デジタル時代、ビジネス差別化に欠かせない「データ資産化」の要件とは?:一般企業も待ったなし。「データはあるが生かせない」に終止符を
IoT/ビッグデータの取り組みが本格化し、「大量データからいかに価値を引き出すか」「有効なアクションにつなげるか」が、企業収益を左右する一大要件となっている。だが、データを蓄積していても有効活用できていないケースは非常に多い。その真因とは何か? データの蓄積基盤となるデータレイクにフォーカスしながら、「データを資産化できない」本当の理由を探る。
デジタル時代を勝ち残るカギ、「データの資産化」実現のカギとは?
IoT、X-TechなどDX(デジタルトランスフォーメーション)が各業種で進展している今、データ活用の在り方がビジネス差別化の一大要件となっている。大量の構造化データ/非構造化データに埋もれた価値を、いかに迅速に発見し、精錬し、収益向上の源とするか――すなわち「データの資産化」を実現することが、多くの企業にとって待ったなしの状況になっているのだ。
これを実現する上で、不可欠となるのが大量データの活用基盤となる「データレイク」だ。しかし、多くのメディアやベンダーが、データレイクの重要性を訴求してはいるものの、単にデータを蓄積するだけでは「資産化」につながらないことはあまり言及されていない。実際に「データを貯めてはいるが、ビジネスに生かせていない」ことが多くの企業において課題となっている。
では一体、データを資産化できるデータレイクと、できないデータレイクにはどのような違いがあるのだろうか? データレイクに関して深い知見を持つ、日本アイ・ビー・エム(以下、IBM) アナリティクス事業部 Product&Solutionの担当者に話を聞いた。
今あらためて「データレイク」とは何か?
IBMでは「データの資産化」が求められる背景として、現場のデータ利活用のニーズの高度化を指摘した上で、例を挙げて次のように解説する。
「業務部門ごとにデータの活用目的や分析の視点は異なります。例えばマーケティング部門のように、『キャンペーンを成功させる』という目的もあれば、財務部門のように『リスクの高い経営課題を探る』といった目的もあります。営業部門でも、従来からある販売データや顧客の分析ニーズだけでなく、例えば『顧客カバレッジモデルを最適化するには?』といったような、高度な分析が求められています。人事部門においても『人材流出を防止するには?』といった課題に取り組んでいて、やはり分析ニーズのレベルは高くなっています」
このように多様化・高度化した分析ニーズを満たすためには、現場の担当者による「セルフサービス・アナリティクス」が必要だ。だが、「データマートやデータウェアハウスのような従来型のデータ蓄積・分析基盤では、そのスピードに追従することが難しくなっている」という。
「セルフサービス・アナリティクスの世界では、各部門のスタッフが、自分の目的・観点に応じてデータを分析できる環境が必要ですが、それを実現するためには、まず、社内外のありとあらゆるデータを、形式を問わず丸ごと蓄積しておき、利用者がいつでも利用できるようにしておくことが必要となります。その考え方が『データレイク』です」
では従来型のデータマート・データウェアハウスではなく、データレイクが求められる理由とは何か。
「従来は事業部門のリクエストを受けて、IT部門が『データの倉庫』であるデータウェアハウスから必要なデータを取り出してきて、用途に応じて分析しやすいよう加工したデータマートを提供してきました。ここには大きく2つの課題があります。1つはデータの準備に時間がかかること。IT部門にデータの取り出し・加工をしてもらっている間に、市場環境が変わってしまい、準備ができたころには既に役立たなくなっている、といったことも少なくありません。もう1つは特定の用途に応じて準備されたデータであること。市場変化が速く先を見通しにくい今、『どのデータが、どう収益向上につながるか』は予測しにくく、ビジネスの現場の人間にしか分からないことも多い。そうなると、現場の事業部門のスタッフはさまざまなデータを使ってトライ&エラーを行いたくなるのです。IT部門としては、特定の用途に応じた『必要な』データの準備だけでなく、『必要になるかもしれない』という潜在的なニーズにも対応しなければなりません。そこで『データレイク』という考え方が生まれました」
ただ、データレイクに対する誤解は少なくない。例えば、「セルフサービスBI」を導入しており、データを自由に分析・活用できるようにしてあるので、データレイクは不要という考え方だ。
