いまさら聞けないKVSの常識をHbaseで身につける:ビッグデータ処理の常識をJavaで身につける(3)(1/3 ページ)
Hadoopをはじめ、Java言語を使って構築されることが多い「ビッグデータ」処理のためのフレームワーク/ライブラリを紹介しながら、大量データを活用するための技術の常識を身に付けていく連載
ビッグデータの要! KVSとは何なのか
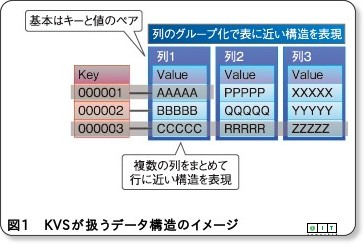
「KVS(Key-Value Store)」とは、Key値を指定してValue値の格納や取得を行う方式です。それに対して、RDBではキー(プライマリキー)が必須ではなく、逆に複数のカラムをセットしてキーにすることもできます。
テーブル構造だけを見れば、KVSとRDBは似ています。例えば、RDBでプライマリキーと1つのBLOB型を持ったテーブルを作れば、KVSと同じような構造にもなります。しかし、RDBでKVSのまねごとをするのと、KVSとして一から作られたものとでは、さまざまな違いがあります。
また、Javaプログラマであれば、「KVSはMapインターフェイスのようなものでアクセスできるデータベース」という表現の方が分かりやすいかもしれません。JavaのMapインターフェイスでは、Keyを指定してput/get/removeを行います。KVSでも同様に、基本的な操作はすべてKey値を指定して行います。
本稿では、JavaによるKVSの実装であるHbaseを使って、Hbaseにアクセスするプログラムを例に、KVSについて解説します。
KVSの全体像については、以下の記事を参照してください。
RDBとKVSは何が違うのか
RDBでは、システムの特性をテーブル設計に盛り込みます。
- 外部キーで、テーブル間のリレーショナルを表現
- 「UNIQUE」「NOT NULL」で、値に制約をかける
- カラムの型とサイズで、データ形式を表現
このテーブルにアクセスするアプリの開発は、例えばJavaであればテーブル構造に合わせたBeanを使用し、O/Rマッピングを行います。そのため、システムの仕様変更があったときには、「RDBのテーブル変更」「JavaのBean変更」の両方を行わなければなりません。
また、登録時にはデータの保存の前に、制約チェックなどの処理が実行されるため、全体の件数が増えれば増えるほど登録・削除時の負荷が高くなります。
それに対してKVSでは、Key値とValue値しか持たないため、制約や外部キーを設定できません。Value値は、数値型や文字列型といった型だけではなくデータサイズも不定です。そのため、システムの特性がテーブル設計に含まれておらず、システムの仕様変更があってもテーブル設計を変更する必要がありません。JavaScriptやRubyのようにゆるい型の言語を使ったときにはクラスの変更も不要なので、変化に強いシステムになります。
また、制約チェックなどを行わないため、全体の件数が増えても登録・削除が遅くなることがありません。
ただし、RDBでは当たり前にできても、KVSでは簡単にできないことがたくさんあります。例えば、INDEXやVIEW、集計関数、外部結合、シーケンスなどです。
これらは「KVSだと、まったくできない」わけではありません。集計関数を例にすれば、SQLのような標準的なクエリ言語はないものの、独自に実装すれば集計は可能です。しかし、集計関数はRDBが得意とする処理なので、KVSでRDB以上の効率を実現するのは大変です。KVSでは、KVSの得意とすることをし、RDBの得意なことはRDBに任せた方がいいでしょう。
現在利用できる主なKVS技術13選
現在利用できる主なKVS技術を並べておきます。
1.Amazon DynamoDB(AmazonWebServices)
2.Apache Cassandra(Apache)
3.Apache Hbase(Apache)
4.Bigtable(グーグル)
5.Flare(GREE)
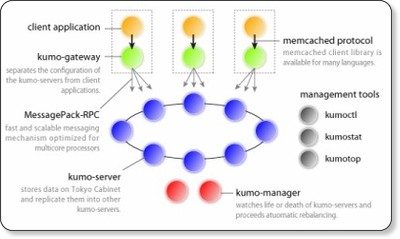
6.kumofs(えとらぼ)
7.Kyoto Cabinet/Tokyo Cabinet(FAL Labs)

8.memcached(Danga Interactive)
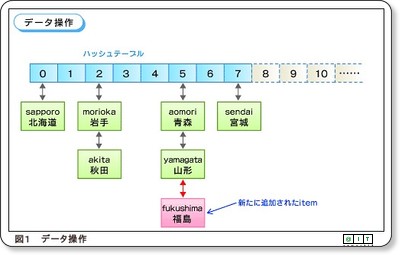
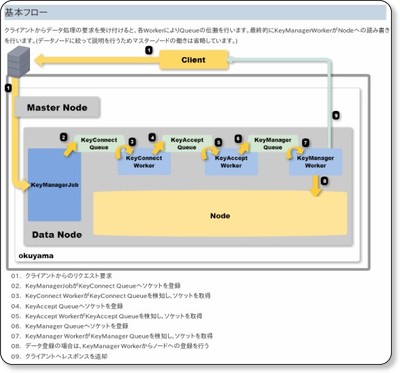
9.okuyama(神戸デジタル・ラボ)
10.Oracle Coherence(オラクル)
11.Redis(Redis)
12.ROMA(Rakuten On-Memory Architecture)(楽天)

13.Windows Azure テーブル・ストレージ(マイクロソフト)
次ページでは、実際にHbaseを動かしてみます。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。