WindowsのパフォーマンスモニタでCPUとディスクのロードアベレージを表示させる:Tech TIPS
Windows OSではロード・アベレージの値を表示させるコマンドは用意されていない。 ロード・アベレージの値を調べるには、パフォーマンス・モニタでProcessor Queue Lengthカウンタの値を調べる。ディスクのロード・アベレージはAvg. Disk Queue Lengthカウンタで得られる。

対象OS:Windows XP / Windows Vista / Windows 7 / Windows Server 2003 / Windows Server 2008 / Windows Server 2008 R2
解説
●「ロード・アベレージ」とは
UNIXやLinuxなどのOSでは、システムの負荷状態を表すために「ロード・アベレージ」という指標がよく使われる(日本語にすると「CPU負荷の平均値」)。uptimeやw、topなどのコマンドでその値を確認できる。

Ubuntu Linuxでのロード・アベレージの例
UNIXやLinuxでは、uptimeやw、topなどのコマンドでロード・アベレージの値を確認できる。3つの数値は、それぞれ過去1分間、5分間、15分間のロード・アベレージ値の平均値。
(1)これがロード・アベレージ値。
これらのコマンドでは3つの数値が表示されているが、それぞれ、過去1分間、5分間、15分間のロード・アベレージ値の平均を表している。この値をチェックすることにより、例えば1以下ならば(0にほとんど近ければ)システムの負荷が非常に軽いが、常態的に5とか10を超えるようだと負荷が高いのでなんらかの対策が必要だろう、といった判断ができる*1。
*1 実際にシステムの負荷やパフォーマンスを判断するには、これ以外の指標(カウンタ)なども考慮する必要がある。例えば計算主体のプロセスばかりでロード・アベレージが10なら大した問題ではないが、メモリ不足でスラッシング(仮想記憶のページ・インとページ・アウトが多発している状態)が起こっている状態でロード・アベレージが5なら、何らかの対策が必要だろう。ページングに関するパフォーマンス・カウンタやディスク/ネットワーク・デバイスに関するカウンタなども調査する必要がある。
ロード・アベレージ値は、OS内で現在実行可能な状態にあるプロセスの数(プロセスの実行待ちキューの長さ*2)を表している。例えば実行中のプロセスが10個あり、そのほかのプロセスはすべてウェイト状態(自発的なスリープやI/O完了待ち、イベント待ちなど、すぐには実行しない状態)にあれば、ロード・アベレージ値は10となる。ただし実行待ちプロセスの数というのは瞬間的な値なので、実際には過去1分や5分、15分といった間隔で平均値を求め、それが表示されている。
*2 正確にいえば、プロセス数ではなくスレッド数。1つのプロセスの中には複数のスレッドが含まれており、CPUのコアにはこのスレッドが1つずつ割り当てられ、実行される。ロード・アベレージの一般的な説明では実行待ちのプロセス数などと呼ばれているので、ここではプロセス数とする。なお、UNIXやLinuxのロード・アベレージでは、実行待ちのプロセスだけでなく、現在CPUコア上で実行中のプロセスも合算してロード・アベレージを計算するのが一般的なようだが、後述のWindows OSの「Processor Queue Length」カウンタでは、実行中のプロセスは除外されるので、少し値が低くなる。
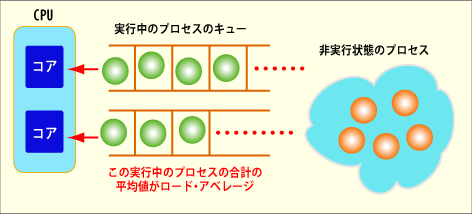
ロード・アベレージ
プロセス(スレッド)が生成されて実行可能状態になると、実行待ちの行列(キュー)に入れられる。プロセス・スケジューラは待ち行列から1つずつ取り出し、それをCPU(コア)に割り当て、実行を開始する。一定時間が経過したり、指示があると、実行を停止して、また待ち行列へ戻されたり、スリープしたりする。ロード・アベレージはこの実行可能状態になっていて、実行待ちキューに入っているプロセスの総数を一定時間ごとに平均した値である。実行可能状態ではないプロセス数は加算しない。なおコアごとの平均値ではないので、マルチコア/マルチプロセッサ・システムでは、ロード・アベレージが1を大きく超えていても、システム全体としての負荷は大きくない。
なお、このロード・アベレージは単純に実行待ちプロセスの数を表したものであり、CPUのコア数は考慮していない。そのため、例えばシングル・コアのシステムでロード・アベレージが5なら負荷が高いといえるが、16コアのシステムならば全体的なCPU使用率は約30%しかなく、十分余裕がある。コアごとの平均値(コア数で割った値)にしていないのは、単に歴史的な経緯からであろうが、この値について検討する場合は、コア数なども考慮する必要がある。
