UnicodeüiāåājāRü[āhüjüFTech Basicsü^Keyword
āfāoāCāXéŌOSé¢ŌéĒéĖüAāVāXāeāĆé╠ĢWÅĆōIé╚ĢČÄÜāRü[āhéŲéĄé─ŹLéŁÄgéĒéĻéķéµéżé╔é╚é┴éĮĢČÄÜāRü[āhüuUnicodeüvüBé╗é╠ō┴ÆźéŌōoÅĻé╠öwīiüAāLü[éŲé╚éķŗZÅpéé▄éŲé▀éķüB
é▒é╠ŗLÄ¢é┼Ģ¬é®éķé▒éŲ
- Unicodeé═üAÉóŖEÆåé╠éĀéńéõéķĢČÄÜéōØłĻé╠āRü[āhæ╠īné┼łĄéżéĮé▀é╔ŹņéńéĻéĮŹæŹ█ĢWÅĆŗKŖié┼üAæĮīŠīĻæ╬ē×éŚełšé╔éĘéķ
- é®é┬é─ŹæéŌOSé▓éŲé╔ł┘é╚é┴é─éóéĮĢČÄÜāRü[āhüiShift_JISé╚éŪüjé╠¢ŌæĶéēīłéĘéķéĮé▀üAō·ÆåŖžé╠Ŗ┐ÄÜéōØŹćéĘéķé╚éŪéĄé─¢cæÕé╚ĢČÄÜéĹś^éĄé─éóéķ
- 16bité┼Ĺé▄éńé╚éóĢČÄÜé═üuāTāŹāQü[āgāyāAüvé┼Ģ\ī╗éĄüAÄ└Ź█é╠āfü[ā^é═UTF-8é╚éŪé╠ī`Ä«é╔ĢäŹåē╗éĄé─éóéķ
ŹXÉVŚÜŚ
üy2025/07/03üzŗLÄ¢é╠Śv¢±éÆŪŗLéĄé▄éĄéĮ

ü@üuUnicodeüvüiāåājāRü[āhüjé═üAÉóŖEÆåé╠ĢČÄÜé1é┬é╠ĢČÄÜāRü[āhæ╠īné┼łĄé”éķéµéżé╔ŹņéńéĻéĮüAĢČÄÜāRü[āhāZābāgé╠ŗKŖiüBī╗Ź▌é╠āRāōāsāģü[ā^āVāXāeāĆé┼é═ōÓĢöāRü[āhéé▒é╠Unicodeé╔éĄé─üAÉóŖEÆåé┼é┘é┌ō»éČāoāCāiāŖü[āRü[āhéÄgé”éķéµéżé╔éĄé─éóéķé▒éŲé¬æĮéóüBUnicodeāRāōā\ü[āVāAāĆé¬ŗKŖi鏶ÆĶéĄé─éóéķüB
UnicodeōoÅĻé╠öwīi
ü@Unicodeé¬ōoÅĻéĘéķé▄é┼é═üAāRāōāsāģü[ā^āVāXāeāĆé┼é═Shift_JISüiÄÕé╔DOSéŌWindowsüjéŌEUCüiExtended UNIX CodeüAÄÕé╔UNIXüjüAEBCDICüiÄÕé╔āüāCāōātāīü[āĆāRāōāsāģü[ā^üjé╚éŪé╠āRü[āhé¬ÄgéĒéĻé─éóéĮüB
ü@é▒éĻéńé═üAēpīĻéŲéÓéż1é┬é╠īŠīĻüiō·¢{īĻéŌÆåŹæīĻé╚éŪüjéÄgéżĢ¬é╔é═ō┴é╔¢ŌæĶé═é╚é®é┴éĮéÓé╠é╠üAé│éńé╔æĮéŁé╠īŠīĻéō»Ä×é╔Ägéżé╠é═Źóō’é┼éĀé┴éĮüBé▄éĮĢČÄÜāRü[āhæ╠īné╔ŹćéĒé╣é─āvāŹāOāēāĆééóé┐éóé┐ÅCÉ│éĘéķĢKŚvé¬éĀéķé╚éŪüAĵéĶłĄéóéÓŖ╚ÆPé┼é═é╚é®é┴éĮüB
Unicodeé╠æ_éóéŲō┴Æź
ü@é╗é▒é┼Źlł─é│éĻéĮé╠é¬üAÉóŖEÆåé╠ĢČÄÜāRü[āhéōØłĻéĄé─łĄé”éķéµéżé╔éĄéĮUnicodeé┼éĀéķüBæSé─é╠ĢČÄÜÄĒéō»éČéµéżé╔łĄé”éķéĮé▀üAīŠīĻé╠ÄĒŚ▐é╔éµé┴é─āvāŹāOāēāĆéĢŽŹXéĘéķĢKŚvé¬é╚éŁüAĢČÄÜŚ±ĢöĢ¬é│锢|¢¾éĘéĻé╬üAŖ╚ÆPé╔æĮīŠīĻē╗ü^ŹæŹ█ē╗é┼é½éķüiÄ└Ź█é╔é═üAŖeŹæī┼ŚLé╠ŗ@ö\é╠ÆŪē┴éÓĢKŚvé╔é╚éķé¬üjüB
