【Excelで学ぶデータ分析】待ち時間の長いラーメン店ほど評価が高いのか?(順位相関の検定):やさしい推測統計(仮説検定編)
初歩から応用までステップアップしながら学んでいく『やさしいデータ分析』シリーズ(仮説検定編)の第13回。前回、前々回と、ノンパラメトリック検定に取り組んでいますが、今回は、順位を基にした相関係数の検定方法について解説します。
連載:
この連載は、データをさまざまな角度から分析し、その背後にある有益な情報を取り出す方法を学ぶ『社会人1年生から学ぶ、やさしいデータ分析』シリーズの「記述統計と回帰分析編」「確率分布編」「推測統計(区間推定編)」に続く「推測統計(仮説検定編)」です。
この連載では、観測されたデータを基に、平均に差があるかどうか、分散に差があるかどうかなどを吟味するために、仮説検定を行う方法や適用時の留意点などを説明します。身近に使える表計算ソフトウェア(Microsoft ExcelやGoogleスプレッドシート)を使いながら具体的に事例を見ていきます。
必要に応じて、Pythonのプログラムなどでの作成例にも触れることにしますが、数学などの前提知識は特に問いません。肩の力を抜いてぜひとも気楽に読み進めてください。
筆者紹介: IT系ライターの傍ら、これまで非常勤講師として東大で情報・プログラミング関連の授業を、一橋大でAI関連の授業を担当。かなり前から髪をブリーチしていて金髪先生を自称していたのだけれど、放置しているといい感じのグレーヘアーになってきたので、もはや寄る年波かと思う昨今。最近、成長したなと感じていることは、生まれてこの方どうしても食べられなかった納豆が食べられるようになったこと。唐揚げにはレモンをかけない派。
データ分析の初歩から応用まで少しずつステップアップしながら学んでいく連載の推測統計(仮説検定編)、第13回です。前回は母集団に特定の母数を仮定しない(できない)場合のノンパラメトリック検定の例として、分布のばらつきが異なるかどうかを調べるためにアンサリ・ブラッドレイ(Ansari-Bradley)検定などを取り上げました。今回は、順位相関の検定について解説します。順位相関と呼ばれるものには、スピアマン(spearman)の順位相関とケンドール(kendall)の順位相関がありますが、それらの使い分けについても見ていきます。
順位相関とは? どうやって検定するの?
順位相関については、『やさしいデータ分析』の第13回で、スピアマンの順位相関を例に、その考え方や求め方を紹介しました。といっても、ずいぶん前の記事なので、簡単におさらいをしておきたいと思います。まずは、事例を見てみましょう。図1に示したのは架空の例です。

図1 待ち時間の長いラーメン店ほど評価が高いのか?
待ち時間が長いと、人間の心理として高い評価を与えたくなるのか、そもそも評価の高いお店だから、人が集まって待ち時間が長くなるのか、因果関係は分からないが、相関はあるのではないかと思われる。ただ、評価の平均は間隔尺度ではないかもしれないので、順位相関を求めて検定を行うことにする。
「相関係数」と言うと、ExcelのCORREL関数で求められるピアソンの相関係数がまず思い浮かべられます。ピアソンの相関係数は、間隔尺度のデータについて、直線的な関係があるかどうかを表す指標として使われます。間隔尺度とは、値が一定の間隔で並んでいると考えられる尺度でした。分かりやすく言うと、一定の間隔で目盛りを振ることができるような値です。
上の例では、待ち時間は間隔尺度として問題がなさそうですが、ラーメン店の評価については、間隔尺度とするのは厳密ではありません。というのも、5段階評価を行うような場合、1(きわめて不満)と2(やや不満)の間隔と、2(やや不満)と3(普通)の間隔は異なるかもしれないからです。常識的に考えて、1を付けるのは相当ひどい場合なので、1と2の間隔はかなり広いのではないかと思われます。
何人かの評価を平均すると、3.4とか1.8といった、いかにも間隔尺度のような値になりますが、それでも、「目盛り」の間隔が等しくなるわけではありません。とはいえ、便宜的に間隔尺度と見なして計算することもよくあります(厳密さを重視するのであれば、順序尺度として扱った方がいいでしょう)。
そこで、順位相関を使うべき場面を列挙してみます。
- 間隔尺度だが、分布に偏りがあったり外れ値があったりする場合
- 順序尺度の場合(値に大小はあるが、間隔は一定ではないと考えられる場合)
- そもそもデータが順位で表されている場合
