ژ~‚ك‚ç‚ê‚ب‚¢ƒfپ[ƒ^ƒxپ[ƒX‚جچ‚‰آ—pگ«‚ئچذٹQ‘خچôپFDB2ƒ}ƒCƒXƒ^پ[—{گ¬چuچہپi5پjپi2/2 ƒyپ[ƒWپj
ƒ_ƒEƒ“ƒ^ƒCƒ€‚ھ‹–‚³‚ê‚ب‚¢ƒVƒXƒeƒ€‚ة‚¨‚¯‚é‰آ—pگ«‚جٹm•غ‚حپAچإڈd—v‰غ‘è‚إ‚ ‚éپBƒXƒgƒŒپ[ƒW‚âHAƒNƒ‰ƒXƒ^‚ج“±“ü‚ھ•K—v‚ة‚ب‚邾‚낤پBپi•زڈW‹اپj
HAƒNƒ‰ƒXƒ^ƒ\ƒtƒgƒEƒFƒA‚ًژg‚ء‚½چ‚‰آ—pگ«
پ@HAƒNƒ‰ƒXƒ^ƒ\ƒtƒgƒEƒFƒA‚ئ‘g‚فچ‡‚ي‚¹‚½ƒچپ[ƒJƒ‹پEƒtƒFƒCƒ‹ƒIپ[ƒoپ[‚ًژg‚ء‚½چ‚‰آ—pگ«‚جژہŒ»‚ة‚آ‚¢‚ؤ‰ًگà‚µ‚ـ‚·پB
پ@چ‘“à‚إDB2 V8.1‚ة‘خ‰‚·‚é‘م•\“I‚بHAƒNƒ‰ƒXƒ^ƒ\ƒtƒgƒEƒFƒA‚ئ‚µ‚ؤ‚حپAˆب‰؛‚ج4‚آ‚ھ‹“‚°‚ç‚ê‚ـ‚·پB
ƒIپ[ƒvƒ“ƒ\پ[ƒX
پEheartbeat
پ@http://www.linux-ha.org/
ڈ¤—pگ»•i
پELifeKeeperپiSteelEye Technology Inc.پj
پ@http://www.10art-ni.co.jp/product/lifekeeper/
پEClusterPerfectپAClusterPerfect EXپi“Œژإپj
پ@http://cn.toshiba.co.jp/prod/cluster/
پECLUSTERPROپiNECپj
پ@http://www.ace.comp.nec.co.jp/CLUSTERPRO/
پ@‚¢‚¸‚ê‚àپA2ƒmپ[ƒh‚جƒAƒNƒeƒBƒuپ|ƒXƒ^ƒ“ƒoƒCچ\گ¬‚ة‘خ‰‚µ‚ؤ‚¢‚ـ‚·پB
پ،ƒAƒNƒeƒBƒuپ|ƒXƒ^ƒ“ƒoƒCچ\گ¬‚جHAƒNƒ‰ƒXƒ^
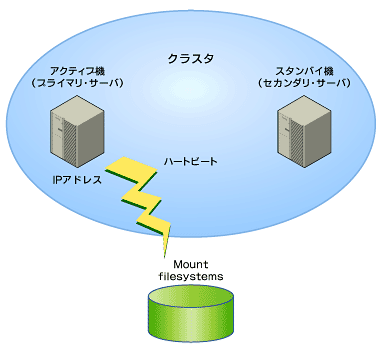
پ@گ}1‚حپA2ƒmپ[ƒhHAƒNƒ‰ƒXƒ^‚جچإڈ¬چ\گ¬‚إ‚·پB2‘ن‚جƒTپ[ƒoپiƒmپ[ƒhپj‚ًژg‚ء‚ؤچ\گ¬‚µ‚ـ‚·پBƒvƒ‰ƒCƒ}ƒٹپEƒTپ[ƒo‘¤‚ھDB2‚جƒTپ[ƒrƒX‚ً’ٌ‹ں‚·‚éƒmپ[ƒh‚إپAƒZƒJƒ“ƒ_ƒٹپEƒTپ[ƒo‘¤‚ھڈلٹQ”گ¶ژ‚ةƒvƒ‰ƒCƒ}ƒٹپEƒTپ[ƒo‚©‚çDB2‚جƒTپ[ƒrƒX‚ًˆّ‚«Œp‚®‚½‚ك‚ة‘ز‹@‚µ‚ؤ‚¢‚éƒmپ[ƒh‚ة‚ب‚è‚ـ‚·پBٹؤژ‹•û–@‚ح‚¢‚‚آ‚©‚ ‚è‚ـ‚·‚ھپA’تڈي‚حƒnپ[ƒgƒrپ[ƒgپiheartbeatپj‚ئŒؤ‚خ‚ê‚éƒpƒPƒbƒg‚ًژg‚ء‚ؤ‘ٹژè‚جƒmپ[ƒh‚جگ¶‘¶‚ًٹm”F‚·‚é‚ج‚ھˆê”ت“I‚إ‚·پB‚ـ‚½پAƒIƒvƒVƒ‡ƒ“‚ئ‚µ‚ؤDB2‚جƒvƒچƒZƒX‚ًٹؤژ‹‚µ‚½‚èپAƒeپ[ƒuƒ‹ƒXƒyپ[ƒX‚ض‚جƒAƒNƒZƒX‚ًٹؤژ‹‚·‚é‚à‚ج‚à‚ ‚è‚ـ‚·پB
پ@ˆّ‚«Œp‚¬‘خڈغ‚جƒٹƒ\پ[ƒX‚حپAˆب‰؛‚ج3‚آ‚إ‚·پB
- ƒXƒgƒŒپ[ƒW
پ@DB2‚جƒٹƒ\پ[ƒX‚حپAƒvƒ‰ƒCƒ}ƒٹ‚ئƒZƒJƒ“ƒ_ƒٹ‚ج2‘ن‚ھ‹¤—L‚µ‚ؤ‚¢‚éƒXƒgƒŒپ[ƒWڈم‚ة’u‚«‚ـ‚·پBƒfپ[ƒ^ƒxپ[ƒXپEƒfƒBƒŒƒNƒgƒٹپAƒeپ[ƒuƒ‹ƒXƒyپ[ƒXپEƒRƒ“ƒeƒiپ[پAƒچƒOپEƒtƒ@ƒCƒ‹‚ح•Kگ{‚إ‚·پBƒCƒ“ƒXƒ^ƒ“ƒXپEƒzپ[ƒ€‚à’تڈي‚حˆّ‚«Œp‚¬‚ج‘خڈغƒٹƒ\پ[ƒX‚ئ‚µ‚ؤˆµ‚¢‚ـ‚·پB‚½‚¾‚µپAچ‚‘¬‚بˆّ‚«Œp‚¬‚ًچs‚¤ڈêچ‡‚ب‚ا‚حپAڈ‚µ‚إ‚àˆّ‚«Œp‚¬ƒٹƒ\پ[ƒX‚ًŒ¸‚ç‚·‚½‚ك‚ةƒCƒ“ƒXƒ^ƒ“ƒXپEƒzپ[ƒ€‚ً‹¤—L‚µ‚ب‚¢ڈêچ‡‚à‚ ‚è‚ـ‚·پB
پ@ƒfپ[ƒ^ƒxپ[ƒXپEƒ}ƒlپ[ƒWƒƒپ[چ\گ¬ƒpƒ‰ƒپپ[ƒ^پ[‚حˆّ‚«Œp‚ھ‚ê‚ب‚¢‚ج‚إپAƒfپ[ƒ^ƒxپ[ƒXپEƒ}ƒlپ[ƒWƒƒپ[چ\گ¬ƒpƒ‰ƒپپ[ƒ^پ[‚ً•دچX‚·‚éڈêچ‡‚ح—¼ƒmپ[ƒh‚إ•دچX‚·‚é•K—v‚ھ‚ ‚è‚ـ‚·پB - IPƒAƒhƒŒƒX
پ@WebƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“ƒTپ[ƒo‚ب‚ا‚جƒNƒ‰ƒCƒAƒ“ƒg‚©‚çDB2‚ةƒAƒNƒZƒX‚·‚邽‚كپA‰¼‘zIPƒAƒhƒŒƒXپiƒTپ[ƒrƒXIPƒAƒhƒŒƒX‚ئ‚àŒؤ‚شپj‚ًگف’肵‚ـ‚·پBژہچغ‚ة‚حIPƒGƒCƒٹƒAƒXپiLinux‚إ‚حeth0:1‚ب‚اپj‚ًژg‚¢‚ـ‚·‚ھپAƒTپ[ƒo‚ھƒ_ƒEƒ“‚µ‚ؤ‚àIPƒGƒCƒٹƒAƒX‚ًژg‚¤‚±‚ئ‚إپAƒNƒ‰ƒCƒAƒ“ƒg‚©‚ç‚جگع‘±‚ة‰e‹؟