ü@Unicodeé╠āAāCāfāAé╠ŖŅ¢{é═üAÉóŖEÆåé╠ĢČÄÜé16bité╠ī┼ÆĶÆĘé┼Ģ\ī╗éĄüAĢČÄÜŚ±é╠ĵéĶłĄéóéŚełšé╔éĘéķé▒éŲé┼éĀéķüB
ü@é╗é╠éĮé▀üAŹ┼Åēé╠ŗKŖié┼é═CJKōØŹćŖ┐ÄÜüiīŃÅqüjé╚éŪéÄgé┴é─ĢKŚvé╚āRü[āhŚ╠łµé╠ł│ÅkéÉ}é┴é─éóéĮüBéĄé®éĄüAé╗é╠īŃé╠ĢČÄÜāRü[āhé╠ÆŪē┴é╚éŪé┼üA16bité┼é═Ģ\ī╗éĄé½éĻé╚éóé┘éŪæĮéŁé╠ĢČÄÜÉöé╔é╚é┴éĮüBé╗éĻé┼éÓüAāTāŹāQü[āgāyāAüiīŃÅqüjéÄgé┴é─16bitÆPł╩é┼łĄé”éķéµéżé╔éĘéķé╚éŪüA16bité╠é▄é▄é┼éÓÄgéóéŌéĘéŁé╚éķŹHĢvéō▒ō³éĄé─éóéķüB
ü@é▄éĮÆPé╚éķĢČÄÜāRü[āhĢ\éŲéóé┴éĮł╩ÆuĢté»é╔éŲéŪé▄éńéĖüAĢĪÉöé╠UnicodeĢČÄÜéægé▌ŹćéĒé╣é─éµéĶĢĪÄGé╚Ŗ┐ÄÜéŌŗLŹåé╚éŪéĢ\ī╗éĄéĮéĶüiŹćÄÜéŌīŗŹćĢČÄÜé╚éŪüjüAĢČÄÜéĢ\Ä”éĘéķī³é½éÄwÆĶéĘéķüiēEé®éńŹČéųÅæéŁüjüAł┘æ╠ÄÜé╠æIæŗ@ö\éō▒ō³éĘéķé╚éŪüAÄ└æĢéŌē^Śpé╔é▄é┼ōźé▌Ź×é±éŠÆĶŗ`é¬Ŗ▄é▄éĻé─éóéķüB
Unicodeé╔ŖųéĘéķŗKŖi
ü@ÉóŖEÆåé╠ĢČÄÜāRü[āhéōØłĻéĄéĮāRü[āhæ╠īnéŲéó鿏lé”Ģ¹é═üAUnicodeéŠé»é┼é╚éŁüAĢČÄÜāRü[āhé╠ŹæŹ█ĢWÅĆŗKŖiéɦÆĶéĄé─éóéķISO/IEC 10646é┼éÓŹlŚČé│éĻé─éóéĮé¬üAŹ┼ÅIōIé╔é═Unicodeł─é╔łĻ¢{ē╗é│éĻéĮüBī╗Ź▌é┼é═üAUnicodeāRāōā\ü[āVāAāĆé¬Unicodeé╠ÉVéĄéóŗKŖiéɦÆĶéĘéķéŲüAé╗éĻé¬é┘é┌é╗é╠é▄é▄ŹæŹ█ĢWÅĆŗKŖié┼éĀéķISO/IEC 10646üuUniversal Coded Character SetüiUCSüjüvéŲéĄé─Å│öFé│éĻé─éóéķüBé│éńé╔é╗éĻéō·¢{ī³é»é╔éĄéĮéÓé╠éŲéĄé─JIS X 0221üuŹæŹ█ĢäŹåē╗ĢČÄÜÅWŹćüiUCSüjüvé¬É¦ÆĶé│éĻé─éóéķüB
ü@UnicodeŗKŖié═ł╚ē║é╠éµéżé╔ēĮōxé®æÕé½éŁē³ÆĶé│éĻé─éóéķüBŹ┼ŗ▀é┼é═ŖGĢČÄÜéĵéĶō³éĻéĮéĶüAī╗æŃé╠ĢČÄÜéŠé»é┼é╚éŁüAī├æŃé╠üiŖ∙é╔ÄgéĒé╚éŁé╚é┴éĮéµéżé╚üjĢČÄÜé▄é┼ĵéĶō³éĻéĮéĶéŲüAī├ĢČÅæéÓŖ▄é▀éĮéĀéńéõéķĢČÄÜÅŅĢ±éāfü[ā^ē╗é┼é½éķéµéżé╔ē³ÆĶé│éĻæ▒é»é─éóéķüB
| āoü[āWāćāō | ĢŽŹXō_ |
|---|---|
| Unicode 1.x | CJKōØŹćŖ┐ÄÜéŖ▄é±éŠŹ┼Åēé╠UnicodeŗKŖi JIS X 0201ü^JIS X 0208üiæµ1üAæµ2ÉģÅĆŖ┐ÄÜüjüAJIS X 0212üiĢŌÅĢŖ┐ÄÜüjéŖ▄é▐ |
