Webサーバの障害をいかに切り分けるか:24×365のシステム管理(2)
システムの安定稼働を実現するためには、常日ごろの管理体制が重要になってきます。今回は、企業にとっての顔ともいえる「Webサーバの運用・監視」に焦点をあて、その概要や生涯の切り分け方を解説していきます。本連載を初めて読まれる方は、「連載:24×365のシステム管理 第1回 運用管理に必須のツール/コマンド群」もぜひご一読ください。(編集局)
皆さんが、24時間365日稼働し続けるサーバとして最初にイメージするのは、やはりWebサーバだろう。一般に向けて公開しているWebサーバは、まさに企業の顔といえる存在だ。特にコンテンツ・サービスを提供している場合、稼働状況はそのまま企業の信用につながるといっても過言ではない。そこで、今回と次回の2回にわたり、Webサーバの運用・監視方法について解説する。
障害の原因を探る障害の原因を探る
では、管理しているWebサーバに障害が発生した場合、管理者は何をすればいいのだろうか。この問題の答えは単純明快で、「障害を解決してサービスを復旧する」だけだ。しかし、実際は言葉ほど単純ではない。発生した障害の原因によって対処方法が異なるため、障害の原因を明確化しなければ、Webサーバを正常な状態に戻すことができないからである。
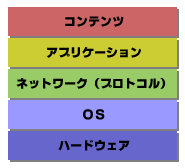
障害の原因を特定するには、まず障害がどのレベルで発生しているのかを確認する作業から始まる。Webサーバの障害は、図1のようなレイヤに分類することができる。
どのレイヤで障害が発生したかを検証するためには、堅実に下のレイヤから順番に確認していくのがベストだ。
●疎通の確認
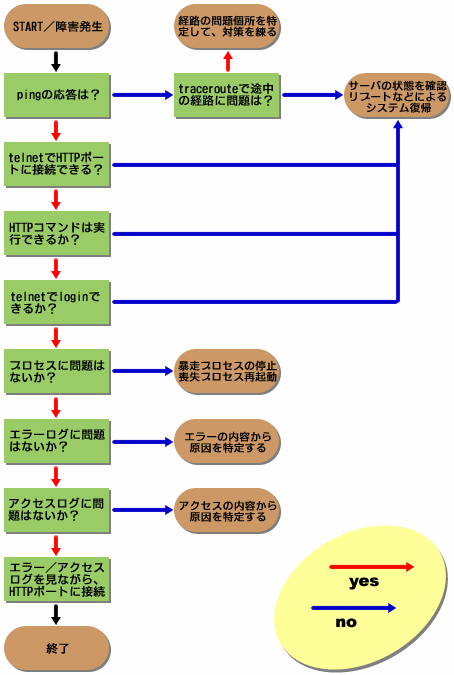
まず、障害の発生したWebサーバが、IPレイヤのレベルでアクティブであることを確認するために、pingを実行(「ICMP
echo request」パケットの送信)する。Webサーバからpingに対する応答(「ICMP echo reply」の受信)がなければ、IPレイヤのレベルで到達性がないと判断できる(ICMPの詳細は連載:ネットワーク・コマンドでトラブル解決「ネットワークの疎通を確認するには」を参照)。
pingの応答が返ってこなかった場合、対象のWebサーバに問題があるのか、それとも途中の経路に問題があるのかを切り分ける必要がある。そこで、traceroute*1コマンドを実行して、途中経路から返信される「ICMP
time exceeded」を確認する。途中経路から問題なく「ICMP time exceeded」が返ってきているのであれば、やはり問題はWebサーバにある。
*1Windows系プラットフォームでのコマンド名は「tracert」
pingによる疎通の確認に失敗した場合には、リモートからの検証はこれ以上不可能なことがほとんどであるため、管理者は物理的に設置されているWebサーバの機器を確認する必要がある。具体的には、実際にWebサーバのコンソールやシリアル・ポートなどを経由してサーバの状態を確認し、必要があればシステムのリブートなどを行ってシステムを復帰させる。
pingに対する応答があっても、管理者は即座に喜ぶことはできない。pingの応答で確認できるのは、「少なくともpingに応答してくれる機器がある」ということだけで、障害の原因を特定できているわけではない。しかも、pingを実行する場所とWebサーバの間に、ルータやロード・バランサなどの機器が存在する場合、Webサーバ以外の機器がpingに応答している可能性も高い。Webサーバがpingに応答しているとしても、判断できるのは「WebサーバがIPレイヤのレベルではアクティブである」という事実だけである。
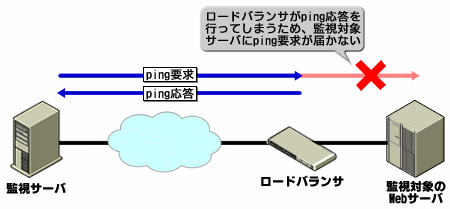
図2 pingの応答があるだけでは、Webサーバが動作していると判断できない。本来は、監視対象サーバに対してpingを送りたいのだが、その前にロード・バランサやファイアウォールがあると、その機器がpingの応答を返してしまうため、正確な監視ができない
●サービスの稼働確認
