パーティショニングは大規模DBの性能向上に効く:Oracleパーティショニング実践講座(1)(3/3 ページ)
本連載では、大規模データベースでのパフォーマンス・チューニングの手法として、Oracleパーティショニングを解説する。単なる機能説明にとどまらず、実機による検証結果を加えて、より実践的な内容をお届けする。(編集部)
パーティショニングの種類
パーティショニングにはいくつかの種類があり、Oracleではデータの特性に合わせ、柔軟にパーティションの種類を選択できます。
パーティションを決定する際、重要となるポイントは次の3つです。
a. アプリケーションの特性
発行されるSQLのWHERE句条件に指定される列が、パーティションの分割方法に使用した列を指定するようになっているか
b. テーブル構成
パーティションの分割方法・用途に適するような列が存在するか
c. データの運用管理
データのサイクルや更新パターン(5年間のデータを保持し過去1年間を更新対象のデータとする、など)の洗い出し独立したメンテナンス管理操作が有効なシステムかどうか
これら3つのポイントを照らし合わせたうえで、最適なパーティションの種類を検討します。
パーティショニングではパーティション・キーと呼ばれる、データを分割する際に基準となる列を設定します。パーティション・キーに設定した列の値をどのような方法で各パーティションに振り分けるかによって、表3のような「レンジ」「リスト」「ハッシュ」「コンポジット」の種類が決まります。
| 種類 | 分割方法 | 用途 |
|---|---|---|
| レンジ | データを期間、範囲で分割 | 売り上げデータ、ログデータなど時系列にデータが生成され、年、四半期、月など、日付を条件にアクセスされる場合に有効 例:売上日など日付データで分割 |
| リスト | 「任意の値リスト」を指定することでデータを分割 | 国、地域、都道府県など不連続な値を持つデータの集合を、自然な方法でグループ化し、任意のパーティションに格納する場合に有効 例:東北、関東、中部など地域のパーティションに所属する都道府県のデータを分割 |
| ハッシュ | ハッシュ関数を使用し、データを均一に分割 | レンジ、リスト化できない不連続なデータを均一に分割する場合に有効 例:顧客番号、商品番号などでデータを分割 |
| コンポジット | レンジ+ハッシュまたはレンジ+リストの組み合わせ | レンジで分割した後、より細かい単位に分割する場合に有効 例:売り上げデータを週(レンジ)、製品番号(ハッシュ)で分割することで、週ごとの製品売り上げを把握するアプリケーションに有効 |
| 表3 パーティショニングの種類 | ||
上記4タイプに分類されるパーティショニングの特徴について、それぞれ確認してみましょう。
レンジ・パーティション
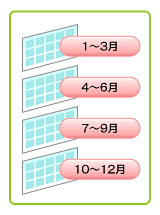
レンジ・パーティションでは、各パーティションに設定したパーティション・キー値の範囲や期間に基づいて、データを各パーティションに分割します(図10)。これは最も一般的なタイプのパーティション化で、多くの場合日付データとともに使用されます。例えば、売り上げデータ、ログデータなど時系列にデータが生成され、年、四半期、月など、日付を条件にアクセスされる場合に有効です。
リスト1に、sales_date列でレンジ・パーティション化される表sales_rangeを作成する例を示します。
CREATE TABLE sales_range
(salesman_id NUMBER(5) ,
salesman_name VARCHAR2(30),
sales_amount NUMBER(10) ,
sales_date DATE
)PARTITION BY RANGE(sales_date)
(PARTITION p2006q1 VALUES LESS THAN(TO_DATE('2006-04-01',
'YYYY-MM-DD')),
PARTITION p2006q2 VALUES LESS THAN(TO_DATE('2006-07-01',
'YYYY-MM-DD')),
PARTITION p2006q3 VALUES LESS THAN(TO_DATE('2006-10-01',
'YYYY-MM-DD')),
PARTITION p2006q4 VALUES LESS THAN(TO_DATE('2007-01-01',
