ElasticsearchとKuromojiを使った形態素解析とN-Gramによる検索の適合率と再現率の向上:Elasticsearch+Hadoopベースの大規模検索基盤大解剖(2)(3/3 ページ)
リクルートの事例を基に、大規模BtoCサービスに求められる検索基盤はどう構築されるものなのか、どんな技術が採用されているのか、運用はどうなっているのかなどについて解説する連載。今回は、テンプレートを利用したインデックス生成など、検索結果の品質を向上させるためのさまざまな取り組みを紹介する。
検索ランキングの精度の指標「NDCG」
大きく問題の転換を行い、「カスタマーが求めている順番で検索結果を並べ替える」ことが主眼となりました。検索ランキングの精度の基本的な考え方は次のようになります。
検索結果のランキング順が、本来「カスタマーが求めたランキング」と、どの程度差があるか?
このような差を表す指標として、NDCG(Normalized Discounted Cumulative Gainもしくは、Normalized Discounted Cumulated Gain)という指標が情報検索の分野では利用されます。
関連性スコアとDCG
NDCGを導入するには、まず、関連性スコアを定義する必要があります。これまでは、ドキュメントの評価が「カスタマーが求めているか、否か」のTrue or Falseであったのに対し、「どの程度適合しているのか」を数値で表すことになります。
検索結果の各ドキュメントに、「このドキュメントは0.2、こちらのドキュメントは0.8」といったように関連性を表すスコアを付けるのです。サンプルとして、いまあるクエリに対するトップ5の検索結果のスコアが以下のようになっているとしましょう。
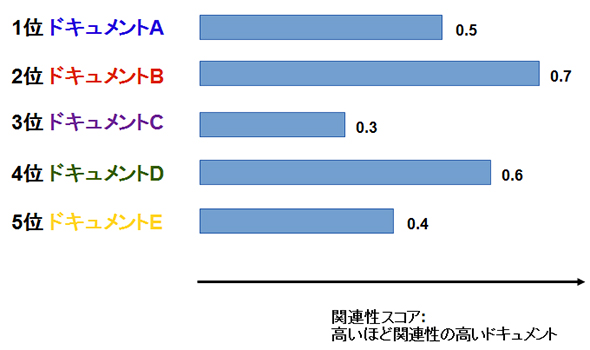
このように表現することにより、以下の傾向が分かります。
- 2位のドキュメントBは、2位にもかかわらず、5個のドキュメントの中では最高の関連性スコア ⇒ 本当は1位であるべきでは?
- 3位のドキュメントCは、3位にもかかわらず、5個のドキュメントの中では最低の関連性スコア ⇒ 本当は5位であるべきでは?
そして、先ほどの検索結果を関連性スコア順に並べた理想の順位は次のようになります。
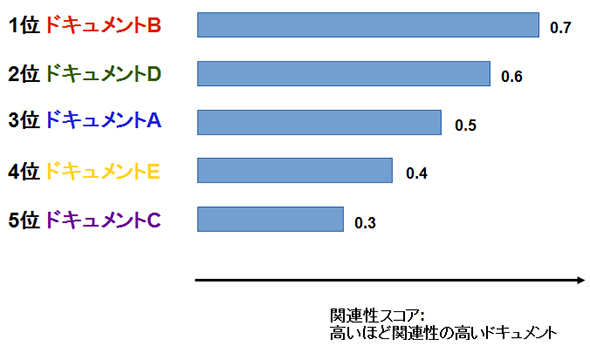
このような考察を、検索結果の第i位までで実際の数値で表現するのが「DCG(Discounted Cumulative Gain)」であり、第i位までの検索結果のDCGは次のように定義されます。

順位「i」のlogの値で割り算されている部分が、検索結果として下位に表示されたペナルティとして、関連性スコアに掛け合わされます。すなわち、高い関連性を持つドキュメントが下位にあると、その順位分だけ全体のスコアが下がるように表現されているのです。
NDCG=DCG÷IDCG
関連性スコアで並べ直した理想の検索結果に対するDCGを「IDCG(Ideal DCG)」と表すことにします。
すわなち、本来ならば、検索システムは関連性スコア順で結果を並べるべきであり、その本来の姿の検索システムのDCGがIDCGとなります。検索結果トップ「i」に対するDCGとIDCGによってNDCGは次のように表されます。
