
連載 DB2でXMLを操作する(3)
XML Columnを使うための設計・実装
| XMLの普及とともにリレーショナルデータベースにもXMLを格納できる機能が搭載されてきている。しかしその機能は、製品ごとに固有のものだ。この記事では、IBMの製品であるDB2
UDBでどのようにXMLを扱うか、について解説する。 たがわ製作所 2003/2/26 |
| 今回の主な内容 |
前回「DB2 UDBのインストールと動作確認」でようやくDB2のセットアップが終わりました。今回からいよいよXMLの操作に取り掛かります。
連載の第1回「XMLの格納方法を2種類備えるDB2」で取り上げたように、DB2はXMLを格納する方式として、「XML Column」と「XML Collection」を用意しています。まずは、今回と次回の2回に分けてXML Columnについて解説します。今回はXML Columnを利用するためのセットアップ手順について概説し、次回でサンプルを交えながら実際の操作例を取り上げる予定です。
まずはXML Columnの概要について簡単におさらいしておきます。XML Columnとはひとことでいって、CLOBの派生型を持つカラムに、XMLの文書をそのまま格納する方式でした。そしてただ格納するだけでなく、検索を高速に行うためにサイドテーブルというものを用います(図1)。
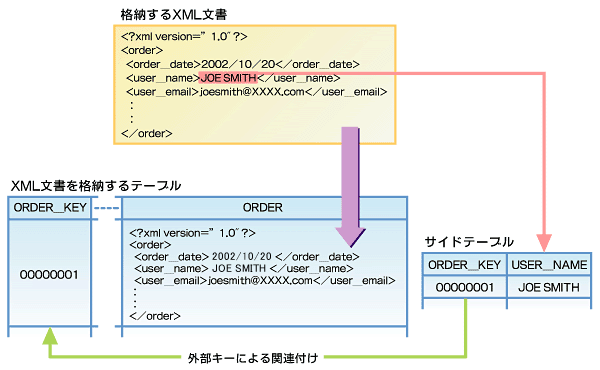 |
| 図1 XML Columnの考え方(クリックで拡大します) XML文書をそのまま格納したうえで、サイドテーブルに検索用の補助情報を追加する |
このような仕組みを持つXML Columnに適したケースについても、もう一度確認しておきましょう。
●XML Columnに向いているケース
- 更新をほとんど行わない
- 頻繁に検索する条件が分かっている
- 元のXML文書をそのまま保持しておきたい
- XML文書自体はファイルシステムに置いておきたい
では、早速XML Columnのセットアップに取り掛かることとしましょう。
■XML ColumnのセットアップXML Columnのセットアップを始めるに当たり、事前に以下のような事項を検討しておく必要があります。
- XMLデータタイプ
- 文書型の検証の有無
- インデックス対象のエレメントおよび属性
- サイドテーブルの構成
- デフォルトビューの有無
これらは、いわばXML Columnを用いるうえでの設計作業といえます。この設計作業の結果に基づいて、以下のようなセットアップ作業を実際に行うことになります。
- DADファイルの定義
- XMLエクステンダーの有効化
- テーブルの作成
- DTDの登録
- DADファイルの登録およびXML Columnの有効化
- インデックスの作成
こちらはXML Columnを用いるための実装作業といえるでしょう。この設計作業と実装作業の詳細について以下で見てみます。
(1)XMLデータタイプXML Columnでは、XMLの文書そのものをカラムに格納します。そのときのカラムの型として以下の3つのユーザー定義型のいずれかを利用できます。
- XMLVARCHAR
- XMLCLOB
- XMLFILE
XMLVARCHARはVARCHARから派生している型であり、32672bytesまでのXML文書を格納できます。同様にXMLCLOBはCLOBから派生したものであり、2GバイトまでのXML文書を格納できます。
3つ目のXMLFILEは少し特殊です。これは、ファイルシステム上のXML文書を間接的に参照するためのもので、512バイトまでのパスを格納することができます。XML文書のファイル自体はファイルシステム上に格納して利用したい、というような場合に有効です。
(2)文書型の検証の有無XMLの文書をデータベースへ登録する際に、その文書が特定の文書型に適合しているかどうかDTDを基に検証を行うことができます。後述するサイドテーブルの仕組みなどは、検索対象のエレメント(要素)が正しく文書に含まれていることが前提になるので、可能ならば検証は行いたいところです。
しかし、検証作業には文書の長さに比例して若干なりとも時間がかかるので、アプリケーションの要件などから総合的に見て検証を行うかどうか検討する必要があります。例えば、登録するXML文書が機械的に生成され、文書型に適合することが保証されているような場合は検証する必要はありません。しかし、人間の作成したXML文書を登録するような場合は検証すべきでしょう。また、登録済みの文書を一度に検証するような仕組みは用意されていないのでその点も注意する必要があります。
(3)インデックス対象の要素および属性頻繁に検索の対象として用いられる要素および属性が何かを確認します。これらの要素および属性を、後述のサイドテーブルにあらかじめ抽出しておくことで、高速に検索ができるようになります。検索対象を指定するには、XPathのロケーションパスを簡略化した単純ロケーションパスを用います。単純ロケーションパスは、以下の2種類のいずれかの形しか許されません。