IPレベルでの疎通が確認できるようであれば、次にサービス(プロトコル)が稼働していることを確認するために、TCPポートへの接続を試みる。障害が発生しているのはWebサーバであるため、接続先のポートはHTTPのポート(標準では80番)になる。ここで、TCPセッションを確立する最も一般的な手法はtelnetだろう。ただし、Windows標準のtelnetクライアントは、あまり機能的とはいえないため、「Tera Term」など別のtelnetクライアントを使用するか、可能ならばUNIX環境からの実行をお勧めする。
telnetでホスト名を指定して、80番ポートとのセッションが確立するのであれば、TCPセッションのレベルでは問題がないことが判明する。逆にリクエストがタイムアウトしたり、「no route to host」のようなエラーメッセージが出たりした場合には、システムがダウンしていると考えるのが自然だ。「no route to host」のメッセージは、通常はDNSが引けないなどのネットワーク的な問題で表示される。しかし、DNSが引けてもホストの電源が落ちているというような理由で表示されることがある。
ただし、telnetによるTCPセッションが確立できない場合でも、エラーによっては必ずしも相手側の問題ではない可能性もある。例えば、管理者が作業しているコンピュータからWebサーバへの接続が許可されていなければ、「connection refused」というメッセージが表示されたり、一度接続できてから「connection closed by foreign host」というメッセージが表示されて接続を拒否される。
80番ポートへの接続が確認されたところで、HTTPのプロトコル・コマンドをタイプすることで、Webサーバのサービス・レベルでの稼働を確認することができる。具体的には、
GET / HTTP/1.0<HTMLreturn><HTMLreturn>
とtelnetクライアントに直接タイプすることで、Webサーバの動作をHTTPのプロトコルレベルで確認できる。このとき、エラーメッセージが出てセッションが中断されるようであると、サーバの設定の問題であると考えるのが一般的だ。
Windows標準のtelnetクライアントの問題点
Windows標準のtelnetクライアントの問題点は、エラーを詳細に表示してくれないことだろう。UNIXなどの伝統的なtelnetクライアントでは、ミスタイプなどで存在しないホストを指定した場合には「Unknown
host」、相手に接続を拒否された場合には「connection refused」などエラーを詳細に表示してくれる。ところが、Windowsのtelnetクライアントは、どちらの場合にも「接続に失敗しました」というメッセージしか返さない。なぜ接続に失敗したのかを明確にしないため、障害の検知などの作業に不向きである。また、細かい問題ではあるが、記事の本文にあるようにWebサーバのTCPポートへ接続を確立すると、不思議なことにWindows標準のtelnetクライアントは、画面をクリアしてしまう。telnet以外のポートに接続したときに、自動的にlocalechoにならないのも使い勝手が悪いように思う。
●サーバにログインしてシステムの情報を取得する
ここまでの確認が済んだら、いよいよtelnetで実際のWebサーバにログインしてみる。もちろん、このフェーズも障害切り分けの1つの要因になる。もし、ログインを試みたものの、loginプロンプトも表示されずにタイムアウトしたのであれば、やはりシステム(あるいはネットワーク)の障害の可能性が高い。ただし、パスワードの有効期限や、ファイアウォールなどによるアクセス制限で失敗することもあるので、エラーメッセージは必ず確認する。
Webサーバへのログインに成功したら、次はシステムの情報を確認する。確認のために取得するべき情報には、次のようなものが挙げられる。
- プロセスの稼働状況
- エラー・ログ
- アクセス・ログ
まず、最初に必要なプロセスが正しく動作していることを確認する。暴走していたりした場合には、正しくプロセスを再起動することが必要となる。