| Unicode 2.x | BMPł╚ŖOé╠¢╩éÆŪē┴éĄé─üAāTāŹāQü[āgāyāAé╔éµéķāAāNāZāXéÄ└ī╗ |
| Unicode 3.x | CJKōØŹćŖ┐ÄÜé╠ŖgÆŻAéÆŪē┴üBJIS X 0213üiæµ3üAæµ4ÉģÅĆŖ┐ÄÜüjé╠łĻĢöéÆŪē┴ |
| Unicode 4.x | ISO/IEC 10646:2003é╠ÆŪĢŌAmd.1é╔æ╬ē× |
| Unicode 5.x | ISO/IEC 10646:2003é╠ÆŪĢŌAmd.2é╚éŪé╔æ╬ē× |
| Unicode 6.x | ISO/IEC 10646:2010ü^2012é╚éŪé╔æ╬ē× |
| Unicode 7.x | ISO/IEC 10646:2012é╠ÆŪĢŌAmd.1üAAmd.2é╔æ╬ē×üBŖGĢČÄÜé╠ÆŪē┴ |
| Unicode 8.x | ISO/IEC 10646:2014é╠ÆŪĢŌAmd.1é╔æ╬ē× |
| Unicodeé╠ÄÕé╚āoü[āWāćāōéŲŖTŚv Ź┼ŗ▀é╠āoü[āWāćāōāAābāvé┼é═üAÉVéĄéóĢČÄÜāZābāgé╠ÆŪē┴é¬āüāCāōéŲé╚é┴é─éóéķüB | |
ü@ł╚ē║é┼é═üAUnicodeé╠āLü[éŲé╚éķĢöĢ¬éŖ¶é┬é®ÄµéĶÅŃé░üAēÉÓéĘéķüB
Unicodeé╠āRü[āhā|āCāōāgüiU+0000ü`U+10FFFFüj
ü@Unicodeé┼ÆĶŗ`é│éĻé─éóéķĢČÄÜé╔é═üAæSé─öįŹåüiāRü[āhā|āCāōāgüBÆPé╔ĢČÄÜāRü[āhéŲéÓüjé¬Ģté»éńéĻé─éóéķüB
ü@é▄éĮĢČÄÜāRü[āhé═üuU+nnnnüvéŲéóéżĢ¹¢@é┼Ģ\ŗLéĘéķüBné═4ü`6īģé╠16ÉiÉöé┼Ģ\ī╗éĄéĮĢČÄÜāRü[āhöįŹåé┼éĀéķüB
ü@ī╗Ź▌é╠Unicodeé┼é═üuU+0000ü`U+10FFFFüvé▄é┼é╠ö═ł═éÄgŚpéĘéķé▒éŲé╔éĄé─éóéķüBæŹÉöé╔éĘéķéŲ111¢£4112ĢČÄÜé▄é┼ĹŚeē┬ö\éŲéóéżé▒éŲé╔é╚éķüiUnicode 8.0é┼Ä└Ź█é╔ÆĶŗ`é│éĻé─éóéķé╠é═¢±12¢£ĢČÄÜüjüB
¢╩üAŗµüAō_
ü@ī╗Ź▌é╠Unicodeé╠āRü[āhéæSé─Ģ\ī╗éĘéķé╔é═21bité╠āfü[ā^ĢØé¬ĢKŚvé╔é╚éķüBé▒éĻé24bité▄é┼ŖgæÕéĄüAÅŃł╩é®éń8bitüA8bitüA8bitéŲŗµÉžé┴éĮéÓé╠éé╗éĻé╝éĻüu¢╩üiplane)üvüuŗµüirowüjüvüuō_üicellüjüvéŲī─éįüił╚æOé═üu¢╩üvé╠ÅŃé╔üuīQüigroupüjüvéŲéóéżĢ¬Ś▐éÓéĀé┴éĮé¬üAUnicodeé╠ÅŃī└é¬U+10FFFFé╚é╠é┼ÅĒé╔īQ0éĄé®æČŹ▌é╣éĖüAĢsŚvé╚é╠é┼ī╗Ź▌é┼é═īQéŲéó鿌pīĻé═öpÄ~é│éĻéĮüjüB
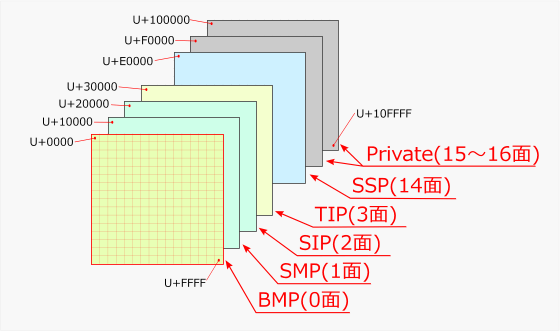
Unicodeé╠¢╩