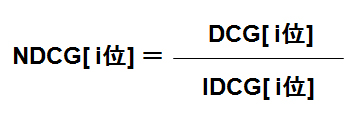
大ざっぱに言えば、NDCGは「≪検索結果のトップi件に対する実際の順位が、理想の順位とどれだけマッチしているか?」を表す指標となります。高ければ高いほど理想に近く、低ければ低いほど理想から離れていることになります。
ここまでで考えてきたNDCGはある特定のクエリに対するものでした。複数のクエリに対して理想の検索結果を準備できれば、後はそれらのNDCGの平均を求めることで、検索システム全体のランキングの精度を測ることが可能になります。
これまでの準備によって、検索ランキングの精度を計測することが可能になりました。
カスタマー行動による評価
NDCGを用いることで検索ランキングの精度を計測することが可能になりました。しかし、そもそも関連性スコアはどのように求めればよいでしょうか?
関連性スコアを求めるために
適合率と再現率の評価の際にも挙げたように、大きく次の2つソースが考えられます。
- 人為的に作成した正解データ:主観的に作成した「クエリ」と各ドキュメントの関連性スコアの対
- 検索ログ:検索システムを利用したカスタマーが検索を行った際の「クエリ」と「アクションのログ」から生成されたスコアの対
CTRとCVR
ここでは検索ログに注目したいと思います。多くのWebサービスでは、一般的な指標として、次の2つが計測されているでしょう。
- CTR(Click Through Rate):ページやリンクが表示された回数のうち、クリックされた回数の割合
- CVR(Conversion Rate):ページやリンクが表示された回数のうち、最終的な目標に到達した回数の割合
CTRやCVRを検索結果のページに対して計測しているならば、それらはそのまま関連性スコアとして用いることが可能です。CTRとCVRに関しては、提供する検索システムによって、同一視することも可能ですし、CTRとCVRの間にいくつかの段階を設けることも可能でしょう。
また、特にCTRとCVRの違いは大きな問題ではなく、実際に「クエリ」と「ドキュメント」の「関連性スコアをログからどのように算出するか?」が一番大切な問題になります。
検索ログから関連性スコアを算出できる
実際の検索システムを提供している個々のサービスにおいて、CVRの定義は異なっている場合が多いはずです。例えば次のようなCVRの重要度が設定されていたとします。
- 重要度1:検索結果がクリックされた
- 重要度2:検索結果先のページでドキュメントの回遊があった
- 重要度3:特別なページ上のアクション(例:「保存」や「買い物カゴ」に入れる)があった
- 重要度4:特別な実際のアクション(例:資料請求の電話など)があった
- 重要度5:Conversion に至った
カスタマーが検索を行い、検索結果が表示され、上記のいずれかに到達したかを重要度を加味して算出すれば、サービスの目標に則した「クエリ」と「ドキュメント」に対する関連性スコアと考えることが可能です。
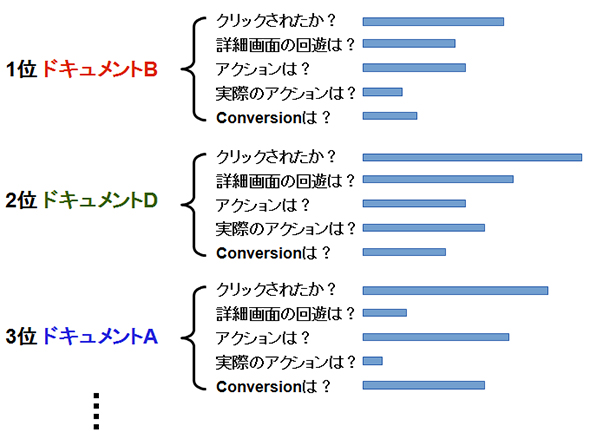
検索ログを解析することにより、関連性スコアをカスタマーからのフィードバックとして算出することが可能になります。
機械学習における「過学習」の問題と同じ
ここで一点注意しなければならない点があります。検索ログから関連性スコアが計算できるならば、次のように考えられないでしょか?
