【Excelで学ぶデータ分析】生成AIによって応答時間に差はあるか?[架空事例](分散分析超入門):やさしい推測統計(仮説検定編)
初歩から応用までステップアップしながら学んでいく『やさしいデータ分析』シリーズ(仮説検定編)の第14回。これまで、13回にわたって、主に2群の差や分散などについて検定の考え方やその手順を見てきました。今回は、3群以上の場合にも対応するために、分散分析の考え方や手順を解説します。
連載:
この連載は、データをさまざまな角度から分析し、その背後にある有益な情報を取り出す方法を学ぶ『社会人1年生から学ぶ、やさしいデータ分析』シリーズの「記述統計と回帰分析編」「確率分布編」「推測統計(区間推定編)」に続く「推測統計(仮説検定編)」です。
この連載では、観測されたデータを基に、平均に差があるかどうか、分散に差があるかどうかなどを吟味するために、仮説検定を行う方法や適用時の留意点などを説明します。身近に使える表計算ソフトウェア(Microsoft ExcelやGoogleスプレッドシート)を使いながら具体的に事例を見ていきます。
必要に応じて、Pythonのプログラムなどでの作成例にも触れることにしますが、数学などの前提知識は特に問いません。肩の力を抜いてぜひとも気楽に読み進めてください。
筆者紹介: IT系ライターの傍ら、これまで非常勤講師として東大で情報・プログラミング関連の授業を、一橋大でAI関連の授業を担当。かなり前から髪をブリーチしていて金髪先生を自称していたのだけれど、放置しているといい感じのグレーヘアーになってきたので、もはや寄る年波かと思う昨今。最近、成長したなと感じていることは、生まれてこの方どうしても食べられなかった納豆が食べられるようになったこと。唐揚げにはレモンをかけない派。
データ分析の初歩から応用まで少しずつステップアップしながら学んでいく連載の推測統計(仮説検定編)、第14回(最終回)です。検定の基本的な考え方から出発し、これまで、平均や分散、相関係数の検定などのパラメトリック検定を学び、さらには、中央値や分布の広がりの検定、前回見た順位相関の検定といったノンパラメトリック検定についても見てきました。
いずれも、比較の対象となっていたのは2つの群でしたが、実際の場面では3群以上の比較が必要になる場合もよくあります。例えば、ダイエットの効果を比較するために、サプリメントの分量を「なし」「サプリA」「サプリB」の3つの群(グループ)に分けるといった場合がそれに当たります。
また、詳細については後述しますが、要因が2つ以上になる場合もあります。例えば、さらに「男性」「女性」といった2つの群に分けて効果を見る、といった場合です(1つ目の要因がサプリの種類、2つ目の要因が性別です)。
まず、要因が1つの例(一元配置分散分析と呼ばれます)について、事例を見ていきましょう。
事例を基に分散分析の考え方を理解しよう
図1に示したのは架空の事例ですが、生成AIの3つのモデル(軽量モデル、標準モデル、重量モデル)に幾つかの質問を与え、回答が返されるまでの時間を測定したものです。要因は1つ(モデルの違い)で、群は3つです。分散分析を行う際には、一般に、群のことを水準と呼ぶので、以降の考え方や計算の説明では水準と呼ぶことにします。また、要因が1つの分散分析のことを一元配置分散分析と呼びます。分散分析の目的は、主に、平均に差があるかどうかを知るということです(「主に」と言ったのには理由があります。つまり、平均以外についても分析できるからです。後述します)。

図1 一元配置分散分析の事例(生成AIによる応答時間の違い)
3種類の生成AIに質問を投げかけたときの応答時間を測定した架空の事例。軽量モデルは探索範囲などが小さく、処理も比較的単純なので、素早く応答を返せると思われる。これらの応答時間の平均に差があるかどうかを知りたい(ここでは、回答の正確さや適切さはここでは考慮していない)。要因は「モデルの違い」で、3つの水準がある一元配置分散分析となる。
分散分析を行うためには、母集団が正規分布に従っていることが前提となっていますが、サンプルサイズが大きい場合や各群のサンプルサイズが同じである場合には比較的頑健である(前提を満たしていなくても、結果に対する悪影響が少ない)と言われています。厳密に進めたい場合には、あらかじめヒストグラムを描いたり、Q-Qプロットを描いたりして、正規性を確認しておくといいでしょう。
さて、ここから分散分析の考え方や手順を見ていきますが、計算の手順がかなり長くなるので、Excelの関数を使って計算するのは現実的ではありません。加えて、詳細な分析を行うには複雑な計算が必要になります。そこで、以下のようにお話を進めます。
- 分散分析の仕組みを知る(この後すぐ、一元配置分散分析を例に)
- Pythonのプログラムを使って簡単に分散分析を行う
