
第6回 全文検索を実装したソースコードを読もう
倉貫 義人
松村 章弘
TIS株式会社
SonicGarden
2009/9/3
優れたプログラマはコードを書くのと同じくらい、コードを読みこなせなくてはならない。優れたコードを読むことで、自身のスキルも上達するのだ(編集部)
 全文検索機能で情報の収集を便利に実現
全文検索機能で情報の収集を便利に実現
いよいよオープンソースの社内SNS「SKIP」を使ったコードリーディングも最終回となりました。Railsの基本的な構成から、テストコードやRSpecの書き方といった内容に加え、前回はOpenIDをRailsで活用する応用編まで、コードとともに学んできました。
最終回となる今回は、SKIPの目玉機能の1つである全文検索を扱います。最終回にふさわしく、内容も高度なものになっていますが、ここまでおつきあいいただいた読者の皆さまであれば、十分に理解できる内容だと思います。
| 関連リンク: | |
| オープンソース「SKIP」 http://www.openskip.org/ |
|
SKIPにおける全文検索機能では、任意の検索キーワードによってSKIP上に登録されているすべてのデータを横断的に検索できます。SKIPは、社内SNSということで、社内におけるさまざまなデータが蓄積されます。一例を以下に示します。
- ブログの記事やグループ内の掲示板と、そこに書き込まれたコメント
- ファイル共有のためにアップロードされたPDF、Excel、Wordなどのバイナリファイル
- ユーザーが登録するプロフィール情報や紹介文
- ソーシャルブックマーク機能で共有されたURLやコメント情報
このように、SKIPでは種類の異なるデータを多く扱います。全文検索の機能を使うことで、それぞれの情報を個別に探す手間なく、一度の検索で欲しい情報を手に入れられるようになります。
SKIPで実現した全文検索の最大の特徴は、アクセス権限に応じた検索が可能だという点です。データを横断的に検索するだけであれば、それほど工夫は必要ありません。どのユーザーが、どのキーワードで検索しても同じ結果が返ってくれば良いからです。
しかし、SKIPでは社内SNSというアプリケーションの特性上、関係者外秘といったグループ内に閉じた情報共有が行われることがあります。この場合、ユーザーによっては検索結果に見えてはいけない記事やファイルが含まれる場合があります。
そうした場合、通常の閲覧操作ではアクセス権限によって見えなかったファイルが、全文検索によって見えてしまうのでは、不十分なアクセスコントロールといわざるを得ません。
そこで、SKIPの全文検索では、記事やファイルなどのデータごとに設定されたアクセス権限の設定と、検索機能を利用したユーザーの権限に対応した上で、見ることのできない検索結果をフィルタリングする機能を備えています。
例えば、ユーザーAが参加していないグループ内で、「Rails」というキーワードを含んだ記事がグループ内のみ閲覧可能で書かれた場合、ユーザーAが全文検索を使って「Rails」というキーワードで探したとしても、その記事を見つけることはできません。しかし、そのグループに参加したならば、見ることができるようになります。
このように一見すると相容れないアクセス権限と全文検索をうまく組み合わせてユーザーの利便性を実現したのがSKIPの全文検索機能です。そして、この仕組みを実現するために、SKIPでは単純に全文検索エンジンと組み合わせるだけでなく、独自のバックエンドの仕組みを用意しています。
SKIPの全文検索のアーキテクチャ
では、そのSKIPにおける全文検索を実現するために設計したアーキテクチャを説明します。利用者以外に、大きく分けて3つの登場人物から構成されています。
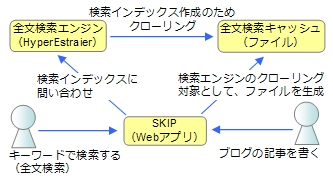
SKIPでは、ユーザーからの応答はすべてWebアプリケーションであるSKIP自身で行います。ユーザーがブログを書いたり、ファイルをアップロードしたりするのも、このSKIPから行います。そして、そこでアップロードされたデータが、全文検索の対象になります。
また、ユーザーが全文検索する場合も同じSKIP上で行います。Webブラウザ上でキーワードを入力し、検索ボタンをクリックすることで、全文検索の結果を得られます。
このときに、高速な全文検索とアクセス権限によるフィルタを実現しているのが、全文検索エンジンと全文検索キャッシュの仕組みです。順に説明していきます。
全文検索エンジン「HyperEstraier」
SKIPでは、全文検索の部分は独自に実装するのではなく、オープンソースの全文検索エンジンを採用しています。それがHyperEstraierです。HyperEstraierも、SKIPと同じく国産のオープンソースで、現在はmixiに所属されている平林氏によって開発されました。