です。図1の例は、一方の変数(待ち時間)は間隔尺度ですが、もう一方の変数(評価の平均)は順序尺度です。そのような場合にも、厳密には順位相関を使います。
スピアマンの順位相関を求める
順位相関には、スピアマンの順位相関とケンドールの順位相関がありますが、まずはスピアマンの順位相関について、次にケンドールの順位相関について見ていきます。それらの違いや使い分けについては後述します。スピアマンの順位相関を求めるための手順は以下の通りです。
- 値を基に順位を付ける(RANK.AVG関数を使うとよい)
- 順位を基に、ピアソンの相関係数を求める(CORREL関数を使うとよい)
元の値は間隔が一定ではありませんが、順位は間隔が一定です。というわけで、順位に対してCORREL関数を適用するだけでいい、ということですね。であれば、これまでの知識だけでできます。おさらいがてらやってみましょう(図2)。
Excelの場合はこちらからダウンロードしたサンプルを開き、[スピアマンの順位相関検定]ワークシートを開いて試してみてください。Googleスプレッドシートのサンプルはこちらから開くことができます。メニューから[ファイル]−[コピーを作成]を選択し、Googleドライブにコピーしてお使いください。

図2 スピアマンの順位相関を求める
サンプルデータは架空のもので、データは33行目まで入力されている。RANK.AVG関数を使って、B列の値の順位をD列に求め、C列の値の順位をE列に求める。後は、CORREL関数にそれらの順位を指定するだけ。
RANK.AVG関数ではスピル機能を使っていることに注意してください。RANK.AVG関数の引数には「順位を求めたい値」、「範囲」、「順序」を指定します。セルD4に入力した「=RANK.AVG(B4:B33, B4:B33, 1)」であれば、「セルB4〜B33のそれぞれの値の順位を」、「セルB4〜B33の範囲」で「昇順で」求める、ということになります。「順序」の指定は、1が昇順、0が降順となります。セルE4には図のように入力してもいいですが、セルD4をセルE4にコピーしても構いません(その方が簡単ですね)。
Googleスプレッドシートでは、配列数式を入力するためにARRAYFORMULA関数を使って、セルD4に「=ARRAYFORMULA(RANK.AVG(B4:B33, B4:B33, 1))」と入力します。セルE4についても、同様に「=ARRAYFORMULA(RANK.AVG(C4:C33, C4:C33, 1))」となります。
CORREL関数は簡単ですね。セルD4以降で求められた待ち時間の順位とセルE4以降で求められた評価の順位を指定するだけです。つまり、D4#とE4#を指定すればいいということです。Googleスプレッドシートをお使いの方はD4#の代わりにD4:D33を、E4#の代わりにE4:E33を指定してください。
スピアマンの順位相関を検定する
続いて、スピアマンの順位相関の検定に取り組みましょう。結局のところ、順位の値に対してピアソンの相関係数を求めているだけなので、検定方法も第8回で見た相関係数の検定方法と同じです。上で求めた相関係数をrsとするなら、検定統計量Tは、
で求められます。帰無仮説と対立仮説を確認してから、やってみましょう。
- 帰無仮説(H0): ρs=0
- 対立仮説(H1): ρs ≠ 0
ρsは母集団の順位相関を表します(rsはサンプルの順位相関です)。この例では、対立仮説がρs ≠ 0なので、両側検定を行うことになります。検定統計量Tは、自由度n−2のt分布に従うので、その両側確率を求めます。同じワークシートで続けてやってみましょう(図3)。

図3 スピアマンの順位相関を検定する
(1)式に従って検定統計量Tを求め、T.DIST.2T関数を使って両側確率を求める。なお、Tの値は負になることもあるので、T.DIST.2T関数には絶対値を指定する。Googleスプレッドシートの場合は、セルH5の式を「=COUNT(D4:D33)」とする。
結果は0.056となり、有意傾向はあるものの、帰無仮説は棄却できませんでした。rs = 0.352という値からは弱い相関があるように思われますが、これだけでは、ラーメン店の待ち時間と評価に関係があるとはいえない、ということになります。
言い換えると、順位相関の検定は「順位は独立か」つまり、2群の順位には関係がないかという検定になります。元の値にさかのぼって考えると、2群の関係は(間隔が異なるので)必ずしも直線的ではないかもしれないが、一方が増えれば他方も増える、あるいは減る、といった関係かどうかということになります。