- [コラム]分散分析の仕組みをより深く理解する 〜 Excelで手を動かしながら学ぶ
- 多重比較を行ってどこに差があるのかを調べる
さらに、その先では二元配置分散分析にも取り組みます。
では、分散分析の仕組みについて「ざっくりと」お話ししていきましょう。図2を見てください。この段階ではおおまかなイメージをつかむだけで十分です。分散分析では、まず、全体の分散を水準間の分散と水準内の分散に分けます。分散は、言うまでもなく「ばらつき」の大きさを表す値でしたね。水準間の分散が大きければ、平均がばらついているということなので、差があることになります。ただし、水準内での分散が大きいと、その差はあまり信用できません。要するに誤差が大きいということです。逆に、水準間の分散が小さくても、水準内での分散が小さければ、「安定して」差があると考えられます。そこで、水準間の分散を水準内の分散で割って、検定統計量(F値)を求めるというわけです。

図2 一元配置分散分析の仕組み
一元配置分散分析では、全体の分散を水準間の分散と水準内の分散に分け、水準間の分散÷水準内の分散により検定統計量(F値)を求める。水準間の分散が知りたい平均の差で、水準内の分散が誤差だと考えると分かりやすい。平均のばらつき(差)が、誤差に比べてどの程度大きいかを求めているということになる。
上で見たように、分散分析では、分散の比を求めます。従って、その分布はF分布に従うことが分かります。分散の分布がカイ二乗分布に従うことや、F値がカイ二乗値の比であったことを思い出していただければ納得できると思います(この連載の確率分布編第9回でF分布について解説した際にも詳しくお話ししました)。
このような考え方が理解できていれば、実用上それほど困ることはありません。後はできるだけ便利な道具を使うのがお勧めです。これまで、道具としては、一貫してPythonを使っていたので、ここでも簡単なプログラムを紹介しておきます(RやJASPなどの統計ソフトウェアを使うともっと簡単なのですが、インストールの必要があるので、ここでは取り上げません。ただ、今回が最終回ということでもあるので、展望をかねて、後ほど画面だけ掲載します)。
Pythonを使って分散分析を行う 〜 statsmodelsモジュールを利用
では、帰無仮説と対立仮説を確認してから、サンプルプログラムを見てみましょう。
- 帰無仮説H0: 水準間の母平均には差がない
- 帰無仮説H1: 水準間の母平均には差がある
サンプルプログラムはこちらにあります。リンクを開くとPythonのプログラムが表示されるので、最初のコードセルをクリックし、[Shift]+[Enter]キーを押してプログラムを実行すると、結果が表示されます。コードの詳細については、リスト1の下のキャプションを参照してください。
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
# データの読み込み(CSVファイル→pandasデータフレーム)
genai_data = pd.read_csv('https://github.com/Gessys/stat_test/raw/main/genai_data.csv')
# モデルの定義
model = ols('ResponseTime ~ C(Model)', data=genai_data).fit()
# 分散分析表の表示
anova_table = sm.stats.anova_lm(model)
print(anova_table)
一元配置分散分析を行うには、幾つかの方法があるが、ここでは、推定や検定のために使われる汎用(はんよう)的なパッケージであるstatsmodelsモジュールを使った。モデルを定義するために使われているolsはOrdinary Least Squares(最小二乗法)の略(後述する計算方法を見れば、二乗和を求めていることが分かる)。olsの引数に指定されている'ResponseTime ~ C(Model)'は、ResponseTimeがModelに従う(Modelによって決まる)という意味で、C()はカテゴリー変数であることを表すのに使う。fitメソッドを呼び出せば、モデルが作成され、anova_lm関数によって実際に分散分析が実行される。
結果は図3のようになります。
図3 一元配置分散分析の結果
結果はF=5.520、p=0.006<0.01となり、1%有意で帰無仮説(平均に差はない)が棄却される。従って、生成AIのモデルによって応答時間には差があるものと考えられる。
ここで一つ注意点があります。それは、データの形式に関するものです。図1や図2では、いわゆるワイドフォーマット形式で表されたデータを掲載していますが、statsmodelsモジュールを利用する場合や、多くの統計ソフトウェアを利用する場合には、ロングフォーマット形式のデータを与える必要があります。リスト1ではインターネット上に置いてあるロングフォーマット形式のサンプルデータを読み込んでいますが、その一部を掲載しておきます(図4)。