‚ھڈo‚ب‚¢‚و‚¤‚ة‚µ‚ـ‚·پB - DB2ƒTپ[ƒrƒX
پ@DB2‚جƒTپ[ƒrƒX‚àˆّ‚«Œp‚¬‚ـ‚·پBƒfƒtƒHƒ‹ƒg‚إ‚حژ©“®چؤژn“®پiautorestartپjƒfپ[ƒ^ƒxپ[ƒXچ\گ¬ƒpƒ‰ƒپپ[ƒ^پ[‚ھON‚ة‚ب‚ء‚ؤ‚¢‚é‚ج‚إپAƒNƒ‰ƒbƒVƒ…پEƒٹƒJƒoƒٹپ[‚ھچs‚ي‚ê‚ـ‚·پB
پ،ƒچپ[ƒJƒ‹پEƒtƒFƒCƒ‹ƒIپ[ƒoپ[‚ج—¬‚ê
پ@ڈلٹQ‚ھ”گ¶‚µ‚½چغ‚جˆّ‚«Œp‚¬ڈˆ—‚ة‚آ‚¢‚ؤŒ©‚ؤ‚¢‚«‚ـ‚µ‚ه‚¤پBƒTپ[ƒo‚جڈلٹQپiƒJپ[ƒlƒ‹‚ھƒnƒ“ƒOƒAƒbƒv‚µ‚½پj‚ئ‰¼’肵‚ؤکb‚ًگi‚ك‚ـ‚·پB
- ڈلٹQŒں’m
پ@ƒvƒ‰ƒCƒ}ƒٹپEƒTپ[ƒo‚ھ‰“ڑ‚µ‚ب‚‚ب‚é‚ئheartbeat‚ھ“rگط‚êپAڈلٹQ‚ج”گ¶‚ھŒں’m‚³‚ê‚ـ‚·پB - ƒٹƒ\پ[ƒX‚جˆّ‚«Œp‚¬
پ@ƒNƒ‰ƒXƒ^ƒ\ƒtƒgƒEƒFƒA‚حƒNƒ‰ƒXƒ^‚ًچؤچ\گ¬‚µپAƒXƒgƒŒپ[ƒWپAIPƒAƒhƒŒƒXپADB2‚جƒvƒچƒZƒX‚جڈ‡‚ةˆّ‚«Œp‚¬‚ًچs‚¢‚ـ‚·پB
- ƒXƒgƒŒپ[ƒW
پ@ƒtƒ@ƒCƒ‹ƒVƒXƒeƒ€‚جƒ}ƒEƒ“ƒg‚ًچs‚¢‚ـ‚· - IPƒAƒhƒŒƒX‚جˆّ‚«Œp‚¬
پ@ƒTپ[ƒrƒX—p‚جIPƒAƒhƒŒƒXپiژہچغ‚ة‚حIPƒGƒCƒٹƒAƒXپj‚جˆّ‚«Œp‚¬ - DB2‚جٹJژn
پ@ƒZƒJƒ“ƒ_ƒٹپEƒTپ[ƒo‚إDB2‚ًٹJژn‚µ‚ـ‚·
- ƒXƒgƒŒپ[ƒW
- DB2‚جƒNƒ‰ƒbƒVƒ…پEƒٹƒJƒoƒٹپ[
پ@ƒNƒ‰ƒbƒVƒ…پEƒٹƒJƒoƒٹپ[‚ًچs‚ء‚ؤچإŒم‚ةƒRƒ~ƒbƒg‚³‚ꂽƒgƒ‰ƒ“ƒUƒNƒVƒ‡ƒ“‚ـ‚إ–ك‚µپAƒfپ[ƒ^ƒxپ[ƒX‚جگ®چ‡گ«‚ً•غ‚؟‚ـ‚·پB
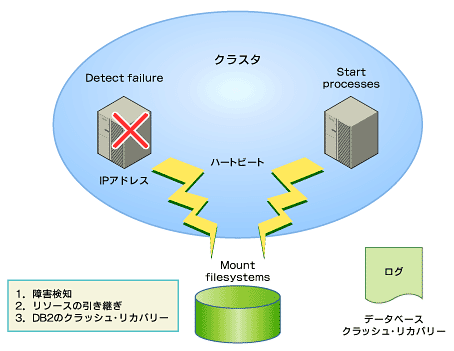