次にシステムのログを参照する。エラー・ログを参照すれば、いつ障害が発生したのかをある程度究明できる。エラー・ログに問題がない場合、アクセス・ログを参照して、障害発生時にどのようなアクセスがあったのかを確認する。アクセス・ログを参照しながら、HTTPポートとのTCPセッションを確立して、アクセス・ログやエラー・ログに何が記録されるかを確認してみると、意外な問題が判明することもある。
●障害の原因が究明できない場合
ここまで障害の切り分け作業を実行しても、原因を特定できないことがある。その場合には、システムをリブートして、しばらく様子を見る。しかし、障害の原因が特定されていない場合、同じ障害が再び発生する可能性が高い。システムが稼働している間に、失われると困るデータなどをバックアップすることを、忘れずに実行しよう。また、機材に余裕がある場合は予備機を準備しておくことを推奨する。
Webサーバを監視して、すばやく障害を検知する
ここまでは、すでに発生した障害を切り分ける方法について解説してきた。しかし、24時間365日に限りなく近いシステム稼働の維持に本当に必要なのは、常にシステムを監視して素早く障害を検知することである。システム障害の時間を最小限に抑えることで、システムの信頼性を向上させることは、これからの管理者の義務といえる。また、小さな障害を検知することで、致命的なシステムのクラッシュを避けられる可能性も高い。
システム監視は、特定の管理者が定期的に手動で監視するには限界がある。監視作業の大部分を自動化することによって、システム監視は高い効果を得ることができる。比較的単純な監視であれば、スクリプトなどを自動化することができるため、小規模なシステムでも十分に効果は得られる、また、フリーの監視ツールを利用するのも効果的だ。
では、実際にどのような作業を自動化すればいいのだろうか。
●サービス稼働監視
実際にWebサーバから、HTTPで情報をGETする。定期的に監視すれば、Webサービスが稼働し続けていることを確認できる。また、GETしたWebページの内容を比較し、ページの改ざんなどを検知することもできる。
あるいは、定期的にWebサーバのHTTPポートと接続を確立させるのも、TCPレイヤのレベルでのサービス稼働監視である。
●定期的なpingの発行
最も自動化が楽な監視は、定期的なpingコマンドの発行だろう。数分置きにpingコマンドを発行し、Webサーバへの疎通が失われたことを早い段階で検知することができる。
●SNMPのポーリング
SNMPを使用して、監視対象のWebサーバの情報を定期的に取得する。ただし、取得した情報を“しきい値”と比較して通知する処理がやや煩雑になる。
●エージェントによる監視の実行
監視対象のWebサーバに監視エージェントをインストールして、機器の情報を通知させる方法。リモートからでは分かり得ない、プロセス監視や、ログ監視などのシステムのリソースに対する高機能な監視を実現できる。
監視ポリシーなどの作成と障害対応ログの記録
比較的おざなりにされがちな問題として、監視ポリシーの策定、障害対応マニュアルの作成、障害対応ログの記録がある。システム監視が安定していなければ、システムそのものの安定度も低い傾向がある。稼働し続けるシステムを安定して運用するためには、ポリシーを明確化したシステム監視が必須である。また、その監視ポリシーに沿った監視手順書、障害対応マニュアルを作成することで、より確実で安定したシステム監視が可能になる。
さらに、システムの障害が発生するごとに、障害対応のログを記録しておく。ログに記録するのは次のような情報である。
- 障害検知時刻
- 障害対応担当者
- 障害の発生した機器
- 症状
- 障害対応手順
特に、最後の障害対応手順は、時系列でなるべく詳細に、実行したコマンドや交換したハードウェアの情報を記録していく。また、このように障害対応を実行するたびに、現在の監視ポリシー、監視手順書、障害対応マニュアルに無理がなかったかを見直す。始めたばかりのころは管理ポリシーなどに矛盾や穴がたくさんあるが、障害が発生するたびに見直していくことで、障害対応のノウハウが蓄積する。これらのノウハウは、システム管理者にとって、何物にも代え難い価値ある資産となる。
今回は、障害の切り分けと監視の概要を中心に解説した。次回は実際にフリーの監視ツールを使ったシステム監視を詳細に解説する予定だ。
Copyright © ITmedia, Inc. All Rights Reserved.