XSLTでXMLデータの構造変換を記述するためには、XMLデータ中の特定の要素や属性を指定するための言語が必要になります。その用途のためXSLTとともにW3C勧告となったのが、XPath(XML Path Language)です。XSLTのスタイルシートを作成するうえでXPathは必須の知識ですので、今回はXPathによる初歩的な指定方法を述べることにします。
XMLデータはツリー構造である
今回は、以下のXMLデータを使ってXPathを解説します。
<?xml version="1.0"?> <publications> <book>標準XML完全解説</book> <magazine>Digital Xpress</magazine> <book>SGMLの書き方</book> </publications>
XPathのデータモデルによれば、XMLデータはツリーで表現されます。例として挙げたXMLデータは、次の図に示すツリー構造であると見なされます。
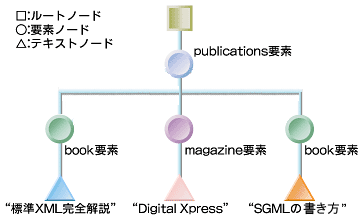
前回「XSLTスタイルシートの基礎の基礎」で述べたとおり、XPathのデータモデルではXMLデータ中の最上位要素の上にもう1つ親ノードがあると考え、それをルートノードと呼びます。XPath文法によるとルートノードは、特別な記号“/”で指定します。次のXSLT要素は、ルートノードにテンプレートを適用しなさいという意味になります。
<xsl:template match="/"> …… </template>
XPathの書き方の基本
では、基本的なXPathの記述ルールと、XSLTのテンプレート内での記述例を示していきましょう。
■親子関係は“/”で表す
図では、ルートノードの下にpublications要素とbook要素とmagazine要素という3種類の要素ノードが階層構造を作ってぶらさがっています。ノード同士の親子関係は、記号“/”で親要素・子要素を連結して表現します。publications要素の子要素bookにテンプレートを適用したい場合、XPathを使って次のように書きます。
<xsl:template match="publications/book"> …… </xsl:template>
■先祖と子孫は“//”で連結
ある要素の子孫要素にテンプレートルールを適用したい場合もあります。その場合、XPathでは記号“//”で先祖要素と子孫要素を連結して表現します。例えばpublications要素に子要素bookが、またbook要素に子要素priceがあるとします。publications要素の子孫要素となるすべてのprice要素にテンプレートルールを適用する場合、次のように書きます。
<xsl:template match="publications//price"> …… </xsl:template>
■テキストノードを取り出すtext( )
XML1.0文法では、開始タグと終了タグで囲まれた部分を要素の内容といいます。
<book>標準XML完全解説</book>
一方、XPathでは要素の内容は、その要素ノードにつながるテキストノードであると考えます。XPathでは、ある要素の子テキストノードを明示的に選択するにはtext( )という記述を用います。従ってbook要素の子テキストノードの値を取り出す場合、以下のように書きます。
<xsl:value-of select="book/text()"/>
もっとも次のように書いてもXSLTプロセッサはbook要素の値として子テキストノードの文字列を返しますので、同じ結果になります。
<xsl:valu-of select="book"/>
■カレントノードは“.”
XSLTプロセッサが現在処理しているノードをカレントノードといい、XPathでは“.”と表現します。カレントノードの子テキストノードを取り出す場合、次のように表現できます。
<xsl:value-of select="."/>
XPathのデータモデルでは、要素内で指定された属性をノードの一種と考え、属性ノードと呼んでいます。属性ノードとその属性を持つ要素ノードの関係は、従属関係にあるといい、要素ノードの親子関係とは別の扱いになります。
XPathには、ほかにも名前空間ノード、処理命令ノード、コメントノードがあります。詳細はW3CによるXPathの仕様書などを参照してください。
演算子や関数を使ってノードを指定する
■XPathの演算子
XPathには演算子や関数が数多く用意されていますので、演算子や関数を組み合わせて使うとより細かい指定を行うことができるので便利です。XPathの演算子を以下に示します。
| 比較演算子 | = != < > <= >= |
|---|---|
| 算術演算子 | + - * div mod |
| 論理演算子 | and or |
使用にあたっての注意点ですが、比較演算子“<”と“>”は、XMLではタグの開始と終了を表しています。そこで、XPathで使用する際はエンティティ参照(実体参照)の“<”と“>”を使用し、置換する必要があります。
■XPathのノード集合関数
XPathには、ノード集合関数、文字列関数、ブール関数、数値関数が用意されています。関数の例としてノード集合関数の一部を以下に示します。
| position() | 指定されたノード集合の中のそれぞれの位置を返す。 |
|---|---|
| last() | 指定されたノード集合の最後のノードの位置を返す。 |
| count() | 指定されたノード集合のサイズを返す。 |
上記の関数を使うと、同一階層で同一要素名を持つものの中から特定の要素だけを指定することができます。例えば、いくつか並んでいるbook要素の中から2番目のbook要素だけを処理するように指定したい場合、XPathの関数position()を使って以下のように書きます。
<xsl:template match="book[position()=2]"/>
便利な関数はほかにもたくさんありますが、個々の関数についてはXPathの仕様書などを参照してください。
属性に注目して処理するノードを選択する
要素が持つ属性に注目し、特定の属性値を持つノードだけを選択することができます。以下のようにbook要素が属性attを持つXMLデータをXSLT処理する場合を考えてみましょう。
<?xml version="1.0" encoding="shift_jis"?> <publications> <book att="XML">標準XML完全解説</book> <book att="SGML">SGMLの書き方</book> <book att="DTP">FrameMaker6.0パーフェクト ガイド</book> </publications>
属性名の前に“@”を付けることにより、属性値をXPathの中で参照することができます。次の例ではatt属性の値が“SGML”の要素(2番目のbook要素)だけを選択しています。
<xsl:template match="book[@att='SGML']"/>
さて、ここまででXSLTの概要とスタイルシートの基本的な書き方を解説しました。次回からは、XSLTのプログラミング的な側面を解説して、XSLTでどんなことができるのか、読者にイメージをつかんでいただこうと思います。
本記事は、日本ユニテック発行のXMLテクノロジー総合情報誌「Digital Xpress」に掲載された、XSLT特集「XSLTの実力を探る!」第1回から第3回の内容をもとに、加筆修正したものです。
Copyright © ITmedia, Inc. All Rights Reserved.