
 全文検索キャッシュの仕組み
全文検索キャッシュの仕組み
SKIPでは、ブログなどのデータはMySQLのデータベース内で管理しており、Webからのアクセスごとにユーザーのアクセス権限をチェックした上で、画面データを生成しています。HyperEstraierのWebクローラでは、すべてのデータにアクセスできるユーザーがいないため、インデックスを生成するための情報を取得できません。
そこでSKIPからすべての情報をプレーンなHTMLとして出力して、Webクローラがアクセスできるような形にしたものがキャッシュファイルです。このキャッシュファイルには、アクセス権限に関係なく、すべての情報を出力します。
このキャッシュファイルには、Webからのアクセスが可能ですが、WebクローラのみがアクセスできるようにIPレベルで制限をかけて実行しています。
キャッシュファイルの内容は、データベースの中身と同じものになります。Webクローラは、このキャッシュファイルの中身をもとにインデックスを作成します。これで、動的な画面に対するインデックス作成の問題は解決しました。
ただし、このインデックスでは、アクセス権限に関係なく、すべてのデータがヒットします。そこで次に、検索結果を表示する際に、アクセス権限に応じて表示/非表示を切り替えるための仕組みが必要になります。それがメタ情報です。
メタ情報は、キャッシュと同時に1対1で生成されます。メタ情報には、そのキャッシュに対するアクセス権限に関する情報が含まれており、検索結果を表示する際に使われます。
ユーザーからの全文検索が行われた際に、HyeprEstraierのインデックスから検索結果を受け取ると同時に、それぞれのデータに対応するメタ情報にアクセスして、その内容を基に、ユーザーが閲覧可能かどうかの権限チェックを行います。
また、キャッシュファイルはあくまでキャッシュファイルのURLになってしまうので、実体ファイルのURLもメタ情報から取得して置換を行います。メタ情報は、yaml形式のテキストファイルです。
少し分かりづらいところもありますので、次に全体の流れを説明します。
全文検索の動作の流れ
全文検索の動作は、大きく3つのフェイズに分かれます。SKIP上でブログや掲示板の記事を記入することは、一般的な操作なので、それ以降のキャッシュファイルを生成するところから始めます。
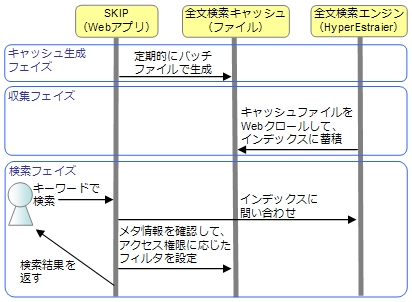
キャッシュ生成フェイズ、収集フェイズ、検索フェイズの3つのフェイズに分かれていて、それぞれの実行は順次行われる訳ではなく、それぞれ並列に実行されます。
キャッシュ生成フェイズでは、SKIPに登録されている情報をキャッシュファイルとメタ情報として出力します。実行されるタイミングは、Webからのユーザーの操作ではなく、15分に1度といった定期的にコマンドラインからRubyプログラムが実行されます。
収集フェイズでは、高速な検索を実現するためのインデックスの作成を行います。Webクローラによって、キャッシュ生成フェイズで作成されたキャッシュファイルに対して、HTTP経由で情報収集を行い、順次インデックス化されていきます。こちらも、定期的に実行されます。
検索フェイズは、ユーザーからの操作によって起動される検索処理を指しています。この検索処理を高速に動作させるために上記2つのフェイズでの準備が必要でした。
ユーザーからキーワードを受け取ったSKIPは、全文検索エンジンのインデックスに対して検索クエリを発行して、キーワードで発見された検索結果の一覧を取得します。ここで得た結果の一覧には、アクセス権限の情報やキャッシュに対応する実体のURLなどが含まれていないので、その情報を全文検索キャッシュにあるメタ情報から取得して、フィルタリングとURLの置換を行っています。そうしてようやく、ユーザーに検索結果を返しています。
長くなりましたが、これでSKIPの全文検索の仕組みについての説明は以上になります。ここからはようやく、全文検索のソースコードを読んでいくことにしましょう。
SKIPのソースコード入手方法
今回コードリーディングに使うソースコードは、前回と同様に、バージョン1.1のものを使います。入手方法などについては、過去の連載を参考にしてください。
| 関連リンク: | |
| SKIP公式ページのアーカイブ(zipで入手) http://www.openskip.org/ja/download/ |
|
| SKIP ver.1.1.0のソースコード(GitHub) http://github.com/openskip/skip/tree/v1.1.0 |
|
2/4 |
| Index | |
| 全文検索を実装したソースコードを読もう | |
| Page1 全文検索機能で情報の収集を便利に実現 SKIPの全文検索のアーキテクチャ 全文検索エンジン「HyperEstraier」 |
|
| Page2 全文検索キャッシュの仕組み 全文検索の動作の流れ SKIPのソースコード入手方法 |
|
| Page3 キャッシュ生成フェイズのコードを読んでみよう 収集フェイズのコードを読んでみよう |
|
| Page4 検索フェイズのコードを読んでみよう |
|
| Railsコードリーディング 〜scaffoldのその先へ〜 |
| Ruby/Rails関連記事 |
| プログラミングは人生だ まつもと ゆきひろのコーディング天国 ときにプログラミングはスポーツであり、ときにプログラミングは創造である。楽しいプログラミングは人生をより実りあるものにしてくれる |
|
| 生産性を向上させるRuby向け統合開発環境カタログ Ruby on Rails 2.0も強力サポート 生産性が高いと評判のプログラミング言語「Ruby」。統合開発環境を整えることで、さらに効率的なプログラミングが可能になる |
|
| かんたんAjax開発をするためのRailsの基礎知識 Ruby on RailsのRJSでかんたんAjax開発(前編) 実はAjaxアプリケーション開発はあなたが思うよりも簡単です。まずはRuby on Railsの基礎知識から学びましょう |
|
| Praggerとnetpbmで作る画像→AA変換ツール Rubyを使って何か面白いものを作ってみよう! 一般的な画像をアスキーアートに変換するツールを作ってみる。さらに出力にバリエーションを持たせてみよう |
|
| コードリーディングを始めよう Railsコードリーディング〜scaffoldのその先へ〜(1) 優れたプログラマはコードを書くのと同じくらい、読みこなす。優れたコードを読むことで自身のスキルも上達するのだ |
|
- プログラムの実行はどのようにして行われるのか、Linuxカーネルのコードから探る (2017/7/20)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。最終回は、Linuxカーネルの中では、プログラムの起動時にはどのような処理が行われているのかを探る - エンジニアならC言語プログラムの終わりに呼び出されるexit()の中身分かってますよね? (2017/7/13)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。今回は、プログラムの終わりに呼び出されるexit()の中身を探る - VBAにおけるFileDialog操作の基本&ドライブの空き容量、ファイルのサイズやタイムスタンプの取得方法 (2017/7/10)
指定したドライブの空き容量、ファイルのタイムスタンプや属性を取得する方法、FileDialog/エクスプローラー操作の基本を紹介します - さらば残業! 面倒くさいエクセル業務を楽にする「Excel VBA」とは (2017/7/6)
日頃発生する“面倒くさい業務”。簡単なプログラミングで効率化できる可能性がある。本稿では、業務で使うことが多い「Microsoft Excel」で使えるVBAを紹介する。※ショートカットキー、アクセスキーの解説あり
|
|
注目のテーマ