Windows OSではタスク・マネージャを使えばシステムの負荷を簡単に調べることができるが、ロード・アベレージ値を直接表示するコマンドやツールはない。だが、パフォーマンス・モニタを使ってプロセスの実行待ちキューの値を表示させれば、ロード・アベレージ・モニタとして利用できる。本TIPSでは、その方法について解説する。
●CPU使用率とロード・アベレージの違いについて
タスク・マネージャではCPU使用率(もしくはコアごとの使用率)が%で表示されているが、これはロード・アベレージとは異なる。CPU使用率は、CPUがある単位時間内にどの程度利用されているか(プロセスを実行しているか)を示すもので、0〜100%の値を取る。CPUが常にプロセスを実行していれば100%となるが、実行待ち行列がいくら長くても100%までしか表示されない*3。CPU使用率が常に100%になっているようなシステムは性能に余裕がないことを表しているが、さらにロード・アベレージ値を調査することにより、システムの負荷の傾向を把握できる。例えば1日のうち、数時間だけロード・アベレージ値が(コア当たりで換算して)5とか10になる程度なら問題は少ないが、ほぼ24時間ずっと大きな値を示しているようなら、負荷の軽減(分散)やシステムの増強などを考える必要があるだろう。
*3 CPU使用率とロード・アベレージを例えば現実の飲食店で例えると、「店内にいる客数÷席数」がCPU使用率で、「店内の客数+外で行列待ちしている客数」がロード・アベレージに相当する(行列は必ず店外で起こるものとする)。
操作方法
●ロード・アベレージ用のパフォーマンス・カウンタ
Windows OSにはロード・アベレージを簡単に確認するツールは用意されていないが、パフォーマンス・カウンタ(パフォーマンス・モニタ)で以下の項目を監視すれば、ロード・アベレージ値として利用できる。
| 指標 | カウンタ |
|---|---|
| CPUロード・アベレージ | 「System」オブジェクトの「Processor Queue Length」カウンタ。ただしUNIXやLinuxなどのロード・アベレージとは違い、実行中のプロセス数は数に含まれない。実行待ちのキューにあるプロセス数のみの合計となっている |
| ディスク・ロード・アベレージ | 「LogicalDisk(_Total)」か「PhysicalDisk(_Total)」オブジェクトの「Avg. Disk Queue Length」カウンタ。なお古いWindows OSではLogicalDiskカウンタの値を収集するためには、あらかじめコマンド・プロンプト上で「typeperf -y」か「typeperf -yv」を実行しておく必要がある。カウンタの値がずっと0ならばチェックすること。サポート技術情報の「How to Monitor Disk Performance with Performance Monitor」[英語]参照 |
| CPU使用率 | 「\Processor(_Total)」オブジェクトの「% Processor Time」カウンタ |
| ロード・アベレージに関するカウンタ これらの値をパフォーマンス・モニタで監視したり、定期的にログ取得したりすればよい。参考のために、CPU使用率のカウンタ(これは、タスク・マネージャのCPU使用率グラフで表示されている値)も示しておく。これらの値の分析方法などについては、以下のサイトなども参考にするとよい。 ・パフォーマンス データを分析する(TechNetサイト) | |
CPUロード・アベレージとは、冒頭で解説したロード・アベレージ値のことで、CPUの実行待ちキューの長さを表している。一般的にロード・アベレージといえば、これを指す。ただしUNIXのwコマンドなどと違い、瞬間的な値なので、ある程度の期間継続してモニタする必要がある。
ディスク・ロード・アベレージとは、ディスクに対する読み書きコマンドのキューの長さである。CPUのロード・アベレージと同様に、ディスクに対していくつの実行コマンドが待ち行列に入っているかを表している。この値が定常的に2とかそれ以上あると、実際にはずっとディスク入出力が行われ続けているということを表す(ディスク全体ではなく、個別のドライブごとにモニタすることも可能)。システムのパフォーマンスを改善するには、ディスクを高速化したり、複数のディスクにファイルを分散させたり、データ量を減らしたり、などの対策が必要だろう。
●コマンド・プロンプト上でのデータ収集