図4 statsmodelsを利用する場合にはロングフォーマットのデータを使う
ロングフォーマットでは、1つの観測データが1行に入力されている。例えば、最初の試行では「Light(軽量モデル)のResponseTime(応答時間)が0.94であった」という具合になっている。図1に示したワイドフォーマットでは、二次元の表の形式になっており、複数の観測データが1行に入力されている。例えば、最初の行は「Lightは0.94、Standardは1.26、Heavyは1.56であった」という具合になっているが、これは別々の3つの試行。
なお、サンプルファイルには、scipy.statsモジュールのf_oneway関数を使った例と、Pingouinパッケージを使った例も含めてあります。詳細については触れませんが、興味のある方は以降のコードセルに書かれたコメントを参照して、実行してみてください。また、Rでの実行例と、JASPでの実行例については、参考として、以下に画面だけ掲載しておきます。

図5 【参考】Rを使った一元配置分散分析の画面
R(この画面はR Studioを利用したもの)のreadrパッケージを利用してCSVファイルを読み込み、aov関数で分散分析を行う。モデルの定義方法はPythonでstatsmodelsを使った場合と似ている(というよりも、statsmodelsがRと似た書き方になっている)。summary関数で分散分析表が表示できる。後述する多重比較も行った画面。Windows、macOS、Linuxで利用可能。

図6 【参考】JASPを使った一元配置分散分析の画面
JASPは最近人気が高まっている統計ソフトウェア。対話的に設定や分析ができるので、プログラミングの知識がなくても使える。データは任意のWebサイトから取得することができないので、ダウンロードしたもの(genai_data.csvファイル)を読み込んで一元配置分散分析を実行。後述する多重比較も行っている。JASPでは、伝統的な検定や分散分析だけでなく、ベイズ統計による検定や分散分析なども全て対話的にできる(実際の処理にはRが呼び出されている)。Windows、macOS、Linux、ChromeOSで利用可能。
コラム 分散分析の仕組みをより深く理解する 〜 Excelで計算してみる
ここまで、一元配置分散分析の考え方とPythonのプログラムを使った実行を紹介してきましたが、実際にどのような計算が行われているのかについてはブラックボックスでした。このコラムでは、そのあたりを少し掘り下げてみたいと思います。数式が幾つか登場するので、苦手な方はこのコラムを読み飛ばして、次の多重比較に進んでいただいても問題ありません。
最初に、分散分析では、全体の分散を水準間の分散と水準内の分散に分ける、というお話をしました。分かりやすくするために、水準iのj番目のデータをxijと表し、
と表すと、
のように分けて表せます。右辺を計算すると、ちゃんと左辺に一致することが分かりますね(確認してみてください)。
「変動」とは「ズレ」とでもいった意味です。「ズレ」と表すより、「変動」と呼んだ方がかっこいいですよね……というぐらいの気持ちで捉えてもらうと身近に感じられると思います。ただし、「全体の変動」と書いた左辺については、取りあえず、1つのデータについて全体の平均との差を取ったものを式として表しただけなので、全体の変動にするには、全てのデータについて合計する必要があります(水準間の変動や水準内の変動についても同じですね)。
ただ、そのまま合計してしまうと、正と負が相殺されて0になってしまうので、例によって二乗して合計しましょう(平方和を求めるということですね)。iとjの両方が変わるので、rを水準の数、niを水準iのデータの個数とすると、
となります。この式の真ん中の項の添え字にはjがないので、j=1からniまで合計するということは、枠で囲んだΣについては同じことをni回行うということになります。つまり、niを掛けるだけでいいですね。従って、
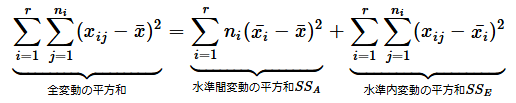
となります。あと一息です。変動の平方和を自由度で割ったものが分散です。水準間変動の平方和をSSA、水準内変動の平方和をSSEと表しましょう。SSAの自由度はr−1で、SSEの自由度はn−rとなります(nは全てのデータの個数です)。
「変動」とは、一般的なズレといった意味ですが、文脈から明らかな場合は、水準間変動の平方和SSAを、単に水準間変動と呼んだり、水準内変動の平方和SSBを単に水準内変動と呼ぶこともあります。