پ@ˆبڈم‚ھپAHAƒNƒ‰ƒXƒ^ƒ\ƒtƒgƒEƒFƒA‚ًژg‚ء‚½ƒچپ[ƒJƒ‹پEƒtƒFƒCƒ‹ƒIپ[ƒoپ[‚جٹT—v‚إ‚·پB
پ،Œv‰و’âژ~‚ئƒ_ƒEƒ“ƒ^ƒCƒ€‚ج’Zڈk
پ@‚±‚±‚ـ‚إ‚ح—\‘zٹO‚ج”ٌŒv‰و’âژ~‚ً‘O’ٌ‚ة‰ًگà‚µ‚ـ‚µ‚½‚ھپAژہ‚حŒv‰و’âژ~‚ة‚و‚éƒVƒXƒeƒ€’âژ~‚à–³ژ‹‚إ‚«‚ـ‚¹‚ٌپB—ل‚¦‚خپAOS‚جƒpƒbƒ`‚âDB2‚جFixPak‚ً“K—p‚·‚éچغ‚حپADB2‚جƒTپ[ƒrƒX‚ًژ~‚ك‚é•K—v‚ھ‚ ‚é‚ج‚إ•K‘R“I‚ةƒVƒXƒeƒ€‚ھ’âژ~‚µ‚ـ‚·پB
پ@Œv‰و’âژ~‚جچغ‚àپA‘Oڈq‚جHAƒNƒ‰ƒXƒ^‚ًژg‚ء‚ؤ’âژ~ژٹش‚ً‹ة—ح’Z‚‚·‚邱‚ئ‚ھ‚إ‚«‚ـ‚·پB‚ـ‚½پADB2‚جچإگV”إ‚حƒIƒ“ƒ‰ƒCƒ“پEƒ†پ[ƒeƒBƒٹƒeƒB‚ھڈ[ژہ‚µ‚ؤ‚¢‚é‚ج‚إپAƒfپ[ƒ^ƒxپ[ƒX‚ًژ~‚ك‚邱‚ئ‚ب‚ƒپƒ“ƒeƒiƒ“ƒX‚ًچs‚¤‚±‚ئ‚ھ‰آ”\‚إ‚·پB
DB2‚جƒIƒ“ƒ‰ƒCƒ“پEƒ†پ[ƒeƒBƒٹƒeƒB
پ@پ@ƒIƒ“ƒ‰ƒCƒ“چ\گ¬ƒpƒ‰ƒپپ[ƒ^پ[•دچX
پ@پ@ƒIƒ“ƒ‰ƒCƒ“•\پEچُˆّچؤ•زگ¬
پ@پ@ƒIƒ“ƒ‰ƒCƒ“پEƒچپ[ƒhƒ†پ[ƒeƒBƒٹƒeƒB
پ@پ@ƒIƒ“ƒ‰ƒCƒ“پEƒRƒ“ƒeƒiپEƒXƒgƒŒپ[ƒWٹا—
پ@پ@ƒIƒ“ƒ‰ƒCƒ“ƒoƒbƒNƒAƒbƒv
پ@پ@ƒIƒ“ƒ‰ƒCƒ“پE•\ƒXƒyپ[ƒXƒٹƒXƒgƒA
ƒfƒBƒUƒXƒ^پEƒٹƒJƒoƒٹ
پ@ƒfƒBƒUƒXƒ^پEƒٹƒJƒoƒٹپiچذٹQ‘خچôپj‚حپAٹî–{“I‚ةƒچپ[ƒJƒ‹پEƒtƒFƒCƒ‹ƒIپ[ƒoپ[‚ئ“¯‚¶‚و‚¤‚ةچl‚¦‚邱‚ئ‚ھ‚إ‚«‚ـ‚·پB‚µ‚©‚µپAƒfƒBƒUƒXƒ^پEƒٹƒJƒoƒٹ‚جڈêچ‡‚ح‹——£‚ھ—£‚ê‚ؤ‚¢‚éڈêڈٹ‚ةƒoƒbƒNƒAƒbƒvپEƒTƒCƒg‚ًگف’u‚·‚é•K—v‚ھ‚ ‚é‚ج‚إپAƒچپ[ƒJƒ‹پEƒtƒFƒCƒ‹ƒIپ[ƒoپ[‚ج‚و‚¤‚ةƒXƒgƒŒپ[ƒW‚جˆّ‚«Œp‚¬‚إƒfپ[ƒ^‚ًˆع“®‚·‚邱‚ئ‚ھ“‚‚ب‚è‚ـ‚·پB