だが、セルフサービスBIは、ビジネスユーザーがGUIツールを使ってデータへアクセスできるようになるため便利ではあるが、それはあらかじめ分析用としてIT部門が準備したデータがあるから成り立つ。ユーザーが自由にトライ&エラーができる「セルフサービス・アナリティクス」および、それを支える「データレイク」の考え方とは、明確に異なる。
この点について、IBMの担当者は例え話を用いてデータレイクの概念をシンプルに示す。
「データウェアハウスは生データの倉庫、データマートは加工したデータの市場です。データを魚に例えるなら、プロが事前に料理まで考えて、倉庫から必要な魚を取り出し、切り身などに加工してくれたものといえます。一方、データレイクは湖です。生きた魚が泳いでいて、ユーザー自身が必要な時に魚を釣り上げて、好きなように調理することができます。つまり、事前に用途に応じて準備されたデータではなく、ユーザー自身が状況に応じて必要なデータを自由に取得し、自身で加工・分析できる形にすることがデータレイクの大きなポイントなのです」
セルフサービスBIが「使われないシステム」になってしまう問題の原因は、次々に出てくる分析ニーズに追随するための”データ準備のスピード”を維持できないためであり、「分析する側のツール」がどんなに良くても「分析される側のデータがそろっていないと意味がない」という現象を端的に表している例と言えるだろう。

図1 データウェアハウスはデータの倉庫、データマートは加工されたデータの市場。ともにIT部門によって準備されたデータであり準備には時間がかかる。データレイクは、生のデータをユーザー自身が取得でき、自由に加工・分析できる環境を指す。魚に例えれば、切り身などに加工されたものを買ってくるのではなく、湖の中から必要な魚を捕まえて自由に加工・調理するイメージ《クリックで拡大》
一方で、「データレイクは、どのようなデータでもとりあえず放り込んでおく場所」という誤解も多い。例えば、安価なクラウドストレージやHadoop環境に大量データをひたすら蓄積するというアプローチだ。これもデータレイクとは呼べない。
「データを蓄積するという意味では同じですが、データが整理整頓されているか否かに大きな違いがあります。ひとまず生データを置いておくというアプローチだと、結局、使えないデータが貯まるだけの意味のないデータレイクになってしまいます。これは、もはや湖ではなく、泥やゴミなどが堆積した沼地(データスワンプ)です。データを資産化するためにはデータを整理整頓し、ガバナンスの効いた状態、つまり正しいデータを常時ユーザーに提供できる状態で保管し、データレイクをきれいな状態に保つことが不可欠なのです」
データレイクに求められる3つの要件とは?
こうした誤解が解ければ、データレイクに求められる要件も自然に導き出すことができる。要件は大きく3つ。1つは、社内外のあらゆるデータをユーザー自身が取得・分析できるようにするための「データ統合」だ。特に「ETL処理」や「クレンジング処理」が重要となるが、データレイクでは扱うデータの種類と量が圧倒的に多くなるため、これらの処理を高速に実行できるための仕組みと、処理の流れを定義する作業の生産性を上げることが必要となる。
2つ目は、データの沼地ではなく「湖」を実現するための「データガバナンス」。このためには「データの流れの見える化」や、データの出自を明らかにする「プロファイリング」、データの品質を定期的にチェックする「モニタリング」、データを全社共通の正しい言葉で管理し、ビジネスユーザーが必要なデータに確実にアクセスできるようにするための「カタログ」などが求められる。
IBMの担当者は、データレイクで求められるこれらの要件について、今度は魚ではなく、湖の水に例えて解説する。
「湖は、周囲の山々にあるさまざまな水源から水が流れ込んで形成されます。そこでは、きれいな湖を作るためには、水源からどのように水を引いてくるかという『データの流れのデザイン』、水源の状態を確認する『プロファイリング』、水がどこからどう流れて来たかという『データの流れの見える化(来歴分析・影響分析)』、そして沼地にならないよう水質を維持する『モニタリング』が、データガバナンスの観点から重要になります。これで『正しいデータを正しい状態でユーザーに提供する』ことが可能になりますが、セルフサービス・アナリティクスを実現するために、もう1つ必要となるのが『カタログ』です」
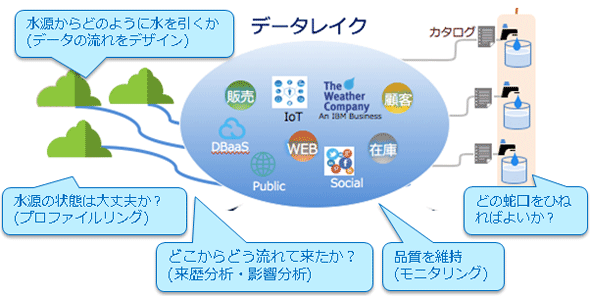