従って、水準間の分散MSAは、MSA=SSA/(r−1)、水準内の分散MSEはMSE=SSE/(n−r)となり、この比がF値となります。なお、分散分析では、SSAやSSEは、一般に「分散」ではなく平均平方と呼ばれます。
です。後は、このF値に対するF分布の右側確率を求めるだけです。ここまでくれば、Excelでも計算できます。
もちろん、Excelで分散分析を行うのは実用的ではありませんが、手を動かして、実際に計算しながら、仕組みの理解を助けるのが趣旨なので、ぜひ取り組んでみてください。こちらからダウンロードしたサンプルを開き、[一元配置分散分析]ワークシートを開いて試してみてください。Googleスプレッドシートのサンプルはこちらから開くことができます。メニューから[ファイル]−[コピーを作成]を選択し、Googleドライブにコピーしてお使いください。手順は図7の後に箇条書きで記します。

図7 【参考】Excelを使った一元配置分散分析の画面
Excelの場合は、ワイドフォーマットの方が計算しやすい。上で記した手順通りに計算すればよい(この後の箇条書きを参照)。結果はPythonなどでの例と同じ。
- セルG4に「=AVERAGE(B4:D23)」と入力する(全体の平均x̄が求められる)
- セルG11に「=SUMSQ(B4:D23-G4)」と入力する(全変動の平方和が求められる)
- セルG10に「=SUMSQ(B4:D23-B26:D26)」と入力する(水準内変動の平方和が求められる)
- セルG9に「=G11-G10」と入力する(水準間変動の平方和が求められる。定義通りに計算しなくても、全変動の平方和=水準間変動の平方和+水準内変動の平方和なので)
- 定義通りに計算したい場合はセルG9に「=SUM(B24:D24*(B26:D26-G4)^2)」と入力してもよい
- セルH9に「=F4-1」と入力する(自由度1が求められる)
- セルH10に「=SUM(B24:D24)-F4」と入力する(自由度2が求められる)
- セルI9に「=G9:G10/H9:H10」と入力する(水準間変動と水準内変動の平均平方が一度に求められる)
- セルJ9に「=I9/I10」と入力する(F値が求められる)
- セルK9に「=F.DIST.RT(J9,H9,H10)」と入力する(p値が求められる)
なお、Googleスプレッドシートでは、配列数式を入力するためにARRAYFORMULA関数を使う必要があります。例えば、セルG11には「=ARRAYFORMULA(SUMSQ(B4:D23-G4))」と入力します。セルG10、セルI9についても同様です。詳細については、作成例のワークシートを参照してください。
どの要因に差があるのかを調べるには 〜 多重比較の利用
一元配置分散分析によって、3群以上の平均の差を検定すると、全体として差があるかどうかは分かりますが、どの群とどの群に差があるかまでは分かりません。というわけで、群ごとの比較を行いましょう。ただし、2群を抜きだしてt検定を行うと、第一種の過誤を犯す確率が増えてしまいます。そのため、p値や有意水準を調整するなどの方法が採られます。例えば、最もシンプルなボンフェローニ(Bonferroni)の方法では、ペアごとにt検定を行い、p値に水準数を掛けて調整を行います。例えば、軽量モデルと標準モデルとでt検定(対応のない両側検定、非等分散)を行うとp=0.206となりますが、水準数の3を掛けてp=0.2063 × 3=0.6189(有意差なし)とします。同様に、標準モデルと重量モデルの場合は、p=0.0512 × 3=0.1536(有意差なし)となり、軽量モデルと重量モデルだけp=0.0021×3=0.0063(1%有意)となります。ただし、ボンフェローニ法はかなり厳格なので(平たく言えば、有意になりにくいので)、各群のサンプルサイズや分散が極端に異ならない場合は、比較的バランスの良い結果が得られるテューキー法(TukeyHSD法)が一般によく使われます。ボンフェローニ法であればExcelでもできますが、TukeyHSD法では、近似計算が必要になるため、Excelでやるのは極めて面倒です。そこで、statsmodelsモジュールを利用してPythonで実行する方法を紹介します。
# TukeyHSD法による多重比較
from statsmodels.stats.multicomp import pairwise_tukeyhsd
# TukeyHSD法
tukey_result = pairwise_tukeyhsd(endog=genai_data['ResponseTime'], groups=genai_data['Model'], alpha=0.05)
# 結果の表示
print(tukey_result)
