い合わせに対して的確な回答を迅速に返す仕組みを構築したり、新たな商品開発のヒントを得ることを狙っているのである。
そもそも、インターネットを核としたIT化の進展により、あらゆる資料がデジタル化・データベース化されつつあるいま、テキスト・マイニングは、さまざまな業界・研究分野に適用可能な、汎用的な分析技術として期待されているのである。
テキスト・マイニングが注目されてきた背景には、文章作成に原稿用紙を使わず、最初からワープロを使用するのが当たり前となったエンドユーザー・コンピューティングの本格到来と、Webやメールなどインターネットの普及によって、あらゆるデータがデジタル化されネット上に存在していることがある。もし、紙に印刷されただけの文章を分析しようと思ったら、まずデジタル化しなければならない。それには当然ながら費用がかかる。しかし、分析のための下処理にしか過ぎないテキストのデジタル化に高額な費用を計上するのは、現実的ではなかった。ところが、現在はあらゆる種類のデジタルデータが容易に入手・保存できる。分析者にとっては、宝の山に囲まれている状態だと言ってよいかもしれない。
また同時に、テキストを分析するために必要なツールの進歩も見逃せない。日本語の場合、英語のように単語ごとにスペースで区切られていない。したがって、分析する前に、文章を名詞や形容詞、助詞といった要素に分解する必要性がある。この技術は「形態素解析」と呼ばれ、言語学の分野で研究・開発されてきたものである。例えば、「キリンの一番搾りはうまい」という文章は、形態素解析にかけると、次のように分解、すなわち“分かち書き”される。
この形態素解析での研究成果が広く公開されるようになり、まだまだ完璧とは言えないまでも、実用に十分耐えうるレベルの環境を容易に利用できるようになってきている。すなわち、テキスト・マイニングのための第一関門である、「テキストデータの分解(分かち書き)」をようやくクリアできるようになったのである。さらに、データマイニングの分野では、ニューラルネットワークをはじめとする人工知能をベースとする分析技術が進展し、文字のようなあいまいなデータの処理が得意なツールが充実してきている。
このように、昨今テキスト・マイニングが脚光を浴び、あたかもブームのような様相を呈しているのは、まさに分析の対象であるデータのデジタル化の進展と、その分析に適したデータマイニング技術の進展という、2つの条件が揃ったからであろう。
さて、現在のところ、Clementineでテキスト・マイニングを実現するための方法については、次のとおりである。
SPSSでは、テキストデータの分解、すなわち形態素解析ツールとして、奈良先端科学技術大学院大学が開発した「茶筌」(ChaSen)というフリーソフトの使用を推奨する。豊田氏によると、解析の精度が高いことに加え、辞書への単語登録も容易であること、また処理速度が速いなどフリーソフトとはいえ、非常に優れたツールだそうだ。
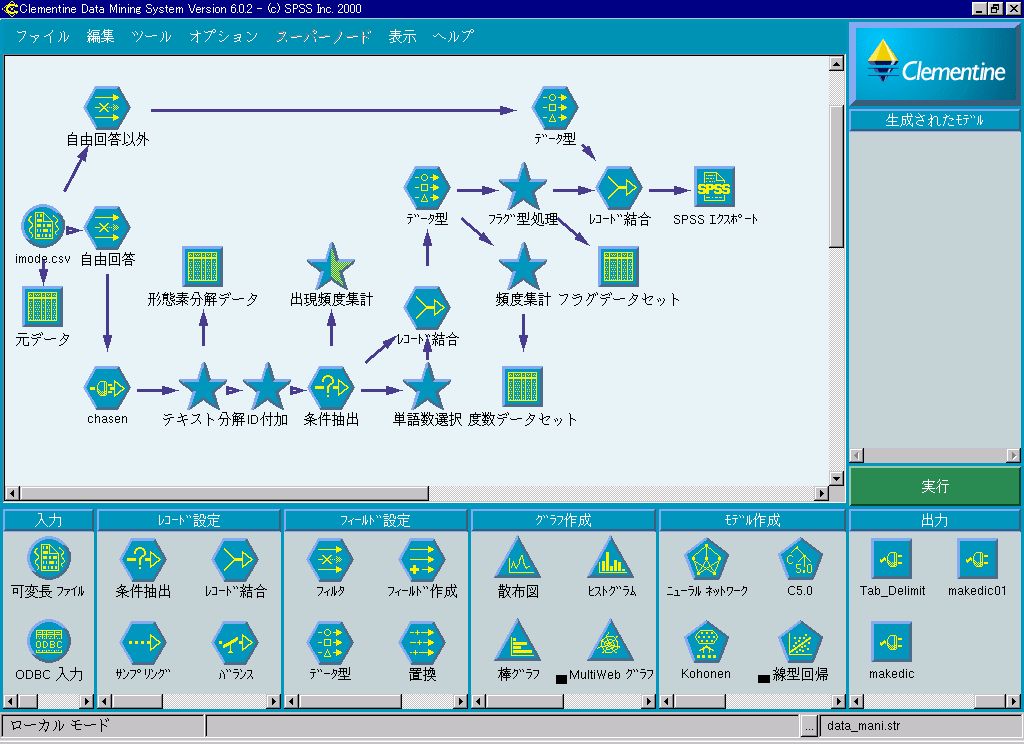
そして、Clementine6.0では、外部ツールの処理を一連の分析フローに取り込むためのインターフェイスCEMI(Clementine