「ビジネスユーザーがデータを利用するとき、蛇口をひねれば水が出るようなイメージで、ユーザー自身が“信頼できるデータ”をいつでも簡単に利用できるようにする仕組みが必要になりますが、その際に『どの蛇口をひねると、どのデータが出てくるのか』ということが明確になっていなければなりません。そのために、『カタログ』を用意して、ビジネス用語の定義およびビジネス用語とデータのマッピング情報を公開することで、ITが苦手なビジネスユーザーでもデータレイクを正しく利用できるようにしなければならないのです」
これらを踏まえると、システム要件は次のように整理することができる。
データ統合の要件
- 大量データの統合処理
- クレンジングの高速処理
- 生産性の高いETL処理定義
データガバナンスの要件
- データの流れを見える化する来歴分析と影響分析(データリネージュ)
- データ品質を向上するためのプロファイリングとモニタリング
- ビジネス用語辞書によるビジネス用語とデータのマッピング(カタログ)
ただし、データレイクを実現する上では、もう1つ大きなポイントがある。それが3つ目、データ統合とデータガバナンスの連携だ。「この点が、データを資産化できるデータレイクと、できないデータレイクの最大の違い」なのだという。
「データレイクのデータには、高頻度で利用される『鉄板』のデータがあり、一方で、『利用されるかもしれないため加工せずに一旦そのまま置いておく』というデータもあります。前者のデータを考えると、データガバナンスの徹底だけに注力しても“現場にとって使いやすいデータ”にはならないのです。このような種類のデータは、従来のデータマートと同様に、しっかりとETLやクレンジングによる加工を含む『データ統合』処理を行うことで利便性を担保できます。そして、『データ統合』処理を『データガバナンス』機能と連携させることで、データ品質を高めることができ、データの流れを『見える化』して、データの『正しさ』を担保することができるのです」
一方、データの「カタログ」については、できる限り多くのデータを対象にして、タイムリーな状態で管理する必要がある。ビジネスは常に動いているため、データレイク内にある各種データと“今使われているビジネス用語”との乖離が発生することがある。そうなると、ビジネスユーザーは「カタログ」経由でデータへアクセスできなくなってしまい、データを利活用できなくなってしまう。そのため「カタログ」は網羅的かつ正確な内容で管理されなければならず、データ統合の仕組みとシームレスに連携する必要が出てくるのである。
「データレイクを作る上で重要なのは、データ統合とデータガバナンスを1つの体系で管理していくことです。そこで弊社では『統合とガバナンス』に必要な全機能をバラバラに提供するのではなく、単一のリポジトリを使って統合的に全要件を満たすアプローチを提案しています」
共通リポジトリによる統合管理が強み。データレイクを実現する「Information Server」
こうしたコンセプトの下、IBMが提供しているのがデータレイク基盤を構築するための製品群「Information Server」だ。データ変換加工のための「DataStage」、クレンジング(名寄せ)のための「QualityStage」、メタデータを管理してデータの流れやビジネス用語とデータの関連をカタログ化する「Information Governance Catalog」、データ品質を調査分析し、モニタリングする「Information Analyzer」などで構成される統合製品がInformation Serverである。

最大の特徴は、各製品が共通のリポジトリを利用して、各種データを管理するためのメタデータを一元管理することで、機能をシームレスに連携させている点だ。これにより、データ統合からデータガバナンスまでを一貫して実現し、「データレイク」の基礎部分としての全要件を満たせるようになっている。

ただし、Information Serverは「データの資産化」に向けて、データレイクの基礎部分を構成する製品という位置付け。この点についてIBMは、「弊社としての目標は、データレイクを構築すること自体ではなく、データレイクが支えるセルフサービス・アナリティクスの実現によってお客さまの競争力を高めることにあります」と強調する。

お客さまの競争力を高めるためのデータレイク実現に向けて、ロードマップを提案
「現状のデータ基盤が沼地のようなものだったとしても、企業を強くするという最終ゴールに向けて、データレイクによるセルフサービス・アナリティクス基盤の実現まで、無理なく支援することが弊社の目標です。そこで各社各様の状況・目的に応じたロードマップを提案しています」
