Google‚ئIntel‚ھ‹¤“¯ٹJ”پAIntel GPU‚إJAXƒ‚ƒfƒ‹‚ًچ‚‘¬‰»‚·‚éPJRT API“oڈêپFAIƒtƒŒپ[ƒ€ƒڈپ[ƒN‚ض‚جƒnپ[ƒhƒEƒFƒAچإ“K‰»‚ھ—eˆص‚ة
Google‚حPJRT‚جڈ‰‚جƒvƒ‰ƒOƒCƒ“PJRT API‚ًIntel‚ئ‹¤“¯ٹJ”‚µ‚½‚±‚ئ‚ً”•\‚µ‚½پBPJRT API‚ًژہ‘•‚·‚邱‚ئ‚إIntel GPUڈم‚إ‚جJAXƒ‚ƒfƒ‹‚جژہچs‚âپAXLAƒAƒNƒZƒ‰ƒŒپ[ƒVƒ‡ƒ“‚ًژg—p‚µ‚½TensorFlow‚¨‚و‚رPyTorchƒ‚ƒfƒ‹‚جڈ‰ٹْIntel GPUƒTƒ|پ[ƒg‚à‰آ”\‚ة‚ب‚éپB
پ@Google‚ح2023”N6Œژ1“ْپi•ؤچ‘ژٹشپjپAIntel GPUڈم‚إJAXƒ‚ƒfƒ‹‚ًƒVپ[ƒ€ƒŒƒX‚ةژہچs‚·‚éپuIntel Extension for TensorFlowپv‚إپAڈ‰‚جPJRTپiPerformance JIT Runtimeپjƒvƒ‰ƒOƒCƒ“‚جژہ‘•‚ً”•\‚µ‚½پBPJRT API‚ح•ت“rٹJ”‚³‚ꂽIntel GPUƒvƒ‰ƒOƒCƒ“‚ئ‚ج“چ‡‚ًٹب‘f‰»‚µپAJAX‚ض‚جگv‘¬‚ب“چ‡‚ً‰آ”\‚ة‚·‚éپB‚ـ‚½پAPJRT‚جژہ‘•‚ة‚و‚èپAXLAƒAƒNƒZƒ‰ƒŒپ[ƒVƒ‡ƒ“‚ً”ُ‚¦‚½TensorFlow‚ئPyTorchƒ‚ƒfƒ‹‚جڈ‰ٹْIntel GPUƒTƒ|پ[ƒg‚à—LŒّ‚ة‚ب‚éپB

پ@Intel‚ئGoogle‚ح‹¤“¯‚إTensorFlow PluggableDeviceƒپƒJƒjƒYƒ€‚ًٹJ”‚µ‚½پB‚±‚جƒپƒJƒjƒYƒ€‚حTensorFlow‚ًگV‚µ‚¢ƒfƒoƒCƒX‚ةٹg’£‚·‚邽‚ك‚ةƒTƒ|پ[ƒg‚³‚ꂽژè–@‚إ‚ ‚èپAƒnپ[ƒhƒEƒFƒAƒxƒ“ƒ_پ[‚ح‚±‚ê‚ًژg—p‚µ‚ؤپA“ئژ©‚جƒvƒ‰ƒOƒCƒ“ƒoƒCƒiƒٹ‚جƒٹƒٹپ[ƒX‚ھ‰آ”\‚ة‚ب‚éپBIntel‚حپAXLAƒRƒ“ƒpƒCƒ‰—p‚جƒ‚ƒWƒ…ƒ‰پ[ƒCƒ“ƒ^ƒtƒFپ[ƒX‚جچ\’z‚âپAIntelGPUڈم‚إJAXƒڈپ[ƒNƒچپ[ƒh‚ًژہچs‚·‚邽‚ك‚جPJRTƒvƒ‰ƒOƒCƒ“‚جٹJ”‚إGoogle‚ئ‹¦—ح‚ً‘±‚¯‚ؤ‚¢‚éپB
JAX
پ@JAX‚حپAGPU‚âTPU‚ب‚ا‚جƒnƒCƒpƒtƒHپ[ƒ}ƒ“ƒXƒRƒ“ƒsƒ…پ[ƒeƒBƒ“ƒOƒfƒoƒCƒX‚إ‚ج•،ژG‚بگ”’lŒvژZ‚ج‚½‚ك‚ةگفŒv‚³‚ꂽƒIپ[ƒvƒ“ƒ\پ[ƒX‚جPythonƒ‰ƒCƒuƒ‰ƒٹ‚إ‚ ‚éپBNumPyٹضگ”‚ًƒTƒ|پ[ƒg‚µپAژ©“®”÷•ھ‚âپAƒjƒ…پ[ƒ‰ƒ‹ƒlƒbƒgƒڈپ[ƒN‚ًچ\’zپAŒP—û‚·‚邽‚ك‚جƒRƒ“ƒ|پ[ƒUƒuƒ‹ٹضگ”•دٹ·ƒVƒXƒeƒ€‚ً’ٌ‹ں‚·‚éپB
