運用管理に必須のツール/コマンド群:24×365のシステム管理(1)
システムの安定稼働を実現するためには、常日ごろの管理体制が重要になってきます。本連載では、システムの運用管理に必要な知識や、一般的な例を基にした管理テクニックなどを紹介していきます。もし、管理に関する業務を専門業者に任せているような環境でも、トラブルケースを知っておくことで、いざという場面でどのような事態が起こっているのか理解できるようになります。まずは実践に入る前に、システム管理の予備知識について解説していきましょう(編集局)
24時間365日の稼働を目指して
近年のコンピュータ業界の動向はネットワーク技術、特にインターネットに代表されるIPネットワーク技術を抜きに語ることはできない。いまや家庭でもPCを購入すればインターネットへの接続が当たり前となり、オフィスにおいてPCは筆記用具などの事務用品と同等(またはそれ以上)の道具である。複数のコンピュータがあれば、インターネットインフラなどの資産を共有するために、自然とLANなどのネットワークが構築される。
また企業では、メールやWebといったサービスを提供することが多い。これらのサービスは、単に社内向けのメール・システムであったり、大規模なeビジネスの根幹を成すサービスであったりとさまざまである。多くのユーザーが利用するシステムでは、規模によって要求される深刻さに違いはあるものの、24時間365日ノンストップで稼働することが理想である。しかし残念なことに、システムを構成する回線、ハードウェア、ソフトウェアには、必ず障害が発生する。絶対に止まらないシステムを構築することは不可能である。システム管理者の役割は「限りなく100%に近い状態でシステムを稼働させる」ことにあるといえるだろう。
フリーの監視ツールとシステム管理のポイント
システム管理に当たって、何が必要になるのだろうか。市販の管理ツールの使用や、専門の業者に任せるという方法もあるだろう。だが、社内(部署)LANなど小・中規模のシステムでは、コスト面での問題から難しいということも多い。その場合、システム管理者にはある程度専門的な知識が必要になるが、定期的にコマンドやスクリプトを実行することでシステムを監視するという選択肢がある。また、フリーの監視ツールを使用して監視することも可能だ。定期的に監視しなければならない項目が多い場合は、専用の監視ツールを使用して監視を自動化した方が、結果的にシステム管理にかかるコストを軽減することができる。
システム監視ツールには、大きく分けて2種類の動作がある。1つは監視サーバ(監視ツールの動作しているサーバ)からリモートで監視する方式で、おもにICMPやTCPでの死活監視、SNMPのポーリングなどが挙げられる。もう1つは監視エージェントによる監視方式で、監視対象機器に監視を実行するエージェントをインストールし、取得したシステムの監視情報を監視サーバに通知する。いずれの方式にもメリット/デメリットがあるので、監視の目的にあった方式を選択する必要がある。
リモート監視
監視サーバは、定期的にICMP、TCPなどで、対象機器を監視する
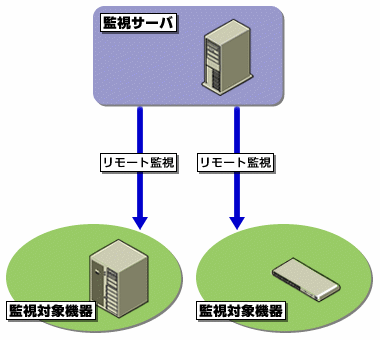 図1 リモート監視のメリットとしては、監視対象となるシステムに影響を与えずに監視できることが挙げられる。デメリットは、取得できる監視情報に限界があることだ
図1 リモート監視のメリットとしては、監視対象となるシステムに影響を与えずに監視できることが挙げられる。デメリットは、取得できる監視情報に限界があることだエージェント監視
監視エージェントが、監視対象機器の管理情報を監視サーバに通知する
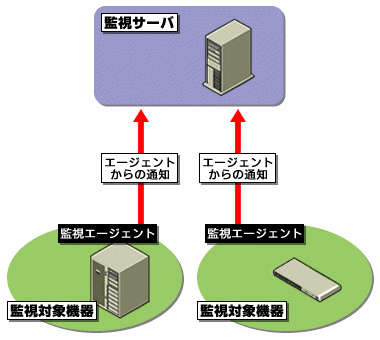 図2 エージェント監視では、より詳細な監視データを取得できるメリットがある(そのほか、システム運用が可能になるエージェントもある)。反面、監視対象となるシステムに影響を与えるというデメリットがある
図2 エージェント監視では、より詳細な監視データを取得できるメリットがある(そのほか、システム運用が可能になるエージェントもある)。反面、監視対象となるシステムに影響を与えるというデメリットがある監視ツールには、フリーのツールも含めて、かなりの種類が存在する。その中でも、やはりUNIXやLinuxでのみ動作可能というものが多い。代表的なフリーの監視ツールには、ネットワークの稼働状況をグラフ化する「MRTG」や高機能監視ツール「NetSaint」などがある。いずれにしても、監視ツールを使用する場合には、ツールを実行させる「監視サーバ」を独立させることを推奨する。