256ü~256é╠ĢČÄÜé╠ÅWé▄éĶéüu¢╩üvéŲīŠéóüAUnicodeé┼é═æµ0¢╩é®éńæµ16¢╩é▄é┼éÄgéżé▒éŲé╔é╚é┴é─éóéķüBæµ0¢╩é═16bité╠āRü[āhé┼Ģ\ī╗é┼é½éķé╠é┼ÄgéóéŌéĘéóé¬üAæµ1¢╩ł╚Ź~é═éµéĶæĮéŁé╠bitÉöé¬ĢKŚvé╚é╠é┼ĵéĶłĄéóé¬ÅŁéĄ¢╩ō|é┼éĀéķüBāAāvāŖāPü[āVāćāōé╔éµé┴é─é═üABMP¢╩é╠UnicodeéĄé®łĄé”é╚éóéÓé╠éÓéĀéķüB
ü@¢╩é╔é═üAé╗é╠ōÓŚeé╔ē×éČé─Ĥé╠éµéżé╚¢╝æOé¬Ģté»éńéĻé─éóéķüB
| ¢╩ | āRü[āhł╩Æu | ¢╝Å╠üAŚpōr |
|---|---|---|
| æµ0¢╩ | U+0000ü`U+FFFF | üEŖŅ¢{æĮīŠīĻ¢╩üiBasic Multilingual PlaneüFBMPüj üEī╗Ź▌éµéŁÄgéĒéĻé─éóéķēóĢ─é╠āAāŗātā@āxābāgéŌCJKŖ┐ÄÜāRü[āhé╚éŪé¬ŖäéĶō¢é─éńéĻé─éóéķüBŹ┼Åēé╠UnicodeŗKŖié┼ɦÆĶé│éĻé─éóéĮŚ╠łµ üEé▒é╠¢╩é╠āRü[āhé═16bitł╚ōÓé┼Ģ\ī╗é┼é½éķéĮé▀üAāRü[āhī°Ś”é¬éµéó |
| æµ1¢╩ | U+10000ü`U+1FFFF | üEÆŪē┴æĮīŠīĻ¢╩üiSupplementary Multilingual PlaneüFSMPüj üEī╗Ź▌é┼é═éĀé▄éĶÄgéĒéĻé─éóé╚éóī├æŃé╠ĢČÄÜéŌüAŖńĢČÄÜé╚éŪé╠ŗLŹåŚ▐éĹŚe |
| æµ2¢╩ | U+20000ü`U+2FFFF | üEÆŪē┴Ŗ┐ÄÜ¢╩üiSupplementary Ideographic PlaneüFSIPüj üEÉl¢╝é┼éĄé®ÄgéĒé╚éóéµéżé╚üAÄgŚpĢpōxé╠ÆßéóŖ┐ÄÜé╚éŪéĹŚe |
| æµ3¢╩ | U+30000ü`U+3FFFF | üEæµÄOŖ┐ÄÜ¢╩üiTertiary Ideographic PlaneüFTIPüj üEŹbŹ£ĢČÄÜé╚éŪé╠ī├æŃĢČÄÜéĹŚeéĘéķŚ\ÆĶé╠Ś╠łµ |
| æµ4ü`13¢╩ | U+40000ü`U+ DFFFF | üi¢óÄgŚpüj |
| æµ14¢╩ | U+E0000ü`U+EFFFF | üEÆŪē┴ō┴ÄĻŚpōr¢╩üiSupplementary Specialü]purpose PlaneüFSSPüj üEīŠīĻā^āOéŌł┘æ╠ÄÜāZāīāNā^é╚éŪéĹŚe |
| æµ15¢╩ | U+F0000ü`U+FFFFF | üEÄäŚp¢╩üiPrivate Useüj üEŖOÄÜé╚éŪé┼ÄgŚpé┼é½éķ |
| æµ16¢╩ | U+100000ü`U+10FFFF | üEÄäŚp¢╩üiPrivate Useüj üEŖOÄÜé╚éŪé┼ÄgŚpé┼é½éķ |
| Unicodeé╠¢╩öįŹåéŲé╗é╠Śpōr | ||
ü@ŖŅ¢{æĮīŠīĻ¢╩üiBMPüjé╠ĢČÄÜé╠ŚßéĤé╔Ä”éĄé─é©éŁüB
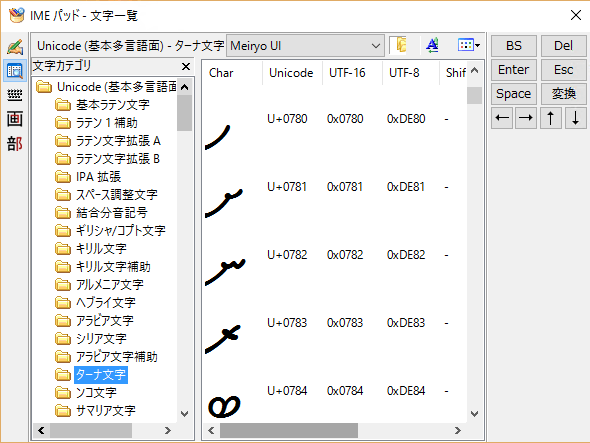
Unicodeé╠ŖŅ¢{æĮīŠīĻ¢╩üiBMPüjé╠Śß