پ@JAX‚حپAƒRƒ“ƒpƒCƒ‹‚ئژہچs‚جƒoƒbƒNƒGƒ“ƒh‚ئ‚µ‚ؤXLA‚ًژg—p‚µپA“ء‚ةAIƒnپ[ƒhƒEƒFƒAƒAƒNƒZƒ‰ƒŒپ[ƒ^ڈم‚إ‚جŒvژZ‚ًچإ“K‰»‚µ•ہ—ٌ‰»‚·‚éپBJAXƒvƒچƒOƒ‰ƒ€‚ھژہچs‚³‚ê‚é‚ئپAPythonƒRپ[ƒh‚حOpenXLA‚جStableHLOƒIƒyƒŒپ[ƒVƒ‡ƒ“‚ة•دٹ·‚³‚êپAƒRƒ“ƒpƒCƒ‹‚ئژہچs‚ج‚½‚ك‚ةPJRT‚ة“n‚³‚ê‚éپB‚»‚ج‰؛‚إپAStableHLOƒIƒyƒŒپ[ƒVƒ‡ƒ“‚ھXLAƒRƒ“ƒpƒCƒ‰‚ة‚و‚ء‚ؤƒ}ƒVƒ“ƒRپ[ƒh‚ةƒRƒ“ƒpƒCƒ‹‚³‚êپAƒ^پ[ƒQƒbƒg‚جƒnپ[ƒhƒEƒFƒAƒAƒNƒZƒ‰ƒŒپ[ƒ^ڈم‚إژہچs‚·‚邱‚ئ‚ھ‚إ‚«‚éپB
PJRT
پ@PJRTپiOpenXLA‚جStableHLO‚ئ‘g‚فچ‡‚ي‚¹‚ؤژg—pپj‚حپAƒRƒ“ƒpƒCƒ‰‚ئƒ‰ƒ“ƒ^ƒCƒ€Œü‚¯‚جƒnپ[ƒhƒEƒFƒA‚¨‚و‚رƒtƒŒپ[ƒ€ƒڈپ[ƒN‚ةˆث‘¶‚µ‚ب‚¢ƒCƒ“ƒ^ƒtƒFپ[ƒX‚ً’ٌ‹ں‚·‚éپBPJRTƒCƒ“ƒ^ƒtƒFپ[ƒX‚حپAگV‚µ‚¢ƒfƒoƒCƒXƒoƒbƒNƒGƒ“ƒh‚©‚ç‚جƒvƒ‰ƒOƒCƒ“‚ًƒTƒ|پ[ƒg‚µ‚ؤ‚¢‚éپB‚±‚جƒCƒ“ƒ^ƒtƒFپ[ƒX‚حپAJAX‚ًIntel‚جƒVƒXƒeƒ€‚ضƒXƒgƒŒپ[ƒg‚ة“چ‡‚·‚邽‚ك‚جژè’i‚ً’ٌ‹ں‚µپAIntel GPUڈم‚إ‚جJAX‚جƒڈپ[ƒNƒچپ[ƒh‚ً‰آ”\‚ة‚·‚éپB‚³‚ـ‚´‚ـ‚بAIƒtƒŒپ[ƒ€ƒڈپ[ƒN‚ئPJRT‚ئ‚ج“چ‡‚ة‚و‚èپAIntel‚جGPUƒvƒ‰ƒOƒCƒ“‚حIntel GPU‚ًژg—p‚·‚é•چL‚¢ٹJ”ژز‚ةƒnپ[ƒhƒEƒFƒAƒAƒNƒZƒ‰ƒŒپ[ƒVƒ‡ƒ“‚ئoneAPI‚جچإ“K‰»‚ً’ٌ‹ں‚إ‚«‚éپB
پ@PJRT API‚حپAڈمˆت‚جAIƒtƒŒپ[ƒ€ƒڈپ[ƒN‚ھStableHLO‚إ•\Œ»‚³‚ꂽگ”’lŒvژZ‚ًAIƒnپ[ƒhƒEƒFƒAپ^ƒAƒNƒZƒ‰ƒŒپ[ƒ^ڈم‚إƒRƒ“ƒpƒCƒ‹پAژہچs‚·‚邽‚ك‚جƒtƒŒپ[ƒ€ƒڈپ[ƒN”ٌˆث‘¶Œ^API‚¾پB‚±‚جAPI‚حپAJAXپATensorFlowپiTF-XLAŒo—RپjپAPyTorchپiPyTorch-XLAŒo—Rپj‚ب‚ا‚جˆê”ت“I‚بAIƒtƒŒپ[ƒ€ƒڈپ[ƒN‚ئ“چ‡‚³‚ê‚ؤ‚¨‚èپAƒnپ[ƒhƒEƒFƒAƒxƒ“ƒ_پ[‚حگV‚µ‚¢AIƒnپ[ƒhƒEƒFƒA‚جƒvƒ‰ƒOƒCƒ“‚ً’ٌ‹ں‚·‚邾‚¯‚إپA‚±‚ê‚ç‘S‚ؤ‚جˆê”ت“IAIƒtƒŒپ[ƒ€ƒڈپ[ƒN‚ًƒTƒ|پ[ƒg‚إ‚«‚é‚و‚¤‚ة‚ب‚éپB‚ـ‚½پAƒ[ƒچƒRƒsپ[ƒoƒbƒtƒ@پ[‚ج’ٌ‹ںپAˆث‘¶ٹضŒWٹا—‚ھŒy—ت‚إŒّ—¦“I‚ب‚±‚ئ‚ب‚اپAڈمˆت‚جAIƒtƒŒپ[ƒ€ƒڈپ[ƒN‚ئ‚جŒّ—¦“I‚ب‚â‚è‚ئ‚è‚ً‰آ”\‚ة‚·‚é’لƒŒƒxƒ‹ƒvƒٹƒ~ƒeƒBƒu‚ً’ٌ‹ں‚µپAAIƒtƒŒپ[ƒ€ƒڈپ[ƒN‚ھƒnپ[ƒhƒEƒFƒAƒٹƒ\پ[ƒX‚ًچإ‘هŒہ‚ةٹˆ—p‚µپAچ‚گ«”\‚بژہچs‚ًژہŒ»‚إ‚«‚é‚و‚¤‚ة‚µ‚½پB

Intel GPU—pPJRTƒvƒ‰ƒOƒCƒ“
پ@Intel GPUƒvƒ‰ƒOƒCƒ“‚حپAStableHLO‚ًƒRƒ“ƒpƒCƒ‹‚µپAژہچsƒtƒ@ƒCƒ‹‚ًIntel GPU‚ةƒfƒBƒXƒpƒbƒ`‚·‚邱‚ئ‚إپAPJRT API‚ًژہ‘•‚·‚éپBƒRƒ“ƒpƒCƒ‹‚حXLAژہ‘•‚ًƒxپ[ƒX‚ةپAIntel GPU—p‚جƒ^پ[ƒQƒbƒgŒإ—L‚جƒpƒX‚ً’ا‰ء‚µپAoneAPIƒpƒtƒHپ[ƒ}ƒ“ƒXƒ‰ƒCƒuƒ‰ƒٹ‚ًٹˆ—p‚µ‚ؤƒAƒNƒZƒ‰ƒŒپ[ƒVƒ‡ƒ“‚ًژہŒ»‚µ‚ؤ‚¢‚éپBƒfƒoƒCƒX‚جژہچs‚حپASYCLƒ‰ƒ“ƒ^ƒCƒ€‚ًژg—p‚µ‚ؤƒTƒ|پ[ƒg‚³‚ê‚ؤ‚¢‚éپB‚ـ‚½پAIntel GPUƒvƒ‰ƒOƒCƒ“‚ة‚حƒfƒoƒCƒX‚ج“oک^پA—ٌ‹“پASPMDپiSingle Program, Multiple Dataپjژہچsƒ‚پ[ƒh‚àژہ‘•‚³‚ê‚ؤ‚¢‚éپB
پ@PJRT‚جچ‚ƒŒƒxƒ‹‚جƒ‰ƒ“ƒ^ƒCƒ€’ٹڈغ‰»‚ة‚و‚èپAƒvƒ‰ƒOƒCƒ“‚ح“ئژ©‚ج’لƒŒƒxƒ‹‚جƒfƒoƒCƒXٹا—ƒ‚ƒWƒ…پ[ƒ‹‚ًٹJ”‚µپAگV‚µ‚¢ƒfƒoƒCƒX‚ھ’ٌ‹ں‚·‚éچ‚“x‚بƒ‰ƒ“ƒ^ƒCƒ€‹@”\‚ًژg—p‚·‚邱‚ئ‚ھ‰آ”\‚¾پB
پ@Flax‚âT5X‚ج‚و‚¤‚بJAXƒxپ[ƒX‚جƒtƒŒپ[ƒ€ƒڈپ[ƒN‚ًٹـ‚قJAXƒvƒچƒOƒ‰ƒ€‚ًژہچs‚·‚邽‚ك‚ةپAIntel GPUƒvƒ‰ƒOƒCƒ“‚حٹب’P‚ةژg‚¢ژn‚ك‚邱‚ئ‚ھ‚إ‚«‚éپBƒhƒLƒ…ƒپƒ“ƒg‚إ‚ ‚ê‚خپAƒvƒ‰ƒOƒCƒ“‚ًƒrƒ‹ƒh‚µپAٹآ‹«•دگ”‚ئˆث‘¶ƒ‰ƒCƒuƒ‰ƒٹ‚جƒpƒX‚ًگف’è‚·‚邾‚¯‚إ‚ ‚éپBJAX‚حژ©“®“I‚ةƒvƒ‰ƒOƒCƒ“ƒ‰ƒCƒuƒ‰ƒٹ‚ً’T‚µپAŒ»چف‚جƒvƒچƒZƒX‚ةƒچپ[ƒh‚·‚éپB