そのスコアを直接indexに格納し、そのスコア順でソートすればよいのではないか?
もちろんですが、関連性スコアを計算し直接indexに格納し、スコアをソートに利用することはまったく問題はありません。
ただ、注意しなければならないのは、それは検索ログ内に存在するクエリとドキュメントにのみ影響を与えることになり、検索ログに存在しない場合には効力を発揮しない点です。これは、アナロジーがうまく機能しないことを意味しており、機械学習における過学習と同様の問題となります。
機械学習を利用する
機械学習の大きな目標と同様に「未知のクエリと未知のドキュメントに対しても精度の高い検索」を提供するためには、検索ランキングの指標である関連性スコアだけでは、精度の高い検索を提供することが難しくなります。
例えば、ニュースのような「新しさ」を重要な指標とする検索の場合、すでにある検索ログは古いものになります。検索ログからの関連性スコアだけを重要視していては、過去の記事ばかりが高いスコアを持つことになり、これはニュースを検索する際に不都合な点になり得るでしょう。
検索対象がニュースのような場合には、個々のニュースであるドキュメントそのものに以下のような重要度が設定されるかもしれません。
- ドキュメントの重要度:人気のあるトピックを扱っている記事か?
- ドキュメントの重要度:新しい記事か?
- ドキュメントの重要度:信憑性のある記事か?
上記のようなドキュメントの重要度が算出できたならば、それらの値を直接indexに格納できます。そして、indexに格納されたドキュメントの重要度を特定の方法でソートに用いることにより、いかにカスタマーの望む関連性スコアと一致させるかがキーとなります。
ニュース記事の検索に対する関連性スコアは「CTR」となるかもしれません。この場合、「ドキュメントの重要度を用いてソートする方法」と「もっとも良い CTR」の関係性を見つけ出すことがキーとなります。このような関係性を求める問題は、とてもよく機械学習とマッチします。
前述のように、Elasticsearchを用いた例として、形態素解析とN-Gramのハイブリッドな検索を実現する際に、形態素解析に対しては重みを100に、N-Gramに対しては重みを10というように設定しました。
これらの値には、明確な根拠がなく、「どうもこれが良さそうだ」といった根拠しかありません。これまでに議論したカスタマーからのフィードバックを基にすれば、最適な重みを探索する問題を、機械学習の対象とすることが可能になります。
自立成長型サジェストとデータ収集
最後に、Qassのサジェストシステムを例に、これまでの議論をまとめたいと思います。
サジェストシステムとは、検索を提供しているWebページなどの検索クエリを入力するインプットボックスにて、カスタマーの入力を補助するシステムです。

例えば図11ですと、クエリ「か」に対して、「傘 折り畳み」「傘 ブランド」「傘 レディース」「傘 送料無料」「カレンダー」といった、「か」にひも付くワードを補助しています。そして、サジェストシステムの品質は、カスタマーの入力に対して、カスタマーが求めている検索クエリを、最も良いランキングで提供することとなります。
サジェストシステムにおける適合率と再現率の改善
サジェストシステムでは、適合率と再現率の改善を、次のような視点で行っています。
- 適合率
- 多くのカスタマーが必要としていること(例:「カレンダー」より「傘」を必要としている人が多いこと)
- 提供できる結果が多いこと(例:「カレンダー」よりも「傘」の方が、多彩なバリエーションの検索結果を提供できること)
- カスタマーのシチュエーションを考慮できること
- 時間
- 例:梅雨の季節ですと「か」に対して、「カレンダー」よりも「傘」を必要としている人が多いこと。
- 例:年末の季節ですと「か」に対して、「傘」よりも「カレンダー」を必要としている人が多いこと。
- 場所(例:東京の「し」ならば「新宿」で、京都の「し」ならば「四条」であること)
- 時間
- カスタマーの意図を汲み、クエリの書き換えをしてサジェストできること(例:「傘」に対して「折り畳み」や「レディース」など、連続して補助できること)
- 再現率
- カスタマーがクエリをどのように表現してもサジェストできること(例:読みの充実。「傘」は読み「かさ」でもサジェストできること)
- カスタマーの意図を汲み、クエリがサジェストできること(例:同義語の充実。「アンブレラ」でも「傘」をサジェストできること)
このような適合率・再現率の改善を行うことにより、カスタマーがサジェストを選択してくれることで、ランキングの精度を向上させます。
カスタマーから得るフィードバック
カスタマーからは、主に以下のフィードバックを受け取ります。
- 「クエリ」に対して「何位」のサジェスト候補を選択してくれたか?