é▒éĻé═Windows 10é╠MS-IMEé╔Ģtæ«éĘéķIMEāpābāhé┼UnicodeĢČÄÜéī¤Ź§üAō³Ś═éĄé─éóéķéŲé▒éļüBŖe¢╩é╔éŪé╠éµéżé╚ĢČÄÜé¬ÆĶŗ`é│éĻé─éóéķé®éŖ╚ÆPé╔Æméķé▒éŲé¬é┼é½éķüiüuĢČÄÜāRü[āhĢ\üvāAāvāŖé═BMP¢╩é╠UnicodeéĄé®Ģ\Ä”üAō³Ś═é┼é½é╚éóüjüBBMPé╔é═ī╗Ź▌éµéŁÄgéĒéĻéķēóĢ─īŚé╠āAāŗātā@āxābāgŚ▐é╠é┘é®üAJIS X 0201ü^JIS X 0208üiæµ1üAæµ2ÉģÅĆŖ┐ÄÜüjüAJIS X 0212üiĢŌÅĢŖ┐ÄÜüjé¬Ŗ▄é▄éĻé─éóéķüBé┘éŲé±éŪé╠ÅĻŹćé═é▒é╠¢╩éŠé»é┼æ½éĶéķéŠéļéżüB
CJKüiChineseüAJapaneseüAKoreanüjōØŹćŖ┐ÄÜ
ü@CJKōØŹćŖ┐ÄÜéŲé═üAÉóŖEÆåé╠æSé─é╠ĢČÄÜāRü[āhé16bitĢØé╔ĹŚeéĘéķéĮé▀é╔Źlł─é│éĻéĮüAŖ┐ÄÜĢČÄÜé╠ĢäŹåē╗Ģ¹¢@é┼éĀéķüB
ü@Ŗ┐ÄÜĢČē╗īŚüiō·¢{éŲÆåŹæüAŖžŹæüBīŃé╔āxāgāiāĆīŚé┼é╠Ŗ┐ÄÜéÓŖ▄é▀éķé▒éŲé╔é╚éķüjé┼ŚśŚpé│éĻé─éóéķŖ┐ÄÜé═üAī╗Ź▌ŚśŚpé│éĻé─éóéķéÓé╠éŠé»é┼éÓēĮ¢£ĢČÄÜéÓéĀéķüBé╗é╠éĮé▀üAŖeŹæé¬Ŗ∙é╔ŹæōÓé┼ŚśŚpéĄé─éóéĮŖ┐ÄÜāRü[āhéæSé─ŹćīvéĘéķéŲüAéŲé─éÓ16bité╔é═ĹŚeé┼é½é╚éóÉöé╔ÆBéĄé─éóéĮüB
ü@é╗é▒é┼CJKōØŹćŖ┐ÄÜé┼é═üAŖ┐ÄÜéé╗é╠ī`žé╔ŖŅé├éóé─Ź─Ģ¬Ś▐éĄüAō»éČŚRŚłéŌī`žé╠Ŗ┐ÄÜé═üA1é┬éŠé»Ä¹ŚeéĘéķüAéŲéóéżĢ¹ÉjéŹ╠ŚpéĄéĮüB
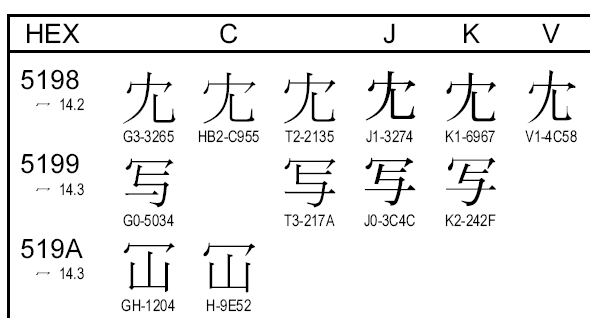
CJKü^CJKVōØŹćŖ┐ÄÜé╠Śß
ōØŹćŖ┐ÄÜé╠ŚßüiUnicodeé╠ÄdŚlÅæéµéĶł°ŚpüjüBCé═ÆåŹæüAJé═ō·¢{üAKé═ŖžŹæüAVé═āxāgāiāĆüiŖ┐ēzüjé┼é╗éĻé╝éĻŚśŚpé│éĻé─éóéķŖ┐ÄÜüBé╗éĻé1é┬é╔ōØŹćéĄé─éóéķüBŹæé▓éŲé╔ÅŁéĄéĖé┬Åææ╠鬳┘é╚éķéÓé╠é╠üiŚßüFU+5199é╠üuÄ╩üvüjüAé▒éĻé═ŚßÄ”É}ī`é┼éĀéĶüAÅææ╠ü^āfāUāCāōé╠łßéóé═ĢČÄÜāRü[āhé┼é═ŖųŚ^éĄé╚éóüAéŲéĄé─éóéķüBō·¢{īĻéŲéĄé─É│éĄéŁĢ\Ä”é│é╣éķé╔é═üAō·¢{īĻī³é»é╠UnicodeātāHāōāg錜ŚpéĘéķĢKŚvé¬éĀéķüBWindowsé┼éóéżéŲüAMS¢ŠÆ®é╚éńÅŃé╠üuJ0-3C4Cüvé╠éµéżé╔Ģ\Ä”é│éĻéķé¬üASimSunātāHāōāgé╚éńüuG0-5034üvé╠éµéżé╔Ģ\Ä”é│éĻéķüB