پ@ˆب‰؛‚حپAIntel GPUڈم‚إJAX‚ًژہچs‚·‚éƒRپ[ƒhƒXƒjƒyƒbƒg—ل‚إ‚ ‚éپB
$ export PJRT_NAMES_AND_LIBRARY_PATHS='xpu:Your_itex_library/libitex_xla_extension.so' $ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:Your_Python_site-packages/jaxlib $ python >>> import numpy as np >>> import jax >>> jax.local_devices() # PJRT Intel GPU plugin loaded [IntelXpuDevice(id=0, process_index=0), IntelXpuDevice(id=1, process_index=0)] >>> x = np.random.rand(2,2).astype(np.float32) >>> y = np.random.rand(2,2).astype(np.float32) >>> z = jax.numpy.add(x, y) # Runs on Intel XPU
چ،Œم‚جژو‚è‘g‚ف
پ@Intel GPU—p‚جPJRTƒvƒ‰ƒOƒCƒ“‚حپAIntel‚جGPU‚إ“®چى‚·‚é‚و‚¤‚ةTensorFlow‚ة‚à“چ‡‚³‚ê‚ؤ‚¢‚éپB‚±‚ê‚ة‚و‚èپATensorFlowƒ‚ƒfƒ‹“à‚جXLAƒTƒ|پ[ƒg‚³‚ꂽ‘€چى‚ًژہچs‚·‚邱‚ئ‚ھ‚إ‚«‚éپB‚µ‚©‚µپAXLA‚جƒIƒyƒŒپ[ƒVƒ‡ƒ“ƒZƒbƒg‚حTensorFlow‚و‚è‚àڈ‚ب‚¢‚½‚كپAXLA‚ھTensorFlow‚إ’ٌ‹ں‚³‚ê‚ؤ‚¢‚é‘S‚ؤ‚جƒIƒyƒŒپ[ƒVƒ‡ƒ“‚ًƒTƒ|پ[ƒg‚µ‚ؤ‚¢‚ب‚¢پB‚»‚±‚إTensorFlowƒ‚ƒfƒ‹‚إ‚حپAƒ‚ƒfƒ‹ƒOƒ‰ƒt‚ج•”•ھ‚حPJRT‚إژہچs‚µپA‘¼‚ج•”•ھ‚حTensorFlow OpKernel‚ًژg—p‚µ‚ؤڈ‰ٹْTensorFlowƒ‰ƒ“ƒ^ƒCƒ€‚إژہچs‚µ‚ؤ‚¢‚éپB
پ@ژں‚جƒXƒeƒbƒv‚ئ‚µ‚ؤپAGoogle‚ئIntel‚ح‘S‚ؤ‚جTensorFlowƒ‚ƒfƒ‹‚ًƒTƒ|پ[ƒg‚·‚éIntel GPU‚إ”ٌXLAOps‚ًژہ‘•‚·‚邽‚ك‚ةپANextPluggableDevice API‚ًچج—p‚µ‹¦—ح‚ً‘±‚¯‚ؤ‚¢‚—\’肾‚ئ‚¢‚¤پB
Copyright © ITmedia, Inc. All Rights Reserved.