پ@‚»‚±‚إپAƒfپ[ƒ^‚جˆع“®‚ًچs‚¤‚½‚ك‚ةƒXƒgƒŒپ[ƒW‚ج‰“ٹuƒRƒsپ[‹@”\‚ً—ک—p‚·‚é—ل‚ھ‘‚¦‚ؤ‚«‚ؤ‚¢‚ـ‚·پBIBM ESS‚جPPRC‚â“ْ—§SANRISE‚جTrueCopyپAEMC Symmetrix‚جSRDF‚ب‚ا‚ھ‚»‚ê‚ة“–‚½‚è‚ـ‚·پB‚±‚±‚إ’چˆس‚ھ•K—v‚ب‚ج‚حپA‰“ٹuƒRƒsپ[‚جڈêچ‡‚ح”ٌ“¯ٹْ‚إƒRƒsپ[‚·‚éƒ^ƒCƒv‚جƒXƒgƒŒپ[ƒW‚à‚ ‚è‚ـ‚·‚ھپAƒfƒBƒXƒN‚ض‚جڈ‘‚«چ‚فڈ‡ڈک‚ھ•غڈط‚³‚ê‚ب‚¢‚à‚ج‚à‚ ‚é‚ئ‚¢‚¤‚±‚ئ‚إ‚·پB‚±‚جڈêچ‡پAƒچپ[ƒJƒ‹ƒRƒsپ[“¯—l‚ةI/O‚جگأژ~“_‚ًژو‚é•K—v‚ھ‚ ‚èپA—vŒڈ‚ة‰‚¶‚ؤƒXƒiƒbƒvƒVƒ‡ƒbƒgپEƒfپ[ƒ^ƒxپ[ƒX‚©ƒXƒ^ƒ“ƒoƒCپEƒfپ[ƒ^ƒxپ[ƒX‚ً‘I‘ً‚µ‚ـ‚·پBٹ®‘S‚ة“¯ٹْ‚إƒRƒsپ[‚·‚éڈêچ‡‚حپADB2‚جƒNƒ‰ƒbƒVƒ…پEƒٹƒJƒoƒٹپ[‹@”\‚¾‚¯‚إƒٹƒJƒoƒٹ‰آ”\‚إ‚·پB
پ@‚ب‚¨پALinux‚ة‚ح‰“ٹu’n“¯ژm‚جƒtƒFƒCƒ‹ƒIپ[ƒoپ[‚ة‘خ‰‚µ‚½ƒNƒ‰ƒXƒ^ƒ\ƒtƒgƒEƒFƒA‚ھ‚ب‚¢‚½‚كپAˆّ‚«Œp‚¬‚ة‚حگl‚جژè‚ھ•K—v‚ة‚ب‚è‚ـ‚·پB
پ@چ،‰ٌ‚حپADB2‚جچ‚‰آ—pگ«‚ئƒfƒBƒUƒXƒ^پEƒٹƒJƒoƒٹ‚ة‚آ‚¢‚ؤ‰ًگà‚µ‚ـ‚µ‚½پBƒXƒgƒŒپ[ƒW‚جƒRƒsپ[‹@”\‚âHAƒNƒ‰ƒXƒ^ƒ\ƒtƒgƒEƒFƒA‚ب‚ا‚حپALinux‚إƒIپ[ƒvƒ“ƒ\پ[ƒX‚ةٹµ‚êگe‚µ‚ٌ‚¾ٹF‚³‚ٌ‚ة‚ح‚ب‚¶‚ف‚ج‚ب‚¢‚à‚ج‚¾‚ء‚½‚©‚à‚µ‚ê‚ـ‚¹‚ٌپB‹@‰ï‚ھ‚ ‚ê‚خheartbeat‚ًژg‚ء‚½DB2ƒNƒ‰ƒXƒ^‚ة‚آ‚¢‚ؤ‚àگG‚ꂽ‚¢‚ئژv‚¢‚ـ‚·پB
پ@ژں‰ٌ‚حپAƒfپ[ƒ^ƒxپ[ƒX‚ج‰^—pٹا—‚ًƒeپ[ƒ}‚ة‰ًگà‚·‚é—\’è‚إ‚·پB
Copyright © ITmedia, Inc. All Rights Reserved.