statsmodels.stats.multicompモジュールのpairwise_tukeyhsd関数に、目的変数と群、有意水準を指定するだけでできる。目的変数を指定する引数endogはEndogenous(内生:モデルの内部で生成される変数)の略。あまりなじみのない用語かもしれないが、経済学などでよく使われる。
結果は図8の通りです。

図8 TukeyHSD法による多重比較
[p-adj]列が調整されたp値。重量モデルと軽量モデルとの間には差があるが、それ以外には差は見られないことが分かる。[reject]列に、帰無仮説が棄却される(True)か、棄却されない(False)かが表示される。
二元配置分散分析の例
一元配置分散分析だけでもうおなかいっぱいという感じかもしれませんね。少し休憩を挟んで、二元配置分散分析にも取り組みましょう。ただし、ここでは、事例と考え方、Pythonのプログラムをサクッと紹介するにとどめます。
二元配置分散分析の主効果と交互作用 〜 考え方を理解しよう
二元配置分散分析では、要因が2つになります。やはり架空の事例で見てみましょう。
生成AIのモデルに与える質問には、単に「〜とは」と解説を求めるものや、「〜はなぜ?」と理由を問うもの、「〜を作ってください」といった文字通り生成を求めるものなどがあります。しかし、ここでは話を簡単にするために、質問を「簡単なもの(easy)」と「難しいもの(difficult)」に分けて、生成AIに与えたものとしましょう。データは以下のような形式になります。

図9 二要因分散分析に使うデータの例(ロングフォーマット)
生成AIのモデル(Model)と質問の難易度(Question)により応答時間(ResponseTime)がどう変わるかを見るのに使われるデータ。Modelの水準がlight/standard/heavyの3つ、Questionの水準がeasy/difficultの2つで、各水準に20件のデータがあるので、全体で20×3×2=120件のデータがある。
図を見ると、要因は、モデルと質問の難易度の2つであることが分かります。従って「二要因」となるわけです。また、それぞれの水準はモデルがlight/standard/heavyの3水準、質問の難易度がeasy/difficultの2水準となっています。
全体像を捉えるために、モデルごとに平均の応答時間を折れ線グラフでプロットしてみます(図10)。このグラフを作成するためのコードもサンプルファイルに含めてあるので、「二元配置分散分析」というタイトルの下のコードセルを実行すれば表示できます。

図10 モデル×質問の難易度によって応答時間をプロットした例
グラフを見ると、モデルによって応答時間に差があること(ちょっと見づらいが、全体的に軽量モデルの方が応答が速い)、質問によって応答時間に差があること(難しい質問では応答時間が長くなる)がなんとなく分かる。また、質問によってモデルの反応時間に違いがありそうだということ(軽量モデルは簡単な質問には素早く応答するが、難しい質問への応答には時間がかかること、重量モデルは簡単な質問でも難しい質問でも同じぐらいの時間がかかること)もなんとなく分かる。
モデルによる応答時間の差と質問の難易度による応答時間の差は主効果と呼ばれます。つまり、ある要因における水準間の差ということですね。一方、質問の難易度とモデルごとの応答時間には何らかの関係がありそうです。その関係のことを交互作用と呼びます。ある要因の特定の水準によって、別の要因での各水準の差に違いが現れる、といったことです。図10のような交差したような(交差しそうな)グラフになることから直感的に理解できると思います。
二元配置分散分析では、これらの効果があるかどうかを検定するというわけです。続けて見てみましょう。さすがにこれをExcelでやるのはほとんどムリです(分析ツールアドインである程度はできますが、かなり制約が多いので、あまり実用的ではありません)。statsmodelsを使ったプログラムは以下のようになります。
# 二元配置分散分析
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
# データの読み込み(CSVファイル→pandasデータフレーム)
genai_data2 = pd.read_csv('https://github.com/Gessys/stat_test/raw/main/genai_data2.csv')
# モデルの定義
formula = 'ResponseTime ~ C(Model) * C(Question)'
model = ols(formula, data=genai_data2).fit()
# 分散分析表の表示
anova_table = sm.stats.anova_lm(model)
print(anova_table)
一元配置分散分析と異なるのは、利用するデータの違いと、'ResponseTime ~ C(Model) * C(Question)'という指定のみ。これはResponseTimeはModelとQuestionの主効果と交互作用によって決まる、という意味。