| 関連リンク: | |
| HyperEstraier http://hyperestraier.sourceforge.net/index.ja.html |
|
SKIPでの全文検索の仕組みは、毎回のユーザーからの検索ボタンが実行されたタイミングでデータのスキャンをする訳ではなく、事前にインデックスを作成しておき、検索時はあらかじめ用意されたインデックスから対象を探して結果を返します。これを実現するために、HyperEstraierのインデックス蓄積と検索の機能を活用しています。
また、HyperEstraierに付属するWebクローラ機能を活用しています。このWebクローラ機能は、HTTPで公開されているWebコンテンツに対して、文書内のURLリンクを辿って情報を取得していき、取得した情報をすべてインデックスの中に登録します。SKIPでは、このWebクローラを使い、事前に用意されたデータから情報を収集させて、SKIP用のインデックスを作成させています。
このとき、通常のWebからのアクセスだと、SKIPではログインが必要な上、アクセス権限の設定してある情報にはアクセスできないといった問題があります。このままではWebクローラはSKIPのデータをすべて取得できません。それを解決するのが、次に説明する全文検索キャッシュの仕組みです。
1/4 |
| Index | |
| 全文検索を実装したソースコードを読もう | |
| Page1 全文検索機能で情報の収集を便利に実現 SKIPの全文検索のアーキテクチャ 全文検索エンジン「HyperEstraier」 |
|
| Page2 全文検索キャッシュの仕組み 全文検索の動作の流れ SKIPのソースコード入手方法 |
|
| Page3 キャッシュ生成フェイズのコードを読んでみよう 収集フェイズのコードを読んでみよう |
|
| Page4 検索フェイズのコードを読んでみよう |
|
| Railsコードリーディング 〜scaffoldのその先へ〜 |
| Ruby/Rails関連記事 |
| プログラミングは人生だ まつもと ゆきひろのコーディング天国 ときにプログラミングはスポーツであり、ときにプログラミングは創造である。楽しいプログラミングは人生をより実りあるものにしてくれる |
|
| 生産性を向上させるRuby向け統合開発環境カタログ Ruby on Rails 2.0も強力サポート 生産性が高いと評判のプログラミング言語「Ruby」。統合開発環境を整えることで、さらに効率的なプログラミングが可能になる |
|
| かんたんAjax開発をするためのRailsの基礎知識 Ruby on RailsのRJSでかんたんAjax開発(前編) 実はAjaxアプリケーション開発はあなたが思うよりも簡単です。まずはRuby on Railsの基礎知識から学びましょう |
|
| Praggerとnetpbmで作る画像→AA変換ツール Rubyを使って何か面白いものを作ってみよう! 一般的な画像をアスキーアートに変換するツールを作ってみる。さらに出力にバリエーションを持たせてみよう |
|
| コードリーディングを始めよう Railsコードリーディング〜scaffoldのその先へ〜(1) 優れたプログラマはコードを書くのと同じくらい、読みこなす。優れたコードを読むことで自身のスキルも上達するのだ |
|
- プログラムの実行はどのようにして行われるのか、Linuxカーネルのコードから探る (2017/7/20)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。最終回は、Linuxカーネルの中では、プログラムの起動時にはどのような処理が行われているのかを探る - エンジニアならC言語プログラムの終わりに呼び出されるexit()の中身分かってますよね? (2017/7/13)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。今回は、プログラムの終わりに呼び出されるexit()の中身を探る - VBAにおけるFileDialog操作の基本&ドライブの空き容量、ファイルのサイズやタイムスタンプの取得方法 (2017/7/10)
指定したドライブの空き容量、ファイルのタイムスタンプや属性を取得する方法、FileDialog/エクスプローラー操作の基本を紹介します - さらば残業! 面倒くさいエクセル業務を楽にする「Excel VBA」とは (2017/7/6)
日頃発生する“面倒くさい業務”。簡単なプログラミングで効率化できる可能性がある。本稿では、業務で使うことが多い「Microsoft Excel」で使えるVBAを紹介する。※ショートカットキー、アクセスキーの解説あり
|
|
注目のテーマ





