機械翻訳は、翻訳家の仕事を奪うのか――「人工知能」を作る上での良質な栄養素とは?:ものになるモノ、ならないモノ(80)(1/2 ページ)
外国語を翻訳するときに使う「機械翻訳」。ニューラルネットワークによって精度が上がったものの、人間の助けはまだまだ必要だ。さらなる精度向上をするには、何が必要なのかGengoプロダクト部長のチャーリー・ワルター氏に話を聞いた。
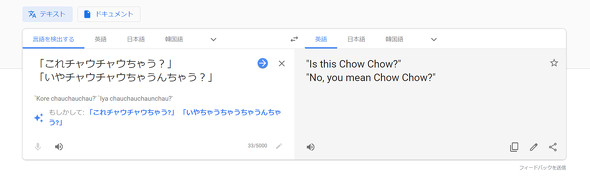
「これチャウチャウちゃう?」
「いやチャウチャウちゃうんちゃう?」
自然言語処理について考える際、こんな大阪弁のやりとりが頭をよぎることがある。大阪弁をユーモラスに紹介するフレーズとしてご存じの方も多いであろう。念のために標準語に翻訳するとこうなる。
「これはチャウチャウ(犬種)ではありませんか?」
「いいえチャウチャウではないと思います」
試しに、上記大阪弁をGoogle翻訳に入力してみると、下部に「もしかして」と表示され、原語の候補が「これチャウチャウ〜」と現れる。メジャーな言い回しなので、このフレーズの翻訳を試してみる人が多い故の候補表示なのだろう。そのGoogleの翻訳が適当かどうかは、各自お試しいただくとして、約2年前にGoogle翻訳が急に賢くなったタイミングがあったことを覚えておいでだろうか。
2016年11月、Googleは、翻訳システムにおいて「GNMT」(Google's Neural Machine Translation)の稼働を発表した。その名が示す通り、ニューラルネットワークによる機械翻訳が導入された。これを公表した際のブログ記事を要約すると、「以前は、フレーズベースでの翻訳を行っていた。GNMTでは、文章全体の文脈を把握した上で翻訳を行い、言葉の順番を変えるなどの調整を実施することで、より正しい文法で、かつ人の言葉に近いアウトプットが可能になった」そうだ。
確かに、以前の機械翻訳と比較すると、言葉遣いが自然になった。ユーザーからすると頼もしい限りだし、今後どこまで進化するのか楽しみである。その一方で、機械翻訳の世界では、翻訳精度の向上(学習)のためには、まだまだ、人間が介在しなければならない状況にあるのも事実だ。
例えば、これが将棋や囲碁の人工知能(AI)の世界だと、AIが自分自身で対局を積み重ねることで自ら学習し、人間との対決において圧倒的な強さを身に付けるようになった。実際、DeepMindの「AlphaGo」とプロ棋士との対決、成長の歴史は有名だ。ただ歴史と言っても、AlphaGoが表舞台に登場したのが2015年10月で、後述する「勝利宣言」に至るまで2年もかかっていない。
AI自身、つまりアルゴリズム同士が対局を高速でシミュレーションし、短時間のうちに数十万局という試合を行うことで、とてつもない量のデータを蓄積し、学習する。人間がまったく歯が立たない領域がそこに存在する。結局、AlphaGoの圧倒的な進化の前に人間は為す術を失った。2017年4月の世界最強の棋士と呼ばれる柯潔(カ・ケツ)との対局を最後に、「対人間対局」の終焉(しゅうえん)を宣言したのは有名な話。実際に宣言したのは、AIではなくDeepMindの創業者であるデミス・ハサビス氏なのだが、事実上の人間に対する勝利宣言である。
人間にあって機械学習に不足しているものは何か?