formulaの指定では、交互作用を「:」で表すので、主効果と交互作用が全て含まれることを想定した場合は、'ResponseTime ~ C(Model) + C(Question) + C(Model) : C(Question)'となりますが、上のように「*」を使って主効果と交互作用が含まれることを略記できます。
上の例は、各水準のサンプルサイズが同じ場合に適した方法です。各水準のサンプルサイズが異なり、交互作用を想定しない場合はanova_lm関数の引数にtyp=2を指定した方法が適しています。また、主効果や交互作用の調整を行う場合にはtyp=3を指定します。各水準のサンプルサイズが同じ場合はtypにどの値を指定しても同じ結果になります(既定の設定はtyp=1です)。詳細については今回の「超入門」のレベルをはるかに超えているので、ここでは触れませんが、いつか機会があれば……。
実行結果は図11の通りです。
図11 二元配置分散分析の結果
[PR(>F)]列を見ると、主効果、交互作用にいずれも有意となっていることが分かる。交互作用があるということは、要因の水準によって差が異なる(例えば、質問の難易度によって生成AIのモデルごとの応答時間に差がある)ということ。
分散分析の結果を見ると、図10のグラフで考えたことがほぼ検証されたといえます。主効果については平均的にモデルによる差や質問の難易度による差はあるといえますが、交互作用が見られるので、水準によってその効果が異なることが考えられます。例えば、図10のグラフを見ても分かるように、軽量モデルでは確かに難しい質問に対して時間がかかっていますが、重量モデルでは質問の難易度による差はなさそうです。また、質問が難しい場合は、どのモデルにも応答時間に差がないようにも見えます。
水準ごとの効果を詳細に見るには、さらに多重比較を行う必要があります。が、これについては、サンプルファイルでの提供にとどめることにします。二元配置分散分析の次のコードセルに、多重比較の例を含めてあるので、ぜひ実行してみてください。結果だけ要約して掲載しておきます。
- 軽量モデルと標準モデルでは質問の難易度による応答時間の差があり、重量モデルでは質問の難易度による差があるとはいえない
- 簡単な質問ではどのモデル間にも応答時間の差があり、難しい質問ではモデル間に差があるとはいえない
となっています(上で想像した通りです)。
分散分析に必要なサンプルサイズを求める
最後に、分散分析を行うに当たって、必要なサンプルサイズの見積もり方法を紹介します。記事では考え方や手順の後に掲載していますが、そもそも、調査や実験を行う前に、決めておくべきことです(毎回言っていることですが)。今回は、実用性を重視して、G*Powerを使った方法だけを紹介します。
一元配置分散分析におけるサンプルサイズの見積もり
まず、効果量Cohen's fの見積もりが必要です。一元配置分散分析から見ていきましょう。まず、以下の式でη2(ηは「イータ」と読みます)の値を見積もります。
例えば、水準間の平方和が3.5、全体の平方和が21と見積もられるのであれば、
となります。先行研究などで、すでにη2が報告されているようであれば、その値を使う方がいいでしょう。次に、Cohen's fを以下の式で求めます。上の値を代入してみます。
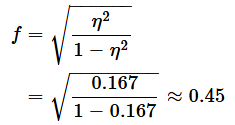
後は、この値をG*Powerで入力するだけです。以下のように指定します。
- [Test family]のリストから「F tests」を選択する
- [Statistical test]のリストから「ANOVA: Fixed effects, omnibus one-way」を選択する
- [Type of power analysis]のリストから「Compute required sample size - given α, power, and effect size」を選択する
メニューバーから[Tests]−[Means]−[Many Groups: ANOVA: One-way(one independent variable)]を選択しても同じ設定になります。有意水準をα=0.05、検出力を1−β=0.8とする場合、さらに以下のように続けます。最初に見た一元配置分散分析では群が3つだったことを思い出してください。
- [Effect size f]ボックスに0.45と入力する
- [α err prob]ボックスに0.05と入力する
- [Power (1-β err prob)]ボックスに0.8と入力する
- [Number of groups]ボックスに3と入力する(群の数)