スピアマンの順位相関の検定に必要なサンプルサイズ
ここまで、スピアマンの順位相関の求め方と検定の方法について見てきましたが、そもそも、データを収集する前にサンプルサイズを決めておく必要がありましたね。順序は逆になりましたが、サンプルサイズの求め方を見ておきましょう……と、いっても、順位に対してピアソンの相関係数を求めているだけなので、サンプルサイズの求め方もピアソンの相関係数の場合と同じです。これについても、既にこちらで解説しました。近似計算を使う場合、以下の式で求められます。
分母のzは、母集団の順位相関係数として見積もった値をρsを以下の式でフィッシャー変換したものです(ExcelならFISHER関数にρsの値を指定するだけで求められます)。
分子のz1−α/2は標準正規分布の1−α/2点の値、z1−βは標準正規分布の1−β点の値です。同じzという文字を使っているのでややこしいですが、分母と分子のzは異なるものです。例えば、有意水準をα=0.05、検出力を1−β=0.8とし、ρs=0.4と見積もられるのであれば、
なので、
です。値を切り上げればn=47となります。少し余裕を見て、n=50にするといいでしょう。ちなみに、G*Powerで(非心t分布を使ってより正確に)見積もると、n=44となります。設定は以下の通りです。
- Test family: t tests
- Statistical test: Correlation: Point biserial model
- Type of power analysis: Compute required sample size - given α, power, and effect size
- Tail(s): Two
- Effect size |ρ|: 0.4
- α err prob: 0.05
- Power(1-β err prob): 0.8
今回の事例は、そもそもサンプルサイズが小さ過ぎたようです。しかし、既に何度も触れているように、後からデータを追加して検定を行うのは邪道です。この段階までで得られた知見を基に、新たな仮説を立て、調査・実験をデザインして、サンプルを収集し直すのがスジです。
ケンドールの順位相関を求めて、検定を行ってみよう
では、次にケンドールの順位相関です。が、計算の方法を解説する前に、スピアマンの順位相関との使い分けを見ておきましょう。ケンドールの順位相関の方が信頼性が高い場合を箇条書きでまとめておきます。
- サンプルサイズが小さい(一般にn<20)場合
- 外れ値が含まれている場合
- 同じ順位が多く含まれている場合
スピアマンの順位相関も外れ値にはある程度頑健ですが、順位の差を2乗しているので、外れ値や、わずかな値(順位)の変化で結果が大きく変わることがあります。例えば、サンプルファイルのセルC20の2.2という評価が2.5だったとすると、P値が0.047となり、帰無仮説が棄却されます(実際に値を変えて試してみるといいでしょう)。
今回の事例ではサンプルサイズはn=30なので、上の目安には当てはまりませんが、同順位がやや多いので、スピアマンの順位相関よりもケンドールの順位相関の方が適していたともいえます(後でケンドールの順位相関を求めた例も紹介します)。
ただし、ここは要注意なのですが、サンプルサイズが小さい場合、順位相関の値としてはケンドールの順位相関の方が信頼性が高いのですが、検定に関しての信頼性が高いというわけではありません。そのことについては、後で見ることにして、取りあえず、ケンドールの順位相関を求めてみましょう。
ケンドールの順位相関の考え方
ケンドールの順位相関では、順序が一致しているか、逆転しているかに注目します。データの全ての組み合わせについて、順序が一致していれば+1、順序が逆転していれば−1という得点を与えます。簡単な例で見てみましょう。
例えば、2025年のプロ野球セ・リーグの順位は、1位:阪神、2位:DeNA、3位:巨人、4位:広島、5位:中日、6位:ヤクルトでした。が、野球解説者T氏が開幕前に予想した順位は、1位:巨人、2位:広島、3位:阪神、4位:DeNA、5位:ヤクルト、6位:中日でした。これらを、実際の順序に沿って並べてみると以下のようになります。
| 球団 | 阪神 | DeNA | 巨人 | 広島 | 中日 | ヤクルト |
|---|---|---|---|---|---|---|
| 実際 | 1 | 2 | 3 | 4 | 5 | 6 |
