DOMの死角
連載第4回で解説したように、DOMを用いると、XML文書を扱うプログラムを容易に記述することができる。その際、ある名前の要素に関する情報を取得するには、GetElementsByTagNameメソッドという便利なものが使用できることを紹介した。これを使えば、文書ツリーのどこにある要素であっても、メソッド呼び出し1回でそれを発見することができた。しかし、このメソッドには重大な弱点がある。例えば、以下のようなXML文書があったとしよう。
<?xml version='1.0' encoding="UTF-8" ?>
<書籍情報>
<編集者 id="editor123">
<名前>海野波男</名前>
<所属>海浜出版</所属>
</編集者>
<著者 id="writer201">
<名前>山岡岳男</名前>
<所属>山岳協会</所属>
</著者>
<著者 id="writer302">
<名前>野原草男</名前>
<所属>原野愛好会</所属>
</著者>
<著者 id="writer404">
<名前>森野大樹</名前>
<所属>森林保護会</所属>
</著者>
</書籍情報>
|
|
| サンプルとするXML文書1(C:\sample.xml) |
|
|
このXML文書に含まれる著者の名前に関する情報を取得したいとしよう。それをGetElementsByTagNameメソッドで実現しようとすると、やっかいなことになる。もし名前という要素を調べさせると、編集者の名前もまとめてヒットしてしまう。これを回避するには、GetElementsByTagNameメソッドを使うだけでは不十分で、このメソッドの結果をさらにチェックしなければならない。例えば、以下のようなコードでそれを実現できる。
Private Sub Form1_Load(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles MyBase.Load
Dim doc As XmlDocument = New XmlDocument()
doc.Load("c:\sample.xml")
Dim list As XmlNodeList = doc.GetElementsByTagName("名前")
Dim node As XmlNode
For Each node In list
If node.ParentNode.NodeType = XmlNodeType.Element _
AndAlso node.ParentNode.Name = "著者" Then
Trace.WriteLine(node.InnerText)
End If
Next
End Sub
|
|
| 著者の名前を取得するサンプル(VB.NET版/C#版) |
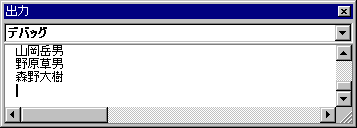
これを実行すると以下のようになる。
このように、編集者要素の子要素である名前に記述された海野波男という名前は表示されていない。
このサンプル・プログラムでは、発見した要素のノードに対して、ParentNodeプロパティを使用して親要素のノードを取得している。そして、NodeTypeプロパティで要素ノードである(XmlNodeType.Element)ということと、Nameプロパティが“著者”であることを確認した上で処理を行うようにしている。
この程度なら、ちょっとやる気を出せばすぐ記述できるが、条件が複雑になってくると大変である。
これを解決するうまい方法はないだろうか。それには、式を用いてより複雑な条件でノードを探し出す方法がある。これが「XPath」を用いる方法である。
|
■サンプル・プログラムについて
今回もサンプル・プログラムは、Visual Basic .NET(以下VB.NET)とC#のものを用意した。VB.NETのサンプルを掲載するとともに、VB.NET、C#それぞれのサンプルへのリンクを張ってあるので、必要に応じてダウンロードしてほしい。また、開発環境としてはVisual Studio .NET 2002を使用することを前提にしている。サンプル・プログラムはすべてWindowsアプリケーションとしてプロジェクトを作成後に、フォームのLoadイベントに実行するコードを書き込み、Trace.WriteLineメソッドで結果を出力する。結果は統合開発環境の出力ウィンドウで確認するように構成されている。それぞれのソースの先頭には、以下のコードが書かれているものとする。
using System.Xml;
using System.Diagnostics;
|
|
| C#の場合 |
|
Insider.NET 記事ランキング
本日
月間