ٹضکA‹Lژ–
 Google CloudپAƒNƒ‰ƒEƒhٹJ”ٹآ‹«پuCloud Workstationsپvگ³ژ®ƒٹƒٹپ[ƒXپ@OSS”إVS Code‚à—ک—p‰آ”\
Google CloudپAƒNƒ‰ƒEƒhٹJ”ٹآ‹«پuCloud Workstationsپvگ³ژ®ƒٹƒٹپ[ƒXپ@OSS”إVS Code‚à—ک—p‰آ”\
Google Cloud‚حپAƒNƒ‰ƒEƒhڈم‚إٹ®‘S‚ةٹا—‚³‚ꂽˆہ‘S‚بٹJ”ٹآ‹«‚ً’ٌ‹ں‚·‚éپuCloud Workstationsپv‚جˆê”ت’ٌ‹ں‚ًٹJژn‚µ‚½پB Meta‚ھژںگ¢‘مAIƒCƒ“ƒtƒ‰چ\’zŒv‰و‚جگi’»ڈَ‹µ‚ً”•\پ@ƒJƒXƒ^ƒ€AIƒAƒNƒZƒ‰ƒŒپ[ƒ^ƒ`ƒbƒvپAژںگ¢‘مDC‚ب‚ا
Meta‚ھژںگ¢‘مAIƒCƒ“ƒtƒ‰چ\’zŒv‰و‚جگi’»ڈَ‹µ‚ً”•\پ@ƒJƒXƒ^ƒ€AIƒAƒNƒZƒ‰ƒŒپ[ƒ^ƒ`ƒbƒvپAژںگ¢‘مDC‚ب‚ا
Meta‚حپAژںگ¢‘مAIƒCƒ“ƒtƒ‰‚ًچ\’z‚·‚éŒv‰و‚جچإ‹ك‚جگi’»ڈَ‹µ‚ً”•\‚µ‚½پB”•\‚ج–ع‹ت‚حپAAIƒ‚ƒfƒ‹‚ًژہچs‚·‚邽‚ك‚ج“¯ژذڈ‰‚جƒJƒXƒ^ƒ€ƒVƒٹƒRƒ“ƒ`ƒbƒvپAAI‚ةچإ“K‰»‚³‚ꂽگV‚µ‚¢ƒfپ[ƒ^ƒZƒ“ƒ^پ[گفŒvپA1–œ6000Œآ‚جGPU‚ً“‹چع‚·‚éAIŒ¤‹†—pƒXپ[ƒpپ[ƒRƒ“ƒsƒ…پ[ƒ^‚ج‘و2ƒtƒFپ[ƒY‚¾پB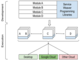 GoogleپA•ھژUƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“‚ًچ\’zپEƒfƒvƒچƒC‚·‚éOSSƒtƒŒپ[ƒ€ƒڈپ[ƒNپuService Weaverپv”•\
GoogleپA•ھژUƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“‚ًچ\’zپEƒfƒvƒچƒC‚·‚éOSSƒtƒŒپ[ƒ€ƒڈپ[ƒNپuService Weaverپv”•\
Google‚حپA•ھژUƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“‚ًچ\’zپAƒfƒvƒچƒCپi“WٹJپj‚·‚邽‚ك‚جƒIپ[ƒvƒ“ƒ\پ[ƒXƒtƒŒپ[ƒ€ƒڈپ[ƒNپuService Weaverپv‚ً”•\‚µ‚½پB