| T氏の予想 | 3 | 4 | 1 | 2 | 6 | 5 |
| 表1 2025年のプロ野球セ・リーグの順位 | ||||||
予想は全部外れていました(と、T氏自身のYouTubeチャンネルでアシスタントのMさんにからかわれていました)が、ケンドールの順位相関を求めてみると、どうなるでしょうか。ケンドールの順位相関τ(「タウ」と読みます)を求める手順は以下の通りです。
- 順位の全ての組み合わせを列挙し、順序が一致していれば+1点、順序が逆転していれば−1点を与える
- 例えば、阪神-DeNAは、実際には1<2で、T氏の予想も3<4のように同じ順序なので、+1点とする
- 次の、阪神-巨人は、実際には1<3だが、T氏の予想は3>1のように順序が逆転しているので、−1点とする……といった具合に全ての組み合わせについて点数を付ける
- 上記の値を合計する(合計をSとする)
- τを以下の式で求める
サンプルサイズがnであれば、全ての組み合わせは、n(n−1)/2組なので、上の式は、
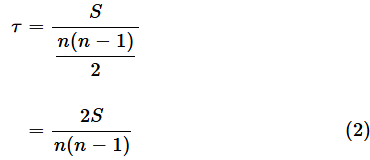
と表すことができます。というわけで、この(2)式を使えばいいのですが、全ての組み合わせを調べてSを求めるのはとても面倒です。Excelでは最もやりたくない計算ですね。そこで、Pythonの力を借りましょう。
Pythonを使ってケンドールの順位相関を求め、検定を行う
Pythonを使うなら、scipy.statsモジュールのkendalltau関数を呼び出すだけです。この関数は順位相関だけでなく、なんと、P値も自動的に計算してくれます(P値を求めるための式は後述します)。サンプルプログラムはこちらにあります。リンクを開くとPythonのプログラムが表示されるので、最初のコードセルをクリックし、[Shift]+[Enter]キーを押してプログラムを実行すると、結果が表示されます。
# プロ野球セ・リーグ2025年順位予想と実際の順位について、ケンドールの順位相関を求める
from scipy.stats import kendalltau
a = [1, 2, 3, 4, 5, 6] # 実際の順位
b = [3, 4, 1, 2, 6, 5] # T氏の予想
tau, p = kendalltau(a, b)
print(f"tau={tau:.3f}, p={p:.3f}") # tau=0.333, p=0.469と出力される
scipy.statsモジュールのkendalltau関数に2群の値を指定するだけでよい。ケンドールの順位相関とP値が同時に返される。
結果は、τ=0.333, p=0.469となり、有意水準を5%(α=0.05)とすると、p=0.469はこれを上回るため、帰無仮説は棄却できません。順位相関は0.333なので、ある程度の相関が見られる印象はありますが、統計的には予想と実際の順位に関係があるとはいえない(予想が当たったとはいえない)ということですね。
もちろん、帰無仮説が棄却できないからといって、帰無仮説が支持されるわけではないので、T氏の予想が「外れた」と言うことはできません。ただ、当たったとはいえないだけです。また、あまりにもサンプルサイズが小さいので、結果はあまり信頼できません(あくまで、計算方法の説明のための例だということです)。
上の例では、観測されたデータがたまたま順位の形で表されていたので、kendalltau関数の引数に順位を指定していますが、いちいち順位に変換しなくても、変数の値そのものが指定できます。
なお、kendalltauをspearmanrに変えると、スピアマンの順位相関とP値を求めることができます。サンプルプログラムの2番目のコードセルには、図1の例で、spearmanrとkendalltauの両方を使ったプログラムを含めてあります。
スピアマンの順位相関ではrs=0.352, p=0.056となり、ケンドールの順位相関ではtau=0.242, p=0.065となります(いずれも、帰無仮説は棄却できません)。コードを実行して、結果を確認してみてください。ただし、何度も言うように、結果を見てから分析方法を変えるのは御法度です。あらかじめ(恣意《しい》的にではなく、合理的に)決めておくべきです。
このように、kendalltau関数を使えばP値も求められますが、一応、どのような方法で求めているかを記しておきましょう。ケンドールの順位相関では、検定統計量zを以下の式で求めます。