'YYYY-MM-DD')));
リスト・パーティション
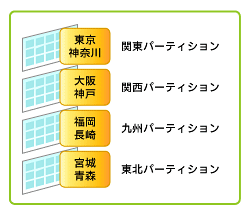
リスト・パーティションでは、各パーティションへ分割する値を明示的に指定します(図11)。国、地域、都道府県など不連続な値を持つデータの集合を、自然な方法でグループ化し、任意のパーティションに格納する場合に有効です。例えば、売り上げデータを東北、関東、中部など地域単位でアクセスする場合に、都道府県のデータを地域に分割する場合に採用します。表がリスト・パーティション化される場合、パーティション・キーに使用できるのは表の1列のみです。
リスト2に、sales_state列でリスト・パーティション化される表sales_listを作成する例を示します。
CREATE TABLE sales_list
(salesman_id NUMBER(5) ,
salesman_name VARCHAR2(30),
sales_state VARCHAR2(20) ,
sales_amount NUMBER(10) ,
sales_date DATE
)PARTITION BY LIST(sales_state)
(PARTITION sales_kanto VALUES('Kanagawa','Tokyo'),
PARTITION sales_kansai VALUES('Osaka','Kobe'),
PARTITION sales_kyusyu VALUES('Fukuoka','Nagasaki'),
PARTITION sales_tohoku VALUES('Miyagi','Aomori'));
ハッシュ・パーティション
ハッシュ・パーティションでは、パーティション・キー値にOracleのハッシング・アルゴリズムを適用し、データをパーティションにマッピングします(図12)。ハッシング・アルゴリズムにより各行がパーティション間で均等に分散されるため、パーティションはほぼ同一サイズになります。レンジ、リスト化できない不連続なデータを均一に分割する場合に有効です。例えば、顧客番号、商品番号などでの分配はOracle内部のハッシュ関数の特性に依存しますので、データが特定のパーティションに偏るのを防止するために、パーティション数を2の累乗(2、4、8など)で定義する必要があります。

リスト3に、salesman_id列でハッシュ・パーティション化される表sales_hashを作成する例を示します。
CREATE TABLE sales_hash (salesman_id NUMBER(5) , salesman_name VARCHAR2(30), sales_amount NUMBER(10) , week_no NUMBER(2) )PARTITION BY HASH(salesman_id) PARTITIONS 4;
コンポジット・パーティション
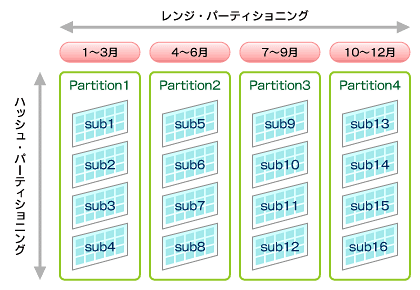
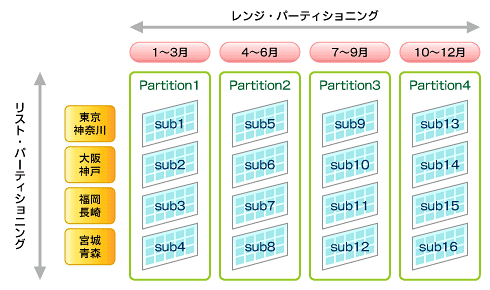
コンポジット・パーティションでは、データはレンジ方式でパーティション化されてから、各パーティション内でハッシュまたはリスト方式で再分割されます。レンジで分割した後、より細かい単位に分割する場合に有効です。
例えば、売り上げデータを週(レンジ)、製品番号(ハッシュ)で分割することで、週ごとの製品売り上げを把握するアプリケーションで効果的に利用できます(図13、図14)。
リスト4に、レンジ−ハッシュ・コンポジット・パーティション表を作成する例を示します。
CREATE TABLE sales_composite
(salesman_id number(5) ,
salesman_name varchar2(30),
sales_amount number(10) ,
sales_date date
)PARTITION BY RANGE(sales_date)
SUBPARTITION BY HASH(salesman_id)
SUBPARTITIONS 4
(PARTITION p2006q1 VALUES LESS THAN(TO_DATE('2006-04-01',
'YYYY-MM-DD')),
PARTITION p2006q2 VALUES LESS THAN(TO_DATE('2006-07-01',
'YYYY-MM-DD')),