アプローチは大きく3つに分けられるという。1つは、既存の分析基盤の高度化に軸足を置きながらデータレイクを整備していくアプローチ。2つ目は既存のデータウェアハウスを活用しながら“沼地”の状態を段階的に湖へと改善していくアプローチ。3つ目は、コスト効率が悪い既存のビッグデータ基盤の改善を主眼に、データレイクを目指していくアプローチだ。

これらを実現する上で、Information Serverを軸としながら、総合的に各種製品を提供できることも同社の強みだという。例えば「分析基盤の高度化」に軸足を置くなら、データマイニングや予測分析を得意とする「SPSS Modeler」、データサイエンスプラットフォームとして分析に関わるチームのコラボレーションを支える「DSX (Data Science eXperience)」、ビッグデータに対応し日本語にも強いテキストマイニングツール「Watson Explorer」などを用意できる。「分析する側」のツールを高度化して、まずはビジネス成果を挙げ、それと並行して「分析される側」のデータレイクを構築するというアプローチである。
さらに、「分析した結果を『業務に適用する』部分も重要になってくる」という。
「例えば、データサイエンティストがDSX上で新たに作成した『分析モデル』を組み込んだ業務アプリケーションを、クラウド上でクイックに立ち上げることが可能です。それは、IBMがBluemixをはじめとするクラウドテクノロジーをご提供できるからです。また、Watson APIと連携させることで、高度な意思決定支援を行える『コグニティブ・アプリケーション』を開発することも可能です。このように業務に適用するためのソリューションまで含めて、トータルにご提案できるのも、IBMの強みです」
「企業として強くなるため」に、IBMは全方位からデータの資産化をサポート
共通リポジトリによるシームレスな製品連携と、企業の競争力強化というゴールを見据えた統合的なソリューション提供という2つの強みは、実際に多くの企業から高い評価を受けているという。
例えば、ある国内銀行ではマーケティングの高度化を実現する基盤としてデータレイクを構築している。情報サービス業の例では、保険業務における財務・資産運用システムのデータ品質を確保し、データガバナンスを強化するため、Information Serverを導入し、データの正確な用語・意味を共通化して定義するメタデータ管理やビジネス用語辞書の整備などを行っているという。
一般に、これまでのデータ活用事例では「データの可視化」や「状況の把握」にとどまり、有効なアクションにつなげられていない例が目立ってきた。前述のように、セルフサービスBIを導入したものの、データソースが限定的であるため、本来行いたい分析ができないという声も多い。データレイクについても、構築はしたが沼地化しており、データを有効活用できる状況にないというケースが目立つ。
その点、今回紹介した「データレイク」の定義や要件、データレイクを使ったセルフサービス・アナリティクス実現に向けたロードマップは、多くの企業にとって非常に参考になるものだろう。
「IBMでは、データを資産化することで企業として強くなるために、全方位からお客さまをサポートすることができます。これからデータを貯めようという企業、あるいは、データは貯めたが有効活用できていないという企業、それぞれの状況に最適な支援をしていきたい考えです」
プロに加工してもらうのを待つことなく、ユーザー自身が新鮮な魚をいつでも簡単に捕まえ、目的に応じて柔軟に調理・加工し、アクションにつながる分析ができる――真のデータレイクが実現したとき、データは企業にとって欠かせない資産となっているはずだ。
資料ダウンロード
10分で分かる「データレイクの作り方」 データマートと何が違う?
ビッグデータをはじめとする社内外のデータを分析し、マーケティング部門や営業部門、財務部門など現場の意思決定に活用したい。こうした企業のニーズに応えるデータ管理戦略として注目されているのが「データレイク」だ。
DWHとは異なる「ガバナンスを効かせたデータ基盤」とはどのようなものか?
急増するデータや現場でのデータ活用などの課題を抱えるデータ基盤。これらの課題を解決するためには、ガバナンスを効かせた「データレイク」が必要だ。その実現に向けたベストプラクティスを紹介する。
提供:日本アイ・ビー・エム株式会社
アイティメディア営業企画/制作:@IT 編集部/掲載内容有効期限:2017年8月17日
Copyright © ITmedia, Inc. All Rights Reserved.