ü@CJKōØŹćŖ┐ÄÜéÄgéżé▒éŲé╔éµéĶüAō¢Åēé╠UnicodeŗKŖié┼é═¢±2¢£é╠Ŗ┐ÄÜéĹŚeéĄüAæSæ╠éŲéĄé─é═16bitōÓé╔ö[é▀éķé▒éŲé¬é┼é½éĮüBéŠé¬é╗é╠īŃüAÆŪē┴Ŗ┐ÄÜ¢╩üiSIPüjé╔éÓÉVéĮé╔ĢŌÅĢŖ┐ÄÜéÆŪē┴éĘéķé╚éŪéĄéĮīŗē╩üAī╗Ź▌é┼é═āgü[ā^āŗé┼¢±8¢£ĢČÄÜÆ÷ōxé╠Ŗ┐ÄÜé¬Ä¹Śeé│éĻé─éóéķüB
ü@é╚é©üAō·ÆåŖžé╠Ŗ┐ÄÜéōØŹćéĄéĮéĮé▀üAĢČÄÜāRü[āhé╠Åćöįé═ī│é╠JISŗKŖiéŲé═é®é╚éĶĢŽéĒé┴é─éĄé▄é┴é─éóéķüBé╗é╠éĮé▀ÆPé╔ĢČÄÜāRü[āhÅćé╔ā\ü[āgéĄé─éÓüAéĀé▄éĶłė¢Īé╠éĀéķīŗē╩é═ōŠéńéĻé╚éóüBā\ü[āgéĘéķé╔é═üAŖ┐ÄÜéŲé╗é╠ōŪé▌éŗLś^éĄéĮĢŌÅĢōIé╚āfü[ā^ü[āxü[āX錜ŚpéĘéķé╚éŪé╠ŹHĢvé¬ĢKŚvé╔é╚éķüB
āTāŹāQü[āgāyāAüiæŃŚpæ╬üj
ü@üuāTāŹāQü[āgāyāAüiæŃŚpæ╬üjüvéŲé═üAUnicodeé╔æµ1¢╩üiSMPüjł╚Ź~éÆŪē┴éĄéĮéŲé½é╔ō▒ō³é│éĻéĮüAÉVéĄéóĢäŹåē╗Ģ¹¢@é┼éĀéķüB16bitĢØé╠ĢČÄÜāRü[āhé2é┬Ägé┴é─üAU+10000ü`é╠ĢČÄÜéĢ\ī╗é┼é½éķéµéżé╔éĄé─éóéķüB
ü@ō¢Åēé╠Unicodeé┼é═üAĢČÄÜāRü[āhéæSé─16bité┼Ģ\ī╗éĄé─é©éĶüA1ĢČÄÜō¢éĮéĶ16bitĢØé╠ĢŽÉöé¬1é┬éĀéĻé╬UnicodeĢČÄÜéĹŚeé┼é½éĮüBéŠé¬U+10000ü`é╠ĢČÄÜāRü[āhé┼é═é▒éĻé═Ģsē┬ö\é┼éĀéķüB
ü@é╗é▒é┼üA16bitü~2āyāAé┼æSé─é╠ĢČÄÜāRü[āh鳥éżĢ¹¢@鬏lł─é│éĻéĮüBé▒éĻé¬āTāŹāQü[āgāyāAé┼éĀéķüBBMPé╠¢óÄgŚpŚ╠łµé╔éĀé┴éĮāRü[āhé╠ōÓüAU+D800ü`U+DBFFüi1024ĢČÄÜĢ¬üjéŲU+DC00ü`U+DFFFüi1024ĢČÄÜĢ¬üjé╠āyāAéÄgé┴é─üA1024ü~1024üü¢±100¢£ĢČÄÜĢ¬é╠āRü[āhŚ╠łµéŖmĢ█éĄüAé▒éĻéU+10000ü`U+10FFFFé╔ŖäéĶō¢é─éķé▒éŲé╔éĄé─éóéķüB
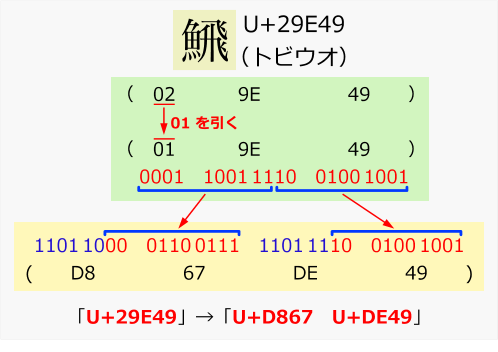
āTāŹāQü[āgāyāAé╠Śß
üuU+29E49üvüiüuāgārāEāIüvéŲéóéżŖ┐ÄÜüjéŲéóéżUnicodeĢČÄÜéāTāŹāQü[āgāyāAé┼Ģ\ī╗éĄéĮŚßüBāTāŹāQü[āgāyāAé╔ĢŽŖĘéĘéķé╔é═üAé▄éĖĢČÄÜāRü[āhé®éńU+10000éīĖÄZéĄé─20bité╠ÉöÆlé╔ĢŽŖĘéĘéķüBé╗éĻéÅŃē║10bitéĖé┬é╔Ģ¬ŖäéĄüAé╗éĻé╝éĻé╠ÆléU+D800éŲU+DC00é╔ē┴é”éķéŲāTāŹāQü[āgāyāAé╔é╚éķüB
Unicodeé╠āēāEāōāhāgāŖābāvéŲCJKī▌ŖĘŖ┐ÄÜ
ü@CJKōØŹćŖ┐ÄÜé╔é═üAé╗é╠ŖŅéŲé╚é┴éĮŖeŹæĢ╩é╠ĢČÄÜāRü[āhŗKŖié¬éĀéĶüAé╗éĻéńéŲæŖī▌ĢŽŖĘé┼é½éķéµéżé╔é╚é┴é─éóéķüBé▒éĻéāēāEāōāhāgāŖābāvüiēØĢ£ĢŽŖĘüjéŲéóéżüié▒éĻé¬é┼é½é╚éóéŲüAŖ∙æČé╠āVāXāeāĆéŲé╠æŖī▌āfü[ā^īŖĘ鬏óō’é╔é╚éķüjüB