- [Calculate]ボタンをクリックする
以上の操作で[Total sample size]に結果が表示されます(図12)。

図12 G*Powerで見積もった一元配置分散分析のサンプルサイズ
[Determine]ボタンをクリックすれば、各群の平均やサンプルサイズなどを指定してCohen's fの値を見積もったり、η2の値を基にCohen's fの値を自動的に計算したりすることもできるが、ここではCohen's fの値を直接入力した。[Total sample size]が求められた全体のサンプルサイズ。
この例では、[Total sample size]は51となりますが、この値は各群の値ではなく、全体のサンプルサイズです。従って、各群は51/3=17件ということになります。余裕を見て20件ぐらいのサンプルを収集するといいでしょう。
二元配置分散分析におけるサンプルサイズの見積もり
二元以上の分散分析の場合、以下の式で示されるη2pの値を、想定される主効果や交互作用について求めます。SSeffectはその効果の平方和、SSerrorは誤差の平方和です。一元配置は全体の平方和に対する比でしたが、こちらは、他の要因を除外した平方和に対する比になっています。
それぞれの要因について求めたηp2を上と同様の式でCohen's fに変換します。例えば、今回の例で、SSModel=3, SSQuestion = 19, SSModel:Question = 7, SSerror = 24と見積もられるのであれば、以下のようになります(計算結果だけを掲載します)。ただし、実際には全ての値を求める必要はありません。例えば、Modelの主効果を検出の目的とするのであれば、その値だけで構いません。
G*Powerでの指定は以下の通りです。モデル(Model)の主効果を例に見てみます。
- [Test family]のリストから「F tests」を選択する
- [Statistical test]のリストから「ANOVA: Fixed effects, special, main effects and interactions」を選択する
- [Type of power analysis]のリストから「Compute required sample size - given α, power, and effect size」を選択する
メニューバーから[Tests]−[Means]−[Many Groups: ANOVA: Main effects and interactions(two or more independent variables)]を選択しても同じ設定になります。有意水準をα=0.05、検出力を1−β=0.8とする場合、さらに以下のように続けます。
- [Effect size f]ボックスに0.353と入力する
- [α err prob]ボックスに0.05と入力する
- [Power (1-β err prob)]ボックスに0.8と入力する
- [Numerator df]ボックスに2と入力する(Modelは3水準なので3−1=2とする)
- [Number of groups]ボックスに6と入力する(全体の群の数なので3×2=6とする)
- [Calculate]ボタンをクリックする
[Total sample size]には81と表示されるはずです。他の要因についても同様に計算できます。なお、交互作用については、水準数が3×2なので
[Numerator df]には、(3−1)× (2−1)=2を指定します。それぞれ計算してみると、
- Modelの主効果: 81
- Questionの主効果: 14
- 交互作用: 37
となります。検出したい効果がModelの主効果であれば、全体のサンプルサイズは81、交互作用を検出したいのであれば、全体のサンプルサイズは37となります。
今回は、分散分析超入門と題して、一元配置分散分析と二元配置分散分析について、基本的な考え方と計算の手順を解説しました。分散分析は、これまでのさまざまな検定以上に実際の場面でよく使われます。まだまだ話し足りないことはあるのですが、推測統計(仮説検定編)も最終回となりました。長らくのご愛読ありがとうございました。
……といっても、これで終わりではなく、このシリーズとしては、次にベイズ統計編を予定しています。現在、各回で取り上げる内容を鋭意検討中ですが、理論や数式ゴリゴリといった内容ではなく、実用性を重視し、母数の推定方法(平均やその信用区間の推定など)、モデル選択の方法(例えば、これまでのt検定に代わるベイズ統計の手法など)を中心に、初歩の初歩から、手を動かしながら学べるものとする予定です。ベイズ統計編もどうぞお楽しみに!
Copyright© Digital Advantage Corp. All Rights Reserved.