これらのカウンタの値を継続的にモニタすれば、システムの状態を把握できる。カウンタ値を収集するにはいくつか方法があるが、例えばコマンド・プロンプト上ならばtypeperfやlogmanコマンドが利用できる。typeperfはリアルタイムに収集して表示するコマンド、logmanはスケジュールに従って自動収集し、ログ化するコマンドである。具体的な操作方法はTIPS「typeperfコマンドでシステムのパフォーマンス・カウンタのデータを収集する」「パフォーマンス・カウンタのデータ収集をlogmanコマンドで制御する」を参照していただきたい。
typeperfを使うなら、例えば次のようにすると、カウンタの値が1秒おきに表示される。
C:\>typeperf "\System\Processor Queue Length" "\LogicalDisk(_Total)\Avg. Disk Queue Length" "Processor(_Total)\% Processor Time"
"(PDH-CSV 4.0)","\\WINDOWS7PC001\System\Processor Queue Length","\\WINDOWS7PC001\LogicalDisk(_Total)\Avg. Disk Queue Len
gth","\\WINDOWS7PC001\Processor(_Total)\% Processor Time"
"09/08/2010 15:09:03.957","1.000000","0.000499","100.000000"
"09/08/2010 15:09:04.960","4.000000","0.154328","100.000000"
"09/08/2010 15:09:05.962","6.000000","0.295397","100.000000"
"09/08/2010 15:09:06.969","6.000000","0.897966","100.000000"
"09/08/2010 15:09:07.976","5.000000","0.978750","100.000000"
"09/08/2010 15:09:08.980","5.000000","1.472725","100.000000"
……(以下省略)……
収集したデータは次のパフォーマンス・モニタなどで表示できる(TIPS「収集したカウンタ・データをパフォーマンス・モニタで表示させる」参照)。
●パフォーマンス・モニタでのデータ収集
GUI画面でデータを収集するには、[管理ツール]の[パフォーマンス]を起動し(もしくは[コンピュータの管理]ツールで、[システム ツール]−[パフォーマンス ログと警告])、これらのカウンタを追加する。このツールの使い方についてはTIPS「パフォーマンス・モニタの使い方(基本編)」やその関連TIPSを参照していただきたい。

パフォーマンス・カウンタの追加
これはWindows 7のパフォーマンス・モニタでロード・アベレージ用のカウンタを追加しているところ。
(1)これはディスク・ロード・アベレージ用のカウンタ・オブジェクト。
(2)インスタンスを選択する。ディスクごとに個別に収集することも可能。
(3)これをオンにすると、カウンタの説明が表示される。
(4)カウンタの説明。
(5)これをクリックすると追加される。
(6)追加したカウンタ。
表示されたグラフは次のようになる。なおカウンタ値の表示スケール(縦軸)が×10倍になっているので、100となっているところ(グラフの上限)は実際には10を表している。このグラフを何度も使うなら、データ・コレクタ・セットとして保存しておくか(Windows Vista以降の場合)、パフォーマンス・ツールの[ファイル]−[名前を付けて保存]で保存しておけばよい(Windows XP/Windows Server 2003の場合)。

ロード・アベレージの結果例
CPUとディスクのロード・アベレージの例。縦軸は×10倍になるようにスケールしているので、上端が10となっている。
(1)ディスク・ロード・アベレージ。
(2)CPUロード・アベレージ。
■更新履歴
【2010/09/11】Windows OSの「Processor Queue Length」カウンタには実行中のプロセス数は含まれないという記述を追加しました。
【2010/09/10】初版公開。
■この記事と関連性の高い別の記事
- 負荷の大きいプロセスを特定する方法(TIPS)
- パフォーマンス・モニタの使い方(基本編)(TIPS)
- Windows OSでよく見かける重いプロセス、ベスト10(TIPS)
- typeperfコマンドでシステムのパフォーマンス・カウンタのデータを収集する(TIPS)
- パフォーマンス・モニタでHyper-Vサーバの実際のCPU使用率を調査する(TIPS)
Copyright© Digital Advantage Corp. All Rights Reserved.