- /tag_1/tag_2/..../tag_n
- /tag_1/tag_2/..../tag_n/@attr1
上記2つの意味は、XPathに馴じんだ方には説明不要でしょう。前者は文書中の要素の位置を文書ルートから指定するものであり、後者は同じく属性の位置を指定するものです。なお、検索対象となるロケーションは複数あっても構いません(注:効率はあまりよくありませんが、サイドテーブルに含まれないロケーションのデータを対象にした検索も可能です)。
(4)サイドテーブルの構成インデックス対象のデータを格納するためのサイドテーブル構成を検討します。サイドテーブルは、XML文書が登録および更新されるたび、自動的に更新される仕組みになっています。インデックス対象が複数ある場合でも、通常は1つのサイドテーブルを用意するだけで十分です。ただし、ロケーションパスが複数の要素に対応するような場合、それらのロケーションパスごとにサイドテーブルを1つずつ用意する必要があります。
(5)デフォルトビューの有無XML文書の検索については次回詳しく述べる予定ですが、簡単に述べると以下のような流れの処理になります。
- XML文書が格納されたテーブルとサイドテーブルを結合する
- サイドテーブルのカラムの値に基づいて条件を指定する
- 選択された行からXML文書を取り出す
見てお分かりのように、検索を行うたびにサイドテーブルと元のテーブルの結合を実行する必要があります。毎回いちいち結合条件を指定するのは面倒ですから、結合したものをビューとして定義しておくと便利です。明示的に定義することはもちろん可能ですが、デフォルトビューと呼ばれるビューを自動的に生成することが可能です。
この機能は便利ですが、サイドテーブルがすべて結合されたビューになるため、サイドテーブルの個数が多くなるような場合は注意が必要です。検索に必ずしも必要でないサイドテーブルもビューに含まれることになるため、検索時のパフォーマンスが低下する可能性があります。デフォルトビューの使用は、サイドテーブルの個数が少ない場合に限った方がよいでしょう。
データベースに登録するXML文書を基にして、ここに挙げた項目についてあらかじめ検討したら、続いてはXML Columnの実装作業に入ります。
(1)DADファイルの定義以上の設計結果に基づいて実際の文書格納方法を定義するものがDocument Access Definitionファイル(DADファイル)と呼ばれるものです。このDADファイルには以下の情報が含まれる形になります。
- 格納方式(XML ColumnもしくはXML Collection)
- サイドテーブルの定義
- 文書検証の有無
- 検証を行う場合に用いるDTD
DADファイル自体はXMLの形式で記述します。厳密なDTDについてはマニュアルを見ていただくとして、ここではXML Columnを用いる場合の一般的な形を示しておきます(リスト1)。
<?xml version="1.0" ?>
|
| リスト1 XML Columnを用いる場合のDADファイルの記述(dad-xcolumn.txt) |
ご覧のとおり、ルートタグは<DAD>です。その下位要素は、それぞれ以下のような意味を持ちます。
|
<dtdid> <Xcolumn> <table> <column> |
(2)XMLエクステンダーの有効化
DB2のエクステンダーとは、一般的にいって以下のオブジェクトの集合です。
- ユーザー定義型
- ユーザー定義関数
- ストアドプロシージャ
実際にこれらを利用するに当たっては、データベースにバインドし、有効化する必要があります。有効化の作業はGUIを用いた管理ツールでも可能ですが、ここではコマンドラインから行う手順を紹介しましょう。DB2のコマンド・ウィンドウをオープンして、データベースに接続してください。
db2 connect to データベース名 |
まず、パッケージ(注:静的SQLを実行するための制御情報)のバインド作業を行います。DB2のインストールされたディレクトリの下にある、bndというサブディレクトリに移動してください。ここで以下のコマンドを実行します。
db2 bind @dxxbind.lst |
これはXMLエクステンダーのクライアントツールを用いるために必要な作業です。画面1のように警告が出力されますが、取りあえず気にしなくて構いません。
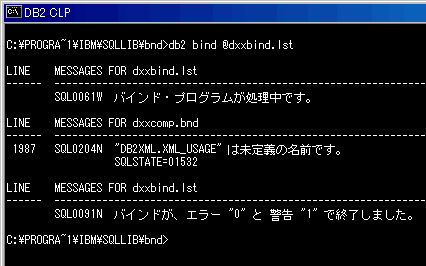 |
| 画面1 パッケージのバインド |
次に管理コマンドdxxadmを用いてデータベースの有効化を行います。同じくコマンド・ウィンドウから以下のコマンドを実行してください。
dxxadm enable_db データベース名 |
画面2のような出力を確認できればデータベースの有効化は完了です(この例ではsampleという名前のデータベースを有効化しています)。
