【DB概論】DBMSに求められるもの(2)耐障害性:できるエンジニアになる! ちょい上DB術・基礎編(3)(1/3 ページ)
デキるエンジニアになるためには、DB技術の基礎は必須です。本連載では、豊富な実例と演習問題で、プロとして恥ずかしくない設計手順を解説します。DB設計のポイントとなる汎用的なケースを紹介しているので、通常の業務とは異なる場合でも応用できる「共通の考え方」を身に付けられます。
障害発生に対して、DBMSは最大限の回復措置を提供しています。しかし、障害を回復する手順をすべて自動で行うわけにはいきません。いざ障害が起きたときに正しい手順を落ち着いて遂行するために、次の事柄を明確にしておく必要があります。
- 障害時に要求されるユーザー要件(回復にかけることのできる時間など)
- データベースに対する更新処理の種類
- 回復時に実行される手順
- データベースの運用要件
- データベースのハードウェア要件
- どのような障害に対応する必要があるのか
- 障害対策例
- バックアップの種類
障害時に要求されるユーザー要件
ユーザー要件として確かめておくべき要件は、次の2つです。障害の種類ごとにこの2点を確認しておく必要があります。
- MTTR(Mean Time To Repair:平均回復時間)
- MTBF(Mean Time Between Failure:平均障害間隔)
一般的に起き得る障害のうち物理ディスク障害の場合を考えてみます。
●MTTR(Mean Time To Repair:平均回復時間)
平均回復時間は、おおまかにいって下記の時間を足した時間になります。
障害が起きた後バックアップを戻す時間
+
バックアップファイルを取得した時刻以降、データベースに適用された変更すべてをバックアップファイルに適用する時間
+
更新ログのうち、COMMITが完了していない仕掛中の更新をロールバックする時間
バックアップを戻す時間を短くするためには、障害が起きる可能性のあるファイルのサイズを小さくする必要があります。 データベースの物理ファイルの1つ1つを小さく設計しておけば、障害時にバックアップファイルを戻す時間を短くすることができます。
変更をバックアップファイルに適用する時間を短くするためには、バックアップを頻繁に取得して、バックアップ以降に取得した更新ログを少なくする必要があります。 そのため、頻繁に更新される表を格納している可能性のあるファイルは、頻繁にバックアップをとる必要があります。
逆に、ほとんど更新されないファイルはあまりバックアップをとる必要はないため、バックアップ対象から外せばバックアップを取得する時間を短縮することができます。 読み取り専用データを格納している表のみを含むファイルは、一度バックアップをとれば、その後バックアップをとる必要はありません。
●MTBF(Mean Time Between Failure:平均障害間隔)
平均障害間隔は、ユーザーによっては限りなく無限大を要求される場合もあります。 このような場合には、ハードウェア的な障害対策(ディスクの全二重化、すべてのコンポーネントの二重化)も検討する必要があります。 これらの要件は、システム構成全体を設計する方式設計と呼ばれる工程で検討する必要があります。
次に、障害発生時の回復処理を確実にするために、DBMSは「更新処理から更新確定処理まで」をどのような仕組みで処理しているかを説明します。 ここでは、Oracleデータベースを例にポイントを解説します。
データベースに対する更新処理(COMMIT時の処理フロー)
図1は、Oracleデータベースのメモリ上のコンポーネントと物理的なディスク上のコンポーネントの概要を示しています。
上半分の四角の枠内がメモリ上のコンポーネントで、下半分が物理的なファイル群です。
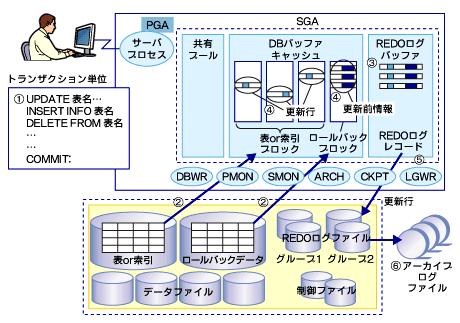
1.トランザクションが開始されます。
2.更新に必要なブロックが、データファイルからメモリ上のDBバッファキャッシュに読み込まれます。
ブロックの種類は、直接更新する必要のある表、または索引のブロックと、トランザクションの更新を元に戻すために必要な情報(以降、更新前情報)を格納するためのロールバックブロックの2種類があります。
表や索引のブロックに関しては、そのトランザクション内で更新すべき行が含まれているすべてのブロックが読み込まれます。 一方、ロールバックブロックは、トランザクション単位で管理され、更新前情報を順次書き込んでいきます。 ロールバックセグメントヘの書き込みは、1トランザクション単位で1つの塊になります。
3.更新対象の行にロックをかけた後、REDOログバッファにREDOログレコードを書き込みます。 変更処理では、どのブロックに対してどのような更新処理が行われるかという情報を、REDOログレコードという形で、まずREDOログバッファに書き込みます。
表のブロックに対しては、更新後の情報をREDOログレコードとして作成し、REDOログバッファに書き込みます。
ロールバックブロックに対する変更は、変更処理ごとに更新前情報をREDOログバッファに書き込んでいきます。 このとき、同じ変更処理(例えばUPDATE文)で作成された更新前情報と更新後の情報は1対にして書き込まれていきます。
REDOログレコードは、処理された順番を確認するため、データベース内で一意な番号SCN(System Commitment Number)番号をもっています。
4.REDOログバッファに書き込まれた内容を用いて、DBバッファキャッシュ上の該当ブロックが更新されます。 更新される対象となるブロックは、表または索引のブロックとロールバックブロックです。 トランザクションが継続している間、更新処理の数分だけ、2.から4.までの処理が必要に応じて繰り返し実行されます。 ロールバックセグメントには、更新を元に戻すための情報が、トランザクション開始からトランザクションの最後の更新まで順番に格納されます。
5.COMMIT文が発行されると、REDOログバッファに格納されていたREDOログレコードがREDOログファイルに書き込まれ、更新情報が物理的なファイルに書き込まれることを保証します。
6.REDOログファイルは、同じ大きさのログファイルを複数作成しておき、それにグループ番号を付与して順番に循環して書き込みができるようにします。 また、REDOログファイルは物理ファイルですから、サイズの上限があります。
一時点で書き込みができるグループは1つですから、そのグループヘの書き込みがいっぱいになると、ログスイッチというイベントが発生し、書き込み先が次のグループに切り替わります。 REDOログファイルに書き込まれた内容は、障害回復時に必要な情報なので、書き込みが循環して再度そのファイルを上書きしてしまう前に、アーカイブログファイルにコピーします。
ただし、アーカイブログファイルにコピーするという動きは、Oracleデータベースの運用モードがARCHIVELOGモードで運用されている場合のみです。
Copyright © ITmedia, Inc. All Rights Reserved.