第21章 ポインタを使用できる「安全でないコード」:連載 改訂版 C#入門(3/4 ページ)
連載最終回となる今回は、C#におけるポインタの利用について解説する。ポインタのサポートにより、C#では低レベルな処理も効率よく行うことができる。
21-6 ポインタのサイズ
ポインタには、++や--演算子が利用できるが、その際、変化する量はデータ型によって異なる。データ型によって占有するサイズが異なるので、++演算子で次のデータに進めたとき、進む量を変化させる必要があるためだ。List 21-6は具体的なサイズを、sizeof演算子で調べるサンプル・ソースだ。
1: using System;
2: using System.Runtime.InteropServices;
3:
4: namespace Sample006
5: {
6: [StructLayout(LayoutKind.Sequential,Pack=1)]
7: struct SampleStruct1
8: {
9: public int x;
10: public sbyte y;
11: }
12: [StructLayout(LayoutKind.Sequential,Pack=2)]
13: struct SampleStruct2
14: {
15: public int x;
16: public sbyte y;
17: }
18: [StructLayout(LayoutKind.Sequential,Pack=4)]
19: struct SampleStruct3
20: {
21: public int x;
22: public sbyte y;
23: }
24: class Class1
25: {
26: unsafe static void test()
27: {
28: Console.WriteLine( sizeof(int) );
29: Console.WriteLine( sizeof(short) );
30: Console.WriteLine( sizeof(sbyte) );
31: Console.WriteLine( sizeof(SampleStruct1) );
32: Console.WriteLine( sizeof(SampleStruct2) );
33: Console.WriteLine( sizeof(SampleStruct3) );
34: }
35: [STAThread]
36: static void Main(string[] args)
37: {
38: test();
39: }
40: }
41: }
これを実行するとFig.21-7のようになる。

Fig.21-7の最初の3行は簡単に分かるだろう。intのサイズは4バイト、shortのサイズは2バイト、sbyteのサイズは1バイトであることを示している。つまり、++演算子で、int型のポインタなら4個進む、というわけだ。問題は後半の3つの数値だろう。これは、すべて同じ内容の3つのstructのサイズを表示しているが、すべて結果が異なっている。これは、StructLayout属性のPack引数の指定により変化したものだ。Pack引数は、メンバの値を配置する単位を指定する。「Pack=4」なら4バイトごとに整列させられるので1バイトで済むsbyteも、4バイト分の場所を占有してしまい、構造体全体では8バイト消費してしまっている。一方、「Pack=1」なら1バイトごとに配列するので、単純にint型(4バイト)とsbyte型(1バイト)で計5バイトという結果になるわけである。
21-7 ポインタを演算する
ポインタに使用できるのは++や--演算子だけではない。四則演算や==などの比較演算子も使用できる。List 21-7はポインタの引き算を、データ型を変えながら実行してみたサンプル・ソースである。
1: using System;
2:
3: namespace Sample007
4: {
5: class Class1
6: {
7: unsafe static void test()
8: {
9: int [] array = { 1,2,3,4 };
10: fixed( int * p1 = &array[0] )
11: {
12: fixed( int * p2 = &array[3] )
13: {
14: Console.WriteLine( p2-p1 );
15:
16: short * p3 = (short *)p1;
17: short * p4 = (short *)p2;
18: Console.WriteLine( p4-p3 );
19:
20: sbyte * p5 = (sbyte *)p1;
21: sbyte * p6 = (sbyte *)p2;
22: Console.WriteLine( p6-p5 );
23: }
24: }
25: }
26: [STAThread]
27: static void Main(string[] args)
28: {
29: test();
30: }
31: }
32: }
これを実行するとFig.21-8のようになる。
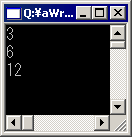
14行目では、int型のポインタとして引き算している。18行目では全く同じ値を、データ型だけshortへのポインタに変換した上で計算している。22行目では同様にsbyte型で行っている。結果は見てのとおりで、ポインタのサイズを意識した結果、異なる数値が出力されていることが分かるだろう。つまり、p1とp2の間には、int型なら3個分、short型なら6個分、sbyte型なら12個分の隙間があるということが示されているわけである。
21-8 一時変数を容易に確保するstackalloc
通常、量の多いデータを扱う場合は配列などを確保するが、配列は移動可能変数であるため、ポインタ利用が面倒になる。しかし、スタック上に配列のようなサイズの大きなデータを確保できれば扱いやすい。そのために、C#ではstackallocというキーワードが用意されている。これはC言語のallocaのようなものといえる。List 21-8はそれを使用した例である。
1: using System;
2:
3: namespace Sample008
4: {
5: class Class1
6: {
7: [STAThread]
8: static void Main(string[] args)
9: {
10: unsafe
11: {
12: int * buffer = stackalloc int[4];
13: for( int i=0; i<4; i++ )
14: {
15: *(buffer + i) = i;
16: }
17: for( int i=0; i<4; i++ )
18: {
19: Console.WriteLine( buffer[i] );
20: }
21: }
22: }
23: }
24: }
これを実行するとFig.21-9のようになる。
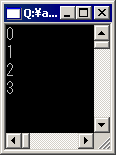
このように、配列でありながらfixedステートメントなしで処理できることが分かると思う。なお、ここでは2つ確認しておきたいことがある。1つは15行目である。このようなポインタを用いた式を使って配列にアクセスすることは、もちろん可能である。もう1つは、10行目から21行目までのunsafeブロックである。unsafeキーワードはメソッドなどに付けるだけでなく、ブロックを構成する使い方もできる。メソッドの一部だけで「安全でないコード」を使用する場合は、このようなunsafeブロックを使った方が安全だろう。
なお、stackallocしたメモリは、そのブロックを抜けると解放されてしまう。あくまでローカルな存在であることに注意が必要だ。stackallocしたメモリへの参照を戻り値で戻すような使い方はできない。
Copyright© Digital Advantage Corp. All Rights Reserved.