ü@éŠé¬ī│é╠ŗKŖiÄ®æ╠é╠éÓé┬×B¢åɽéŌŗKŖiɦÆĶÄ×é╠ā~āXé╚éŪé╔éµéĶüACJKōØŹćŖ┐ÄÜé╔ĹŚeé│éĻé─éóé╚éóĢČÄÜé╚éŪé¬æČŹ▌éĄé─éóéķüBé▒éĻéĢŌÅĢéĘéķéĮé▀é╔üAŖ¶é┬é®é╠Ŗ┐ÄÜéCJKī▌ŖĘŖ┐ÄÜéŲéĄé─ĹŚeéĄé─éóéķüBCJKī▌ŖĘĢČÄÜéīoŚRéĘéķé▒éŲé╔éµéĶüAŖmÄ└é╔UnicodeéŲī│é╠Ŗ┐ÄÜāRü[āhéŲé╠Ŗįé┼æŖī▌ĢŽŖĘé¬é┼é½éķéµéżé╔é╚éķüB
īŗŹćĢČÄÜ
ü@Unicodeé┼é═üA2é┬ł╚ÅŃé╠UnicodeĢČÄÜéægé▌ŹćéĒé╣é─1é┬é╠ĢČÄÜéĢ\ī╗éĘéķüAüuīŗŹćĢČÄÜüicombining characterüjüv鬌śŚpé┼é½éķüBŖ╚ÆPé╚éÓé╠é┼é═üAŚßé”é╬āhāCācīĻé╠āEāĆāēāEāgé╚éŪé╠éµéżé╔üAĢĻē╣é╠ÅŃé╔üuüNüvé¬ĢtéóéĮĢČÄÜéŹņɼéĘéķüAéŲéóé┴éĮŚpōré╔ÄgŚpé┼é½éķüiāEāĆāēāEāgĢté½é╠ĢČÄÜéÓéĘé┼é╔ÆĶŗ`é│éĻé─éóéķé¬üjüBō·¢{īĻé┼éÓüAüué═üvéŲüuüJüvé┼üué╬üvé╔éĘéķüAéŲéóé┴éĮÄgéóĢ¹é¬é┼é½éķüiĢČÄÜāfü[ā^éŲéĄé─é═üAUnicodeé┼2ĢČÄÜĢ¬éÉĶŚLéĄé─éóéķüjüBīŠīĻé╔éµé┴é─é═üAæOīŃé╔Æué®éĻéķĢČÄÜé╚éŪé╔éµé┴é─æSæ╠é╠ī`žé¬æÕé½éŁĢŽéĒéķéÓé╠é¬éĀéĶüAé▒é╠éµéżé╚īŠīĻé┼é═éĀéńé®éČé▀ĢČÄÜāRü[āhéæĮÉöÆĶŗ`éĄé─é©éŁé╠é═Źóō’é╚é╠é┼üAīŗŹćé╔éµé┴é─ĢČÄÜéĢ\ī╗éĘéķüB
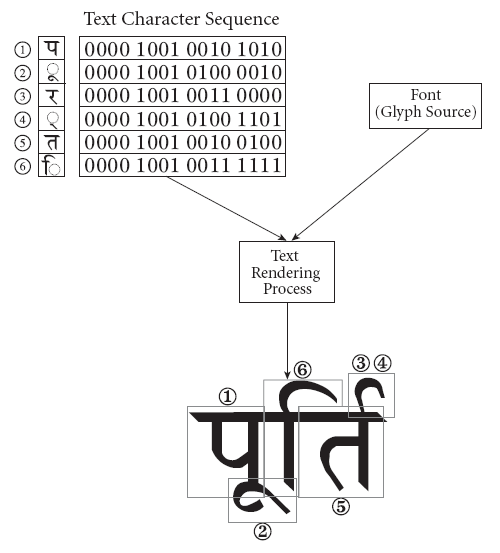
īŗŹćĢČÄÜé╠Śß
é▒éĻé═āfü[āöā@āiü[āKāŖü[ĢČÄÜéīŗŹćĢČÄÜéŲéĄé─Ģ\ī╗éĄé─éóéķŚßüBUnicodeé╠ÄdŚlÅæé®éńł°ŚpüB6é┬é╠UnicodeĢČÄÜéō³Ś═éĘéķéŲüAŹ┼ÅIōIé╔é═é▒é╠éµéżé╚ĢČÄÜé¬Ģ\Ä”é│éĻéķüBÆPÅāé╔ŹČé®éńēEéųĢ└é±é┼éóéķéŲéóéżéĒé»é═é╚éŁüAéĀéńé®éČé▀ātāHāōāgéŲéĄé─ÆĶŗ`éĄé─é©éŁé╠é═ō’éĄéóüB
ü@ĢČÄÜł╚ŖOé┼éÓüAŚßé”é╬ŖGĢČÄÜātāHāōāgé╔é©éóé─üAāJāēü[æ«É½éÄwÆĶéĘéķéĮé▀é╔üAé▒é╠ĢĪÉöé╠UnicodeĢČÄÜéÄgé┴é─ĢČÄÜé╠ÅCųéĢ\éĘé▒éŲé¬éĀéķüB