では具体的に、システム管理者はどのようにシステムの管理を実行すればいいのだろうか。最近では、PCやサーバ機器以外にも、ルータなどさまざまな機器がネットワークに接続されるようになった。管理者にとってシステムをどのように管理するかは重要な課題であり、常にシステム全体の状況を把握する必要がある。そのため、システムを監視し、障害発生にすぐに対処できるようにすることが重要となる。
システム管理の主なポイントは次のようにまとめることができる。
●機器の稼働状況監視
機器が正常に動作していることを定期的に監視する。ICMP(ping)やTCPによるポーリングや、SNMPによるトラップ(イベント)などで監視対象機器の死活を監視したり、HTTPやSMTP/POP3などのサービスの稼働を監視する場合もある。また、サービスの稼働監視には、不正アクセスによるWebページの改ざんなどのチェックが含まれることもある
●システムリソース監視
ネットワーク・トラフィックやCPU、HDDといったサーバのシステムリソースを監視する。ネットワーク・トラフィックに関しては、パケットの流量やスループットを定期的に計測する方法などが考えられる。また、著しくパフォーマンスが低下したりしている場合には、その原因を特定して対処する必要がある
●システムの安全性の確保
ファイアウォールの導入など、さまざまな方法が考えられる。ファイアウォールを導入した場合、そこにも監視が必要である。しかし、ファイアウォールの設計や具体的な実装に関しては、システム管理とは若干趣旨が異なるので、Security&Trustフォーラムなどでより詳細な記事を参照していただきたい
フリーの監視ツール 「MRTG」 「NetSaint」
●MRTG(Multi Router Traffic Grapher)
MRTGは、SNMPを使ってネットワークの稼働状況を監視するツールである。トラフィック以外にも、2系列のデータを集計して短期/中期/長期のトレンドグラフをHTMLページ(GIFイメージのグラフを含む)として作成するため、ネットワークの負荷を確認し、経過を監視することが可能になる。また、独自にSNMP機能を実装しているため、別途SNMPパッケージを用意する必要がない。MRTGはGNU General Public Licenseの下、無償で配布されている。
NetSaintは、ICMP/TCPベースでのリモート管理を基本とした管理ツールである。基本的な操作はWebブラウザ上から可能で、設定の変更や、情報の閲覧などもすべてWebブラウザ・ベースとなる。また、システムの障害を検知すると、メールやページャーなどに通知する機能を実装しているため、システム管理者が少人数の場合には非常に役に立つ。プラグインを利用することで、Web上でのログファイル閲覧など、さまざまな機能拡張ができるのも特徴の1つだ。
監視に使用するコマンドとプロトコル
システム管理によく使用するコマンドには、次のようなものが挙げられる。基本的にUNIXのコマンドだが、Windows系のプラットフォームでも使用できることが多い。ただし、UNIXとWindowsでは動作が異なったり、微妙にコマンド名が違ったりするので注意してほしい。
| コマンド | 用途 |
|---|---|
| arp | ARP(アドレス解決プロトコル)でテーブルを表示または修正する |
| ifconfig | IPの構成を表示または修正する。Windows系プラットフォームでは「ipconfig」というコマンド名 |
| hostname | 現在使用しているコンピュータのホスト名を表示/修正する |
| route | ルーティングテーブルを表示/修正する |
| ping | ICMPプロトコルによってホスト(またはゲートウェイ)からの返答を要求することで、疎通を確認する |
| traceroute | 送信パケットのTTL値を小さく設定し、途中経路から返信される「ICMP time exceeded」を使うことで、パケットの経路と大まかな所要時間を確認する。Windows系プラットフォームでは「tracert」というコマンド名 |
| netstat | 現在のネットワーク接続の情報を確認する。プロトコルの統計情報も表示できる |
| nslookup | IPアドレスまたはFQDNを引数として、DNSへの問い合わせを実行する |
| 表1 システム管理によく使用するコマンド一覧 | |
監視に使用する主なプロトコルには、次のようなものが挙げられる。もし、監視サーバと監視対象機器との間にルータやファイアウォールなどが設置されており、アクセス制御を行っている場合には、これらのプロトコルに対して双方向のアクセス許可を設定する必要がある。
| プロトコル | 用途 |
|---|---|
| ICMP | 疎通を監視するpingコマンドや、tracerouteなどで使用する |
| UDP | DNSやtraceroute(Linuxなどでは、デフォルトでICMPではなくUDPを使用)などで使用する |
