今どきCPUだけで大丈夫?ビッグデータや人工知能でGPU/FPGAを使う前に知っておきたい“ハード屋”と“ソフト屋”の違い:特集:インフラエンジニアのためのハードウェア活用の道標(3)(1/2 ページ)
ソフトウェア技術者の間でもGPUやFPGAに対する興味が高まっている。「ハードウェアの“特質”とは何か」「GPUやFPGAの性能を生かすソフトウェアは、どうあるべきか」@ITの人気連載「頭脳放談」の筆者に聞いた。
GPUとは、FPGAとは
コンピュータは常に、より高速な性能を追い求めることで進化してきた。中でもコンピュータの中核をつかさどるCPU(Central Processing Unit)は、クロック数の向上やマルチコア化、マルチスレッド化によって劇的に処理速度を向上させてきたが、それでもまだ「重たい」処理は残る。ビッグデータ解析や機械学習、ディープラーニング、人工知能(AI)、レイテンシにシビアな超高速取引などが、その典型例だ。
このような「重たい」処理をオフロードし、並列処理によって桁違いの高速化を実現しようとしているのがGPUであり、FPGAだ。
GPUは「Graphics Processing Unit」という名称が示す通り、もともとは画像処理に特化したプロセッサだ。だがNVIDIAの「CUDA」(Compute Unified Device Architecture)などの登場を機に、高い並列計算能力を汎用的な計算に生かし、HPC(High Performance Computing)/スーパーコンピュータをはじめ、データセンター向けサーバの世界でも採用され始めている(参考)。
一方のFPGA(Field Programmable Gate Array)は、一言で言ってしまえば「プログラミング可能な半導体」だ。以前は高価だったFPGAだが、現在は徐々に価格が低下してきている。CPU/GPUに比べて消費電力を抑えられるという点で優位なことから、GPU同様、機械学習をはじめとするさまざまな分野への応用が期待されている(参考:頭脳放談 第181回 Intelが167億ドルで手に入れるもの)。
こうした動きを背景に、ソフトウェア技術者の間でもGPUやFPGAに対する興味が高まっている。中でも関心が高いのは、「GPUやFPGAといったハードウェアの“特質”とは何か」「GPUやFPGAの性能を生かすソフトウェアやアプリケーションは、どうあるべきか」といった事柄ではないだろうか。@ITの人気連載「頭脳放談」の筆者であり、x286時代から「ハードウェア屋」としてさまざまなプロセッサやデバイスの設計に携わってきたトプスシステムズ マイクロプロセッサ事業開発部 部長の泉田正道氏に聞いた。
CPUとGPUとFPGA、それぞれの特性とは
GPUやFPGAが求められる背景には、これまでとは桁違いの演算量が要求されるアプリケーションの需要が増していることが挙げられるだろう。具体的にはHPCに始まり、ビッグデータ解析や機械学習、ディープラーニング、AIといった大量の演算を要する用途や、超高速取引のように極限まで低レイテンシが求められる分野だ。「例えばCPUなら4〜5日かかっていたものが、GPUならその日のうちに計算ができます。超高速取引で求められる毎秒2000回といったレベルの演算は、もはやGPUでも間に合わず、FPGAが採用され始めています」(泉田氏)。
GPUやFPGAでは、なぜこれほど高速な演算処理が可能なのだろうか。
まずCPUとGPUの違いだが、泉田氏は要は「『if〜else〜』ができるか、『for』ループが得意か」だと説明する。
CPUは、OSのように複雑なプログラムを動かすことを念頭において作られてきた。従ってフレキシブルにプログラムを動かせるのだが、演算器の間でメモリをシェアする仕組みなので、コアの増加に伴い性能が頭打ちになってしまうことが欠点だ。メモリを階層化するなど、互いに邪魔せずに処理できるよう工夫は凝らされているが、それでも限界はある。
これに対しGPUは、「難しい処理ができる大きいものではなく、演算器だけ取り出したものを何百個と並べ、1度に処理するもの。そりゃ速いわけですよね」(泉田氏)。
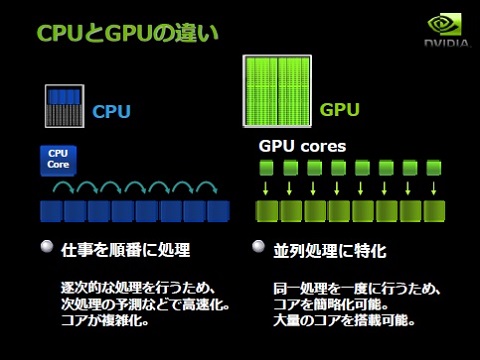
「GPUが非常に適しているのはfor文の処理です。ソフトウェア処理において重たいのがforループですが、forループが100万回あれば、GPUはそれを1000個の演算器で等分してばらばらに並列処理できる。だから非常に速いんです」
逆に、if文のような条件判断は不得手だ。「forループの中に依存関係があり、ループ1の結果をループ2が取って……といった処理をやらせようとすると、途端に遅くなってしまいます。同じことをざっと皆にやらせる分には速いけれど、細かく条件判断して難しいことをやろうとすると、GPUはがくっと効率が落ちます」(泉田氏)。