ٹضکA‹Lژ–
- کAچعپF‰ُ‘¬MySQL‚إƒfپ[ƒ^ƒxپ[ƒXƒAƒvƒٹپIپi‘S11‰ٌپj
Œy‰ُ‚ب“®چى‚إ’m‚ç‚ê‚éRDBMSپAMySQL‚إDBƒAƒvƒٹ‚جچ\’z‚ًچs‚¤پBMySQL‚جƒCƒ“ƒXƒgپ[ƒ‹‚ةژn‚ـ‚èپAPerl‚âRuby‚ب‚ا‚جƒXƒNƒٹƒvƒg‚إƒfپ[ƒ^ƒxپ[ƒX‚ً‘€چى‚·‚é•û–@‚ـ‚إ‚ًٹ®‘S‰ًگà - کAچعپFچ،‚©‚çژn‚ك‚é MySQL“ü–هپiکAچع’†پj
’è”ش‚جLAMPپiLinuxپ{Apacheپ{MySQLپ{PHPپjچ\گ¬‚إWebƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“ٹJ”‚ة’§گيپIƒTƒ“ƒvƒ‹ƒAƒvƒٹ‚جچ\’z‚ًگi‚ك‚ب‚ھ‚çپAٹî‘b’mژ¯‚â‘€چى•û–@‚ة‚آ‚¢‚ؤڈع‚µ‚‰ًگà‚·‚é - کAچعپFOracleƒ}ƒCƒXƒ^پ[—{گ¬چuچہپi‘S6‰ٌپj
–{کAچع‚إ‚حپAOracle‚جٹا—پEƒ`ƒ…پ[ƒjƒ“ƒO•û–@‚ًڈذ‰î‚µ‚ؤ‚¢‚پB‚±‚ê‚©‚çOracle‚ًژn‚ك‚éگlپA‚»‚µ‚ؤOracle‚ً‚و‚èگ[‚—‰ً‚µ‚½‚¢گl‚ج‚½‚ك‚جپAˆê•à“¥‚فچ‚ٌ‚¾ژہ—pچuچہ - کAچعپFDB2ƒ}ƒCƒXƒ^پ[—{گ¬چuچہپi‘S7‰ٌپj
–{کAچع‚إ‚حپADB2 UDB‚جژہ‘H“I‚ب‰^—pپEٹا—•û–@‚ًڈذ‰î‚µ‚ؤ‚¢‚پBDB2‚ً—ک—p‚·‚邤‚¦‚إ•K—v‚ب’mژ¯‚ًپAژہ‰^—p‚ً‘O’ٌ‚ةDB2‚جƒvƒچ‚ھ‰ًگà - “ءڈWپFƒGƒ“ƒ^پ[ƒvƒ‰ƒCƒYژsڈê‚ةŒü‚©‚¤MySQL 5.0پm‘O•زپn MySQL 5.0‚جگV‹@”\‚ًƒAƒ‹ƒtƒ@”إ‚إƒ`ƒFƒbƒN
1Œژ‚ةŒِٹJ‚³‚ꂽ5.0ƒAƒ‹ƒtƒ@”إ‚ح‘ه•‚ةٹg’£‚³‚ê‚ؤ‚¨‚èپAƒGƒ“ƒ^پ[ƒvƒ‰ƒCƒYژsڈê‚ض‚جگiڈo‚ً—\ٹ´‚³‚¹‚é - “ءڈWپFLinux‚إ“®‚ƒٹƒŒپ[ƒVƒ‡ƒiƒ‹ƒfپ[ƒ^ƒxپ[ƒXپEƒJƒ^ƒچƒO