External Module Interface)が実装されているため、Clementineの操作画面の中で、「茶筌」でのデータ処理も含む、テキスト・マイニングの分析プロセスを一気通貫で組むことができる。テキスト・マイニングだからといって、慣れないまったく別のツールを操作する必要性がなく、Clementine自体が持つメリットをそのまま享受することができるのである。
実際、Clementine+茶筌の組み合わせで、さまざまなテキスト・マイニングを実践している豊田氏は、次のようなメリットを指摘している。
●操作性の高さ
●豊富な分析手法を使える分析自由度の高さ
●ユーザー負担の軽さ
●ストリームの変更による拡張性の高さ
CLUG当日に、豊田氏の講演で紹介された、Clementine+茶筌によるテキスト・マイニングの解析例を簡単に紹介しよう。調査対象者に対していくつかのブランドの名前を見せ、そのブランド名から連想する言葉を自由回答で記入してもらった部分をテキスト・マイニングした結果である。 例えば、携帯電話の「i-mode」というブランドで連想された言葉から、茶筌を用いて単語を抽出した後、Clementineで分析する。その結果、「広末涼子」「田村正和」というタレント名や「Docomo」というブランド名を主に挙げた回答者群と、「便利」「高い」「メール」といったi-modeを経験することによって得られる評価や機能面を主に挙げた回答者群という、2つの特徴的なグループを抽出することができたという。これは、ブランドイメージの形成特徴として、広告やブランドそのもののイメージを優先する層と、経験・評価といった価値判断を伴ったイメージを優先する層の存在を示唆するものであり、広告戦略などに活用できる可能性を示している。 ※ブランド連想による広告効果測定に関する研究は、豊田氏がすでに2001年夏、小川孔輔教授(法政大学)と共同で日本マーケティングサイエンス学会に発表している。
豊田氏によれば、テキスト・マイニング技術・ツールの更なる向上のためには、次の2点が必要であると言う。 ●テキスト処理上のノウハウのフィードバック
●導入される分野の研究者や実務家の専門知識のフィードバック
テキスト・マイニングは、非定型なテキストを扱うだけに分析の自動化は困難である。むしろ、数値データの分析以上に分析者のビジネスセンスが要求される。その意味では、データマイニングツールは、テキスト・マイニングを実施する分析者を支援するためのツールとして、さらに使い勝手のよいツールとして進化していかなければならないのである。
Clementineは、テキスト・マイニング機能を組み込むことで、数値データだけでなくテキストデータをも分析できるようになった。Clementineの操作性の高いユーザーインターフェイスを通じて、企業内のあらゆるデータがハンドリングできるのである。したがって、Clementineは、さらに使い勝手のよいデータマイニングツールへとまさに進化したといえるだろう。
データマイニング・ツールに関するアンケートにお答えください |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||