ü@īŗŹćĢČÄÜ錜ŚpéĘéķéŲüAī│é╠Unicodeé╔é╚éóé│é▄é┤é▄é╚ĢČÄÜéŌŗLŹåé╚éŪéĢ\ī╗é┼é½éķé¬üAāVāXāeāĆéŌātāHāōāgé╔éµé┴é─é═éżé▄飳Ąé”é╚éóé▒éŲéÓéĀéķüiŚßé”é╬ĢĪÉöé╠UnicodeāRü[āhé®éńé╚éķĢČÄÜééżé▄éŁĢęÅWé┼é½é╚éóé╚éŪüjüBé▄éĮīŗŹćĢČÄÜéÄgéżéŲĢČÄÜé╠ā\ü[āgé╚éŪé¬ō’éĄéŁé╚éķé╠é┼üAŖŅÅĆéŲé╚éķĢČÄÜéŠé»éæ╬Å█é╔éĄé─ā\ü[āgéĘéķĢ¹¢@éŌüAŹ┼Åēé╔üuÉ│ŗKē╗üvÅłŚØéĄé─é®éńā\ü[āgéĘéķĢ¹¢@é╚éŪéÓŗKŖié┼ÆĶŗ`é│éĻé─éóéķüB
ł┘æ╠ÄÜāZāīāNā^
ü@Śßé”é╬ōīŗ×ōsüué®é┬éĄé®éŁüvéŲō▐ŚŪī¦üué®é┬éńé¼éĄüvé╠éµéżé╔üAō»éČŖ┐ÄÜé┼éÓÅææ╠鬳┘é╚éķéÓé╠é¬éĀéķüiŖŗųŗµé╠ī÷Ä«āTāCāgüwüuŖŗüvé╠ÄÜé╠ĢsÄvŗcüxüAŖŗÅķÄsé╠ī÷Ä«āTāCāgüwüuŖŗüvé╠ÄÜé╔é┬éóé─üxÄQÅŲüjüBé▒éĻéł┘æ╠ÄÜéŲéóéżüBUnicodeéŌé╗é╠ŖŅéŲé╚é┴é─éóéķJISāRü[āhé┼é═üAé▒éĻéńé╠ł┘æ╠ÄÜé╔ō»éČĢČÄÜāRü[āhéŖäéĶō¢é─é─éóéķéĮé▀ŗµĢ╩é┼é½é╚éóüB
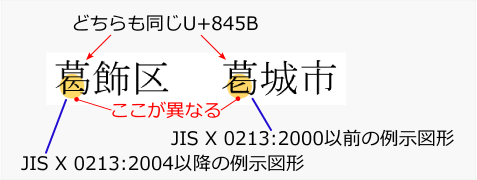
ł┘æ╠ÄÜé╠Śß
U+845BüiJISāRü[āhé┼é═336BüAShift_JISé┼é═8A8Büjé╠ĢČÄÜé╔é═2é┬é╠ł┘æ╠ÄÜé¬éĀéķüBé╗éĻé╝éĻé╠Ä®ÄĪæ╠é═ł┘é╚éķÄÜæ╠éÉ│Ä«é╚Åææ╠ü^āŹāSéŲéĄé─é©éĶüAÄgŚpéĘéķāVāXāeāĆéŌātāHāōāgé╔éµé┴é─Ģ\Ä”é¬ĢŽéĒé┴é─éĄé▄éżéŲéóéżĢsōsŹćé╔ŹóśféĄé─éóéķüB
ü@é▒é╠éµéżé╚ÅĻŹćé╔é═üAUnicodeé┼é═üuł┘æ╠ÄÜāZāīāNā^üiIdeographic Variation SelectorüFIVSüjüvéŲéóéżÆlüiŖ┐ÄÜŚpé═U+E0100ü`U+E01EFüjéŖYō¢éĘéķĢČÄÜé╠Æ╝īŃé╔ÆuéŁé▒éŲé╔éµé┴é─üAéŪé╠ł┘æ╠ÄÜ錜ŚpéĘéķé®éæIæé┼é½éķéµéżé╔éĄé─éóéķüB

ł┘æ╠ÄÜé╠āTā|ü[āg
üuIdeographic Variation DatabaseüvéµéĶł°ŚpüBU+845Bé╠Æ╝īŃé╔U+E0100é®U+E0101éÆuéŁé▒éŲé╔éµéĶüAĢ\Ä”é│é╣éĮéół┘æ╠ÄÜéæIæé┼é½éķüB
Unicodeé╠ĢäŹåē╗Ģ¹Ä«üFUTFüiUCS Transformation Formatüj
ü@UnicodeĢČÄÜéĢäŹåē╗éĄé─āXāgāīü[āWé╔Ŗiö[éĄéĮéĶüAÆ╩ÉMśHéÄgé┴é─æŚÄ¾ÉMéĄéĮéĶéĘéķé╔é═üAēĮéńé®é╠Ģ¹¢@é┼üAāoāCāgāXāgāŖü[āĆüi1byteé▓éŲé╠āfü[ā^é╠Ģ└éčüjé╔ĢŽŖĘéĘéķĢKŚvé¬éĀéķüBUnicodeé┼é═é▒é╠éĮé▀é╠Ģ¹¢@éÓŗKÆĶéĄé─é©éĶüAUTF-8éŌUTF-16üAUTF-32é╚éŪé¬éĀéķüBé▒éĻéńé╔é┬éóé─é═üATech BasicsüuUTF-8üvéÄQÅŲé╠é▒éŲüB
Copyright© Digital Advantage Corp. All Rights Reserved.