zは標準正規分布に従うので、その両側確率がP値となります。
ケンドールの順位相関の検定に必要なサンプルサイズ
単刀直入に近似式を掲載します。ケンドールのτは、以下のような式で、ピアソンの相関係数r(スピアマンではなく、ピアソンです)に近似的に変換できます。文字の形が似ているので、ちょっと見づらいですが、左辺がピアソンの相関係数rで、右辺の最後の文字がケンドールのτです。
見積もったτの値を基にrを求め、それを母相関係数の推定値ρとして、サンプルサイズを計算します。計算の方法はピアソンの相関係数の場合と同じです。例えば、τ=0.4とすると、r=0.588となるので(途中の計算は省略して結果だけ書きます)、
となり、α=0.05, 1−β=0.8とすると、
なので、
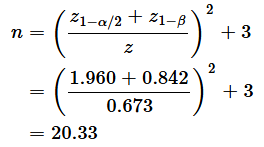
となります。値を切り上げてn = 21、あるいは、少し余裕を見て、n=25とすればいいでしょう。
小サンプルの場合の対処法 〜 パーミュテーション検定
見積もったサンプルサイズがどうしても確保できない場合には、パーミュテーション検定(置換検定)と呼ばれる方法を使うことにより、ある程度、信頼性のある検定ができるようになります。手順は以下の通りです。
- サンプルの順位相関を求めておく(観測された相関係数)
- 以下を繰り返す
- 一方の群の値をランダムに並べ替える
- 順位相関を求める(ランダムな相関係数)
- ランダムな順位相関の絶対値>=観測された順位相関の絶対値であれば、カウント数を増やす
- カウント数/全体の繰り返し数を返す
要するに、観測された順位相関よりも極端な値が求められる割合をp値とする、ということです。これについてもPythonを使った方が簡単ですね。そこで、サンプルプログラムには、スピアマンの順位相関を使ったパーミュテーション検定の例も含めておきました。
3つ目のコードセルに入力されたコードを見ると、サンプルサイズの小さい例となっていることが分かります(n=20)。プログラムの内容について、ここでは細かく解説しませんが、コード内のコメントを見れば、だいたい意味が分かると思います。コードを実行すると、r=0.408, p=0.074, p_perm=0.076という結果が表示されます。p_permの値がパーミュテーション検定の結果です。
ただし、極端な外れ値がある場合、順位が大きく変わることがあるので(そして、その差を2乗するので)、パーミュテーション検定でも、スピアマンの順位相関はその影響を受けやすくなります。平たく言えば、有意になりにくい、ということです。
一方、ケンドールの順位相関では、順位が1つ大きく変わっても、順序が逆転したのはあくまで1件だけなので、全体として単調増加(あるいは単調減少)である、ということを安定して検出できます。こちらも、平たく言えば、有意になりやすい、ということです。
ちなみに、4つ目のコードセルには、ケンドールの順位相関を使ったパーミュテーション検定の例を掲載してあります。コードを実行すると、なんと、tau=0.347, p=0.034, p_perm=0.038となり、5%有意で帰無仮説が棄却されてしまいます。これは、待ち時間2分で、評価4.4といった外れ値が、スピアマンの順位相関の検定で大きく影響したためと考えられます。ケンドールの順位相関の検定では、順序が1つ逆転しても、それほど全体には影響しないというわけです。
では、どちらを選べばいいのか、ということですが、やはり結果を見てから判断するのは「後出しじゃんけん」なので、避けるべきです。調査や研究の関心として、順位が直線的な関係であるかどうかに重点を置くなら、スピアマンの順位相関を選び、全体としての傾向を知りたいということであれば、ケンドールの順位相関を選ぶ、ということになります。
今回は、2つの変数の関係をノンパラメトリック検定によって知る方法として、スピアマンの順位相関とケンドールの順位相関を紹介しました。内容としては、それらの考え方や計算の方法、検定の方法、使い分けなどについて順に見ました。また、サンプルサイズの求め方や小サンプルの場合の対処法についても見てきましたね。
さて、この連載もいよいよ次が最終回です。これまでの検定では、主に2群の差について検定する方法を見ていきましたが、次回は、3群以上について平均値の差の検定などを行うための分散分析について、初歩の初歩から解説します。次回もお楽しみに!
Copyright© Digital Advantage Corp. All Rights Reserved.