パーティショニングとパラレル処理は最高の相性:Oracleパーティショニング実践講座(3)(1/4 ページ)
本連載では、大規模データベースでのパフォーマンス・チューニングの手法として、Oracleパーティショニングを解説する。単なる機能説明にとどまらず、実機による検証結果を加えて、より実践的な内容をお届けする。(編集部)
前回までは大規模データベースでパーティショニングを利用するメリットとして、パーティション・プルーニングによるアクセスデータの絞り込みがパフォーマンスを大きく向上させることを紹介しました。パーティショニングによるデータ分割はデータの絞り込みだけではなく、並列して処理を行ううえでも効果を発揮します。特にデータが大規模になればなるほど効果が得られるので、ぜひ活用してください。
なお、活用に当たってはその仕組みをきちんと理解する必要があり、考慮点や注意事項などの情報も押さえておかなければなりません。
本稿ではまず、パラレル処理の機能概要について、パーティショニングとの関連性や効果を中心に紹介していきます。
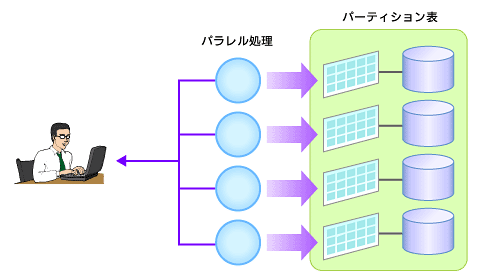 図1 パーティショニングとパラレル処理の相乗効果
図1 パーティショニングとパラレル処理の相乗効果パラレル処理とは?
パラレル処理とは、リクエストがあった処理要求(SQL)を複数のプロセスで同時に処理できるように作業を分割する概念です。通常は1つのプロセスですべての作業を実行しますが、多数のプロセスで作業を同時に実行できるようにタスクを分割して並列に処理します(図2)。
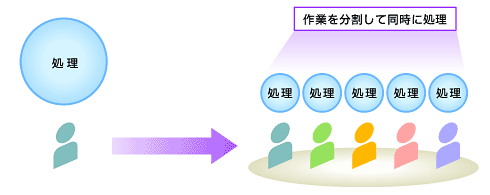 図2 パラレル処理の概念
図2 パラレル処理の概念パラレル化によって、以下の処理の高速化が期待できます。
- 大規模な表のスキャン、結合またはパーティション索引スキャンを要求する問い合わせ
- 大規模な索引の作成
- 大規模な表の作成(マテリアライズド・ビューを含む)
- 大量の挿入、更新および削除
パラレル処理とシリアル処理との違い
それでは通常のシリアル処理とパラレル処理の違いを、検索を例に確認してみましょう。シリアル処理では、ユーザー・プロセスからサーバ・プロセスに処理要求(SQL)が渡されると、サーバ・プロセスはバッファ・キャッシュ上にアクセスするデータが存在するかどうかを確認します。バッファ・キャッシュ上にデータが存在しない場合には、サーバ・プロセスがデータファイルから対象ブロックを読み込み、要求されているデータをユーザー・プロセスに返します(図3)。
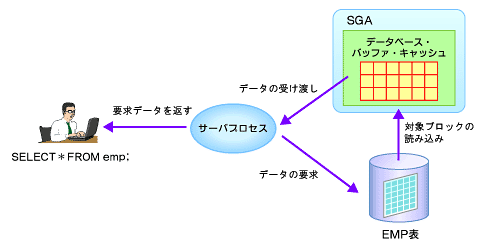 図3 シリアル処理の流れ
図3 シリアル処理の流れパラレル処理でもユーザー・プロセスからの処理要求(SQL)はサーバ・プロセスが受け取ります。ただ、パラレル処理ではサーバ・プロセスは「パラレル実行コーディネータ」という役割を果たします。パラレル実行コーディネータの役割として、SQL処理に必要な数のスレーブ・プロセス(パラレル実行サーバ)を起動し、処理を分割してパラレル実行サーバに割り当てます。各パラレル実行サーバは、それぞれ並行してデータファイルの読み込みなどを行って必要なデータを獲得し(シリアル処理と同様)、その結果をパラレル実行コーディネータに戻します。その後、パラレル実行コーディネータは要求されているデータをユーザー・プロセスに返します。
つまり、パラレル実行コーディネータの役割を果たすサーバ・プロセスが処理要求を複数のパラレル実行サーバに分配し、すべてのプロセスからの結果を調整してユーザー・プロセスに送り返すという流れです(図4)。
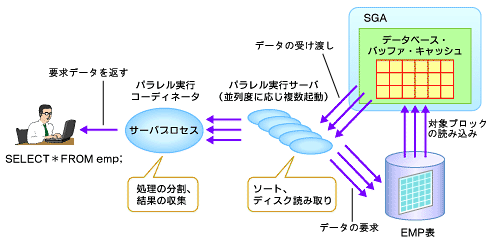 図4 パラレル処理の流れ
図4 パラレル処理の流れ各プロセスの役割
このようにパラレル処理はSQLの処理を複数のタスクに細分化するパラレル実行コーディネータと、各タスクを実行するパラレル実行サーバと呼ばれるプロセスで構成されています。
パラレル実行コーディネータ
- 処理要求を解析し、並列度を決定
- 1つまたは複数のスレーブ・セット(つまりパラレル実行サーバ)を割り当てる
- 問い合わせ処理要求(SQL)を制御し、手順をパラレル実行サーバに送信
- パラレル実行サーバでスキャンする必要がある表または索引を決定
- 最終出力をユーザーに対して生成
パラレル実行サーバ
- 分割された処理を実行(ディスク読み取り、ソート処理など)
それでは、パラレル実行コーディネータはどのように処理を分割し、パラレル実行サーバに処理を渡しているのでしょうか?
並列度
分割した処理を実施するパラレル実行サーバの数は並列度で決定されます。SQLの並列度はリスト1のようにSQLに並列度をヒント句で明示的に指定します。また、並列処理させたい表があらかじめ分かっている場合には、リスト2のように表定義に並列度を指定することもできます。
SELECT
/* + PARALLEL (emp, 4) */ * FROM emp; |
| リスト1 SQL文にヒント句で指定する 並列度は4、つまりパラレル実行サーバを4つ使って処理を行う。 |
CREATE TABLE sales_range |
| リスト2 表の定義で並列度8を指定 |
コラム:並列度に関する初期化パラメータ
並列度は本文のリスト1、リスト2のようにSQLにヒント句で指定したり、表の定義で指定しますが、実際にプロセスとして起動されるパラレル実行サーバの数は初期化パラメータで制御します。
インスタンス起動と同時に起動するパラレル実行サーバの数は「Parallel_Min_Servers」で、起動できる最大値は「Parallel_Max_Servers」で設定します。あらかじめ多くのプロセスを起動しておくとプロセスが使用するメモリなどのリソースをより多く必要としますし、少な過ぎるとパラレル処理のたびにプロセスの起動が必要となりオーバーヘッドが生じます。この初期値と最大値をうまく使って、システムに最適なパラレル実行サーバ数を起動しておくことが、チューニングの1つのポイントであるといえるでしょう。
Parallel_Max_Serversの目安は以下のような式になります。係数「2」の意味については3ページ目の「パラレルクエリ−インターオペレーション並列化」として後述します。
(使用する最大の並列度)×(パラレル実行の同時実行数)×2
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。