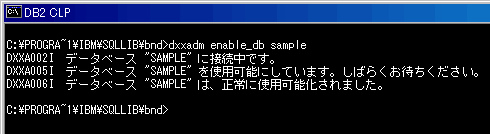 |
| 画面2 データベースの有効化 |
(3)テーブルの作成
以上でXMLエクステンダーを利用するうえでの準備は整ったといえます。次は具体的にXML文書を格納するためのテーブルを作成してみましょう。新規にテーブルを作成するのであれば、CREATE TABLEコマンドを用います。既存のテーブルにXMLデータタイプのカラムを追加するのであればALTER TABLEコマンドを用いればよいでしょう。
ここで注意すべき点はXMLデータタイプの指定方法です。XMLVARCHARやXMLCLOBなどのユーザー定義型は、すべてDB2XMLというスキーマに作成されています。通常はこれとは異なるスキーマを利用しているはずですから、これらのユーザー定義型を指定する場合は、スキーマを含めた完全修飾名で指定せねばなりません。例えば、XMLVARCHARのカラムを持つテーブルを作成するような場合は、以下のような形になります。
CREATE TABLE テーブル名 (カラム名 DB2XML.XMLVARCHAR) |
(4)DTDの登録
文書型の検証を行う場合は、検証に用いるDTDをあらかじめ登録しておく必要があります。具体的には、DTD_REFと呼ばれる定義済みのテーブルに以下のようなSQLを用いて登録します。
INSERT INTO DB2XML.DTD_REF |
DTD名は、登録するDTDを一意に識別するための名前です。何か区別できる名前を与えて登録します。最後に3つばかり'user'というパラメータが並んでいますが、これは現在のところ未使用のパラメータです。適当な文字列を指定して構わないでしょう。
(5)DADファイルの登録およびXML Columnの有効化
XML Columnを作成しても、それは単に入れ物を用意しただけにすぎません。サイドテーブルを定義し、その入れ物の更新に従って自動的にサイドテーブルを更新するようにするには、カラムを有効化する作業が必要です。この有効化の作業は、dxxadmコマンドを用いて行います。
dxxadm enable_column データベース名 テーブル名 カラム名
DADファイル名 [ -v デフォルトビュー名 ] |
見てお分かりのように、カラムの有効化の作業でようやくDADファイルが登場します。DADファイルに含まれた情報に基づいてサイドテーブルを作成し、XML文書を格納するカラムと対応付けを行うわけです。
(6)インデックスの作成
XML文書の検索を行ううえで実際にスキャンされるのはサイドテーブルです。サイドテーブルのカラムには当然インデックスが必要になってきますが、XML Columnを有効化しただけでは自動的に作成されません。CREATE INDEXコマンドを用いて通常のテーブルと同じようにインデックスを定義する必要があります。
◆
今回はXML Columnのセットアップ手順について概説してみました。具体的なサンプルは次回紹介する予定ですが、それまでに読者の皆さんもXML Columnを用いた例を考えてみられるとよいでしょう。次回は、具体的なサンプルを用いたセットアップ例に加え、XML文書の登録や検索といった操作についても解説したいと思います。お楽しみに!
| <<前回へ | 「XML
ColumnにDocBook文書を格納する」 |
| Index | |
| 連載:DB2でXMLを操作する | |
| (1) XMLの格納方法を2種類備えるDB2 | |
| (2) DB2 UDBのインストールと動作確認 | |
| (3) XML Columnを使うための設計・実装 | |
| (4) XML ColumnにDocBook文書を格納する | |
| (5) XML Collectionを使うための設計・実装 | |
| (6) XML Collectionでデータマッピングを実現 | |
| (最終回) Webサービス機能を徹底検証する | |
- QAフレームワーク:仕様ガイドラインが勧告に昇格 (2005/10/21)
データベースの急速なXML対応に後押しされてか、9月に入って「XQuery」や「XPath」に関係したドラフトが一気に11本も更新された - XML勧告を記述するXMLspecとは何か (2005/10/12)
「XML 1.0勧告」はXMLspec DTDで記述され、XSLTによって生成されている。これはXMLが本当に役立っている具体的な証である - 文字符号化方式にまつわるジレンマ (2005/9/13)
文字符号化方式(UTF-8、シフトJISなど)を自動検出するには、ニワトリと卵の関係にあるジレンマを解消する仕組みが必要となる - XMLキー管理仕様(XKMS 2.0)が勧告に昇格 (2005/8/16)
セキュリティ関連のXML仕様に進展あり。また、日本発の新しいXMLソフトウェアアーキテクチャ「xfy technology」の詳細も紹介する
|
|





