パーティショニングは大規模DBの性能向上に効く:Oracleパーティショニング実践講座(1)(1/3 ページ)
本連載では、大規模データベースでのパフォーマンス・チューニングの手法として、Oracleパーティショニングを解説する。単なる機能説明にとどまらず、実機による検証結果を加えて、より実践的な内容をお届けする。(編集部)
パーティショニングの必要性
今日、Oracleデータベースを取り巻く環境は、多種多様なユーザーのニーズに応えるべく進化しています。例えば、Webサーバのバックエンドとして使用されるデータベースでは、高い可用性を実現しながら、日々増加するデータに対し、多数のユーザーからの要求をレスポンスの遅延なく処理し、さらに、優れたメンテナンス性を提供するなど、ハードルの高い要件が求められています。
このような要件のデータベース・システムに対し、ハードウェア面ではここ数年、IAサーバを採用するケースが増加しています。IAサーバの64bit化やCPUの処理能力増大(マルチコア化)に伴いCPU処理能力が商用UNIX機と遜色なくなったことと、2003年以降、商用UNIXで実績のあるOracleの64bit版がLinuxとWindows向けに整備されたことで、コストメリットのあるIAサーバをミッション・クリティカルなシステムへ導入することが検討されています。
ミッション・クリティカルなシステムでは高い可用性、ユーザー数の増加に対応した拡張性が求められるため、Oracle Real Application Clusters(以下 RAC)を採用し、可用性と拡張性を高めたシステムをIAサーバで構築することも珍しくありません。IAサーバの適用範囲が広がる中で、日々増加するデータのメンテナンスやデータ増加に伴うパフォーマンス劣化が課題となっています。
本連載では6回にわたり、大規模データベース(VLDB:Very Large Data Base)の管理およびパフォーマンス改善において有効なOracle手法(データ分割、並列処理、データ圧縮)について、筆者の勤務するアシストで行った検証結果を交えながらご紹介します。
処理能力の向上に伴いデータ量は増加の一途
まず、本連載で紹介する手法や検証の対象となる「大規模データベース」の規模について簡単に補足します。アシストではセミナーにご参加いただいたお客さまを対象に、Oracleデータベースに関するさまざまなアンケートを実施していますが、その中で、データ量について質問した内容があるのでご覧ください(図1)。
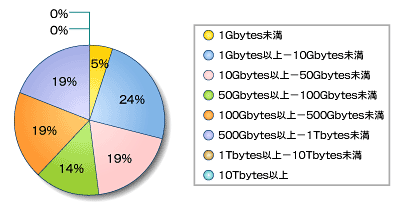 図1 Oracleデータベースに格納されるデータ量の傾向
図1 Oracleデータベースに格納されるデータ量の傾向十数年前には、図1のデータ量区分の最小である1Gbytes未満に含まれる500Mbytes程度のデータサイズで大規模といわれていました。5年前ぐらいには100Gbytes以上が、そして現在では1Tbytes以上が大規模データベースに該当するのではないでしょうか。現在では1Tbytes程度の中規模までは廉価で高性能なIAサーバで十分カバーできるようになってきています。
そのためアシストでは、コスト面などからお客さま企業において実現性の高いIAサーバでもカバーでき、その中でも規模の大きい100Gbytes以上1Tbytes未満をパーティショニングの検証対象としています。
データ量の増加にどう対応するか
図2は「格納データの増加に伴う課題」についてのアンケート結果です。これから、「ストレージの領域不足」「データ移行時間」のほか「更新系のバッチ処理遅延」「集計時間の遅延」「索引再作成、統計情報の再取得処理の遅延」など、データの増加に伴うパフォーマンス遅延やメンテナンス処理の遅延に関する項目が多いことが確認できます。
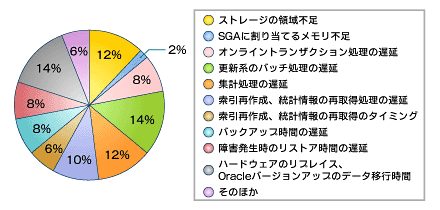 図2 格納データの増加に伴う課題
図2 格納データの増加に伴う課題データベースのデータ量増加に対する対応策は、「データ分割」「並行処理」と「データ圧縮」の大きく3つが挙げられます。データ分割にはパーティショニングと複数データベースにデータを分散する手法が、また、並行処理にはパラレル処理が、データ圧縮にはセグメントデータの圧縮という手法がそれぞれあります。本連載では1つ目のデータ分割の手法に焦点を絞って説明します。