| TCP | 特定のサービスポート監視に使用するほか、多くのTCPベースのプロトコルで使用する |
| HTTP/FTPなど | HTTPによるWeb、FTP、SMTP/POP3などのサービスが稼働しているかを、実際に利用することで確認する場合、各サービスで使用しているプロトコルにアクセス許可を設定する |
| SNMP | システム管理に使用する標準プロトコル。ベンダにかかわらず多くの機器を監視することができる。監視サーバ側でSNMPデーモンを実行するか、監視対象機器にSNMPエージェントをインストールして特定の条件でSNMPトラップを通知させることで監視する |
| その他 | 使用する監視ツールによっては、上記以外にもさまざまなプロトコルを使用することがある |
| 表2 監視に使用する主なプロトコルの例 | |
管理のポリシー
また、システム管理には、あらかじめ次のような管理ポリシーを策定しておく必要がある。
- 管理対象機器
- 具体的な管理範囲
- 担当者(あるいは責任者)
- 通常時管理手順
- 障害発生時管理手順
- 管理報告書など情報の共有方法
これらのポリシーをはっきりさせておくことで、効率よく安全にネットワークを監視することができる。また、複数のシステム管理者がいる場合には、これらの情報を共有する仕組みを確立しておくことも重要である。管理ポリシーの策定には、「何を監視したいのか」「知りたい情報は何か」「障害が発生したらどうしたらいいのか」などを検討する必要がある。管理ポリシーがあいまいなままでシステムを監視すると、本来の監視目的との間にズレが生じたり、障害の切り分けができなかったりすることがある。特にシステム障害発生時に、その障害の切り分けが遅れると、適切な対処ができないために復旧が大幅に遅れる原因になる。
それぞれの管理ポリシーは、監視対象や監視目的によって大きく異なるため、具体的な管理ポリシーの策定については次回以降に解説する。
システム管理のスペシャリスト「MSP」
24時間365日の稼働を理想としているからといって、何も自社のスタッフが交代で24時間監視し続ける必要はない。この部分を専門の業者に任せるという道もある。それが、企業のシステムを専門的にマネジメントするMSP(Management Service Provider)の存在だ。筆者の所属するネットベインも、そのMSPの1つである。
顧客にはコンテンツプロバイダなどのeビジネスを展開する企業も多く、サービスの停止は致命的な損害を招く可能性もある。MSPはシステム管理専用の監視ツールと、専門知識を持つオペレータによって顧客ネットワークシステムを24時間365日、常に監視し、システムのトラブルを検知してその旨を通知する。また、障害発生記録やネットワーク・トラフィックの記録などを基に、顧客ネットワークシステムのコンサルティングなどを行うこともある。
ネットベインの監視サービスのメニューの中から、代表的なものをいくつか挙げてみよう。
| サービス名 | サービス内容 |
|---|---|
| ping監視 | 監視対象ノードに対して定期的にpingコマンドを実行し、監視対象となる機器の死活を監視する |
| ポート監視 | 監視対象となる機器のTCPポート(ポート番号は顧客指定)に対して定期的にconnection establishできるかを監視する。特定のサービスポートに接続を確立させ、監視対象となる機器上で実際にサービスが稼働していることを確認する |
| サービス 稼働監視 |
HTTP、FTP、SMTP/POP3、NNTP、DNS、RADIUS、Oracleなどの各サービスが正常に稼働していることを“実際にそのサービスを利用して”確認する |
| リソース監視 | CPU使用率、メモリ使用率、ディスク使用率を監視する。あらかじめ正常値の範囲を規定しておくことで、正常値を超えた場合に通知する |
| ネットワーク ・トラフィック 監視 |
監視対象機器の持つネットワークインターフェイスごとのパケット流量、エラーパケット、破棄パケットなどを監視する。あらかじめ正常値の範囲を規定しておくことで、正常値を超えた場合に通知する。トレンドデータを蓄積して、定期的にデータをグラフなどでチェックすることもできる |
| ログ監視 | 常にシステムログを監視して、事前に指定した内容のログが記録されると通知する |
| SNMPトラップ の監視 |
監視対象機器から発生するSNMPトラップを監視する。監視対象となるSNMPトラップは事前に設定しておく |
| 表3 監視サービスメニューの例 | |
今回はネットワークシステムの管理についての概要を解説した。次回からはシステム管理について、具体的な例を挙げて解説していく。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。