PARTITION p2006q3 VALUES LESS THAN(TO_DATE('2006-10-01',
'YYYY-MM-DD')),
PARTITION p2006q4 VALUES LESS THAN(TO_DATE('2007-01-01',
'YYYY-MM-DD')));
リスト5に、レンジ−リスト・コンポジット・パーティション表を作成する例を示します。
CREATE TABLE orders
(region VARCHAR2(10),
……… ,
odate DATE ,
)PARTITION BY RANGE(odate)
SUBPARTITION BY LIST(region)
(PARTITION p2006q1 VALUES LESS THAN(TO_DATE('2006-04-01',
'YYYY-MM-DD'))
(SUBPARTITION p2006q1_kanto VALUES('Kanagawa','Tokyo'),
SUBPARTITION p2006q1_kansai VALUES('Osaka','Kobe')),
SUBPARTITION p2006q1_kyusyu VALUES('Fukuoka','Nagasaki'),
SUBPARTITION p2006q1_tohoku VALUES('Miyagi','Aomori'))
PARTITION p2006q2 VALUES LESS THAN(TO_DATE(TO_DATE('2006-07-01',
'YYYY-MM-DD'))
(SUBPARTITION p2006q2_kanto VALUES('Kanagawa','Tokyo'),
SUBPARTITION p2006q2_kansai VALUES('Osaka','Kobe'),
SUBPARTITION p2006q2_kyusyu VALUES('Fukuoka','Nagasaki'),
SUBPARTITION p2006q2_tohoku VALUES('Miyagi','Aomori'))
PARTITION p2006q3 VALUES LESS THAN(TO_DATE(TO_DATE('2006-10-01',
'YYYY-MM-DD'))
(SUBPARTITION p2006q3_kanto VALUES('Kanagawa','Tokyo'),
SUBPARTITION p2006q3_kansai VALUES('Osaka','Kobe'),
SUBPARTITION p2006q3_kyusyu VALUES('Fukuoka','Nagasaki'),
SUBPARTITION p2003q3_tohoku VALUES('Miyagi','Aomori'))
PARTITION p2006q4 VALUES LESS THAN(TO_DATE(TO_DATE('2007-01-01',
'YYYY-MM-DD'))
(SUBPARTITION p2006q4_kanto VALUES('Kanagawa','Tokyo'),
SUBPARTITION p2006q4_kansai VALUES('Osaka','Kobe'),
SUBPARTITION p2006q4_kyusyu VALUES('Fukuoka','Nagasaki'),
SUBPARTITION p2006q4_tohoku VALUES('Miyagi','Aomori'))
);
パーティションの実装においては、どのような分割方法でパーティションを分割する場合でも、アプリケーションから発行されるSQLによって、どのような条件で条件付けされるかが最も重要なポイントです。特定のパーティションだけを参照するパーティション・プルーニングは、発行されるSQLのWHERE句の条件列にパーティションを分割するキーとなる列が含まれていないとなりません。
まとめ
連載第1回となる今回は、増え続けるデータへの対策としてパーティショニングの概要をご紹介しました。パーティションを実装する場合、期待どおりのパフォーマンス効果が得られるかどうか、カットオーバー後の運用管理において問題はないか、システムのカットオーバー前に稼働試験を行って、想定される運用に耐えられるものであるか判断をしておくことも重要です。
次回は、Oracleパーティショニング機能の実装ポイントを検証結果とともに説明します。
Copyright © ITmedia, Inc. All Rights Reserved.