データ分割手法ではパーティショニングが有効
先ほどデータ分割にはパーティショニングと複数データベースにデータを分散する手法があると述べましたが、簡単にそれぞれの特徴をご説明します。
パーティショニング
パーティショニングは、Oracle8から提供された機能で、アプリケーションからは1つの表として見えるデータを分割して管理する手法です。論理的に区分けしたものを「パーティション」と呼び、データの特性や利用目的に合わせて、期間や範囲といった論理単位でデータを分割できます。パーティション化のメリットはいくつかありますが、問い合わせのレスポンス向上もその1つです。
例えば、2002年から2006年までの5年分の売り上げデータを1つの表で管理していたとします(図3)。パーティション化していないと、2006年6月という特定月の情報を検索する場合でも表全体のデータが読み込まれるため、売上表が大きくなるほどレスポンスが劣化します。しかし、売り上げデータを売り上げ年や月ごとにパーティション化しておけば、特定月のデータを参照するだけでよくなるため、集計作業などのレスポンスが向上します。
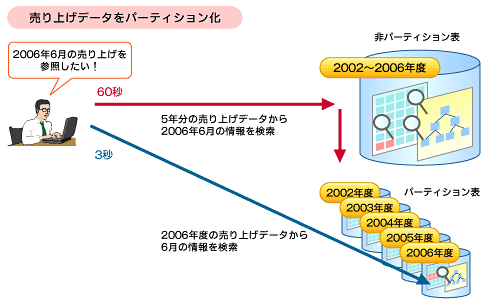 図3 パーティショニングのイメージ
図3 パーティショニングのイメージ複数データベースへのデータ分散
また、「複数データベースにデータを分散する」とは、複数のデータベースに物理的にデータを分散して格納することを意味します。例えば図4のように、会員500万人を管理するECサイトのデータベースであれば、会員50万人ごとにデータベースを10組構築することを意味しています。
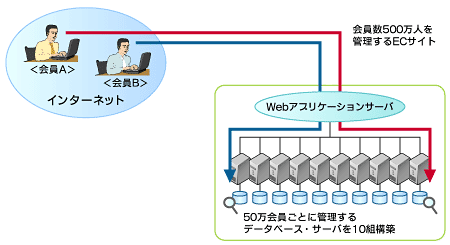 図4 複数データベースにデータを分散するイメージ
図4 複数データベースにデータを分散するイメージパフォーマンス、管理性などに優れるパーティショニング
ここで「パーティショニングを利用してデータを分散」する場合と「複数データベースにデータを分散」する場合の違いについて確認してみましょう(表1)。
| 複数データベースにデータを分散 | パーティショニングを利用してデータを分散 | |
|---|---|---|
| 特徴 | ・物理的にデータベース・サーバが分割されているため、1つのサーバの遅延がほかのサーバに影響を与えない ・サーバを追加することでデータの増加に対応できる ・1つのデータベースが破損しても、破損したデータベース以外は利用できるため可用性が高い |
・増加するデータのパーティション化によりパフォーマンスが向上 ・1つのパーティションが破損しても、破損したパーティション以外は利用できるため可用性が高い ・パーティション単位のデータ再編成、バックアップ、リカバリなどが可能であり、管理性やパフォーマンスに優れる ・1つのデータベースにデータを集約するため、管理コストが低い ・アプリケーションの修正が不要 |
| 制限事項 | ・複数データベースにデータが分散しているため、アプリケーション側でデータ参照先を振り分ける必要がある ・1つのデータベース・サーバで要件を許容できるデータ量が比較的少ないため、サーバを多数用意しなければならない ・複数データベースの管理が煩雑になるため、管理コストが高い ・複数データベースに重複したデータを持つ場合、整合性は保証されない |
・Oracle Enterprise Editionのオプションであるため、活用ノウハウが不足している |
| 表1 データ格納形式の特徴と制限事項 | ||
表1からは、複数データベースにデータを分散した場合と比べて、パーティショニングを利用することにより、アプリケーションの改修が不要で、パフォーマンス向上や管理性向上のメリットを享受できることが分かります。ただし、パーティショニングはOracle Enterprise Editionのオプション機能であるため、活用するためのノウハウが不足していることが懸念点だと考えられます。本連載では、検証結果などを織り交ぜながらパーティショニングの活用ノウハウを提示できればと思います。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。