GPUでもif文的な処理ができないことはないが、「特定の処理だけを走らせ、それ以外は止めることによって疑似的にif〜else〜を再現しているだけ」と泉田氏。だからこそ、NVIDIAをはじめとするGPUメーカーは、こうしたGPUの特質を考えた、依存関係をなくしたアルゴリズムを推進し、それを組み込めるSDKをリリースしている。
一方、FPGAには、どんな特質があるのだろうか。
「あるロジックの状態に演算器を並べ、並列して計算できるのだから、これは当然速くなりますよね」と泉田氏は述べた。対象は何にせよ、ひとたびロジックをハードウェアに落とし込むことができれば、何十倍、何百倍と処理速度を高めることが可能だ。しかも「かつてはASIC(Application Specific Integrated Circuit)に落とし込んでいましたが、もし失敗すれば、3〜4カ月かけてきた時間と何千万というコストがパアになってしまうリスクがありました。けれどFPGAならば、一晩あれば作り直しが可能です。その意味でハードルはすごく下がっています」(泉田氏)。
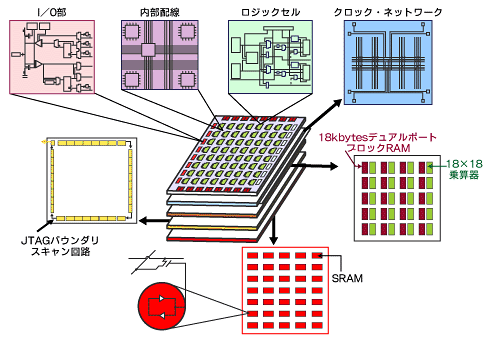
雑に書けばそれなりに、しかし突き詰めようとすると困難な高速化
このようにGPUとFPGA活用のハードルが下がってきた今、「ハードウェア技術者がやっていたことをソフトウェア技術者に引き受けてもらい、技術者が『AIとか何だとか、ビジネスになるソフトウェアを書け』と言われる時代になっていると思います」(泉田氏)。
事実、GPUを意識したソフトウェアを書く作業は、以前に比べ、さほど難しいものではなくなったという。「良いツールが出て、コンパイラも改善されているので、あまり難しいことを考えなくても、ある程度の高速化ならば可能」と泉田氏は述べた。
しかし、ハードウェアの性能を限界まで引き出そうと思うならば、一筋縄にはいかない。「ずぼらにやるなら、適当に書いてもforループが速くなるのでそれでいいでしょう。けれど“アムダールの法則”の通り、10のうち8割を並列化して高速化できても、2割が残っていれば全体の性能は5倍ぐらいにしかなりません」(泉田氏)。何十倍というレベルの高速化を実現するならば、並列化の割合を9割8分程度まで上げる必要があるが、「既存のアルゴリズムは並列処理を前提として考えられたものではないため、GPUで実現できる性能向上はせいぜい20倍といったところではないでしょうか」(泉田氏)。
一方FPGAにも考慮すべきポイントがある。よく「FPGAは電力消費が少ない」と言われるが、実は、1+1しか計算してしない状態でも一定の電気を消費してしまうという。「同じ性能を実現するのにCPUやGPUだったらここまで消費する、というところまで使い切らないとペイしません。その辺りをきちんと設計しないと十分な効果が得られないんじゃないでしょうか」(泉田氏)。
「『100のリソースを持つハードウェアのうち、10〜20くらいまで使えればいい』ならば、それほどハードウェアのことを知らなくても動いてくれると思います。けれど『100あるうち50まで、できればそれ以上使っていきたい』となると、ハードウェアの世界にぐっと入り込む必要があります」
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 「Big Sur」はニューラルネットワークシステムのためにフェイスブックが設計したハードウエア
「Big Sur」はニューラルネットワークシステムのためにフェイスブックが設計したハードウエア
米フェイスブックは「ニューラルネットワークシステム向け」というハードウエアアーキテクチャ「Big Sur」をオープンソースで公開した。 AWS/Azure上でTensorFlow、CNTKを――機械学習環境のマネージドサービスが登場
AWS/Azure上でTensorFlow、CNTKを――機械学習環境のマネージドサービスが登場
クラスキャットが、機械学習環境のマネージドサービス「ClassCat Deep Learning Service v2」の提供を発表した。Amazon Web ServicesとMicrosoft Azureに対応する。 ザイリンクス、OpenCL、C/C++でFPGAアクセラレーションを行う開発環境最新版のリリースを発表
ザイリンクス、OpenCL、C/C++でFPGAアクセラレーションを行う開発環境最新版のリリースを発表
ザイリンクスは5月26日(米国時間)、FPGAを使用したアクセラレーター開発環境の最新版「SDAccel開発環境2015.1」のリリースを発表した。最新版では、統合開発環境の機能が強化され、対応ライブラリも拡充される。