話をGoogleの機械翻訳に戻そう。GNMTもAlphaGoのように自分自身で学習し、より進化するのだろうか。そして、近いうちに、人間の翻訳家に対し「あなたたちは必要ありません」と勝利宣言を行う日が来るのか。現時点での答えは「ノー」だ。翻訳精度の向上や自然な言葉遣いの実現には、前述のように人間の助けが必要だからである。
囲碁や将棋のように普遍的なルールがあれば、「勝利」という唯一無二の目標に向かって判断と失敗、成功を繰り替す中でAI自身が学習できる。だが、翻訳、ひいては自然言語処理の分野では、正解は一つではない。ましてや、さらに突っ込んだ翻訳、例えば文学的な文章や、TwitterをはじめとするSNSの投稿、人と人との会話といった領域にまで対象を広げると、それらを自然な言葉に訳すには、文章や文脈から人間の曖昧な感情を読み解き、ふさわしい言葉を紡ぎ出さなければならない。
GNMTのバックエンド、つまりユーザーからは見えない部分に潜むGoogleの大規模GPU群など巨大なリソースをもってしても、AI自身が人間の曖昧な感情を自ら学習し、進化するのは簡単な話ではないはず。翻訳のエンジンは、人間の脳の神経細胞の仕組みを模したニューラルネットワークモデルなので、いつかはその領域にまで到達する日がやってくるのかもしれないが、まだまだ先の話になりそうだ。
では、人間にあって現在の機械学習に不足しているものは何かというと、「脳の可塑(かそ)性」なのではないか。脳が「状況に応じて柔軟に変化する性質」といった意味だが、「汎用(はんよう)性」と言い換えることもできる。ある箇所で学習した情報をまったく異なる分野や状況で応用的に利用できることが、人間の強みといえる。
極めて単純な例ではあるが、次の文章を見てほしい。
- Queen Elizabeth II is the longest-reigning monarch.
- Queen is famous for Bohemian Rhapsody.
1つ目は、英国の女王について語っている。2つ目は、ロックバンドのQueenについての文章だ。だが、筆者が2つ目の文章をGoogle翻訳で和文にしたところ「女王はボヘミアン・ラプソディーで有名です」と訳された。人間がこの文章を翻訳する場合、過去の知識や経験に裏打ちされた可塑性を発揮することで「ロックバンドのQueen」と「女王」を正しく使い分けることができるが、GNMTは素直に「女王」と訳した。
仮に、音楽にはまったく興味のない翻訳者が訳した場合は、もしかしたら「女王はボヘミアン〜」とする可能性も否定はできない。だが、常識的な翻訳者であれば、「エリザベス女王」と「ボヘミア人の狂詩曲」などという意味的な組み合わせに違和感を覚え、掘り下げて調べるであろう。そして「Queen」の正しい意味に到達するのではないか。それが、可塑性であり汎用性なのだ。
ここで、GNMTの名誉のために加筆すると、スマートフォンなど端末を変えて試すと、状況によっては「Queenはボヘミアン〜」と、「Queen」をロックバンドの名前として認識していると思われるアウトプットを返すときもあった。とはいえ、このようなゆらぎが発生すること自体、翻訳サービスとしてなんとも頼りなくもあり、発展途上感がただよう。
ここでは、Google翻訳を取り上げたが、Microsoft、百度(バイドゥ)、情報通信研究機構(NICT)などもニューラルネットワークによる翻訳を提供している。まだまだ、人間には及ばないとはいえ、ニューラルネットワークは現時点での機械翻訳の最適解といったところだろう。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 成功した人が幸せになるのではなく、幸せな人が成功する――IoTで幸福度は定量化できるのか
成功した人が幸せになるのではなく、幸せな人が成功する――IoTで幸福度は定量化できるのか
つかみどころのない「幸福度指数」をなんとか定量的に計測できないか。そして、それを職場の幸福度向上に生かせないかというプロジェクトがある。日立製作所フェロー・理事、IEEE Fellow、東京工業大学大学院情報理工学院特定教授の矢野和男氏に聞いた。 翻訳系API「Translator API」の使い方と2017年2月現在のWatson、Google翻訳との違い
翻訳系API「Translator API」の使い方と2017年2月現在のWatson、Google翻訳との違い
コグニティブサービスのAPIを用いて、「現在のコグニティブサービスでどのようなことができるのか」「どのようにして利用できるのか」「どの程度の精度なのか」を検証していく連載。今回は、Translator APIの概要と使い方を解説し、他のサービスとの違いを5パターンで検証する。 「統計的機械翻訳」の精度を超えた ニューラルネットワークによる高精度翻訳「Microsoft Translator」が日本語に対応
「統計的機械翻訳」の精度を超えた ニューラルネットワークによる高精度翻訳「Microsoft Translator」が日本語に対応
日本マイクロソフトは、近日中に音声翻訳向けのMicrosoft Translator Speech APIを日本語に対応させる。ニューラルネットワークを利用して、品質が高く、より自然な翻訳を可能にしたという。