- 選択してくれたサジェスト候補による検索で、目的は達成できたのか?
これらのフィードバックは、自動化された枠組みの中で数値化され、サジェストのindexに登録されます。そして、先に導入したNDCGを導くとことで「カスタマーが望んだ方向へサジェストの改善が行われたか?」を判定できます。また、これらのフィードバックサイクルは、適合率と再現率の改善の際の例で挙げたように、時間に機敏に反応する場合があります。
そのため、より高速なデータ収集と、検索精度向上施策をより速いサイクルで適用することが必要となります。
次回は、分析基盤の取り組みについて
駆け足になりましたが、Qassで行っている、検索品質向上への取り組みの概要を紹介致しました。今回は、「検索品質をどのように捉えるか」、そして「その品質をどのように向上させるか」に着目しました。キーとなるポイントは次の3点です。
- 適合率と再現率を上げる観点で施策を行う
- 検索品質を検索ランキングの品質と捉える
- カスタマーからのフィードバックを品質の軸として捉える
そして、これまで議論した分析結果は、自動的に検索エンジンへフィードバックされるエコシステムとして構築されています。
次回は、このエコシステムを支え、実際の検索品質向上を行う分析基盤の取り組みを紹介します。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 Hadoopは「難しい・遅い・使えない」? 越えられない壁がある理由と打開策を整理する
Hadoopは「難しい・遅い・使えない」? 越えられない壁がある理由と打開策を整理する
ブームだったHadoop。でも実際にはアーリーアダプター以外には、扱いにくくて普及が進まないのが現状だ。その課題に幾つかの解決策が出てきた。転換期を迎えるHadoopをめぐる状況を整理しよう。 いまさら聞けないHadoopとテキストマイニング入門
いまさら聞けないHadoopとテキストマイニング入門
Hadoopとは何かを解説し、実際にHadoopを使って大規模データを対象にしたテキストマイニングを行います。テキストマイニングを行うサンプルプログラムの作成を通じて、Hadoopの使い方や、どのように活用できるのかを解説します 検索エンジンの常識をApache Solrで身につける
検索エンジンの常識をApache Solrで身につける
Hadoopをはじめ、Java言語を使って構築されることが多い「ビッグデータ」処理のためのフレームワーク/ライブラリを紹介しながら、大量データを活用するための技術の常識を身に付けていく連載 全文検索エンジン「Lucene.Net」を使う
全文検索エンジン「Lucene.Net」を使う
サイト構築などで使用できる検索エンジンをVBで活用。日本語アナライザを用いたインデックス作成から検索アプリ作成まで。- クックパッド、グリー、ぐるなび、CROOZは検索技術をどう使っているのか:検索技術を使うなら知ってないと損する6つのこと
ソーシャルアプリなど大規模Webサービスや企業内システムでも欠かせない検索技術のまとめ - Namazuによる全文検索システムの導入
サーバに集積した情報を再利用するには全文検索システムが必要だ。Namazuのインストールから設定、WordやExcelファイルのサポート方法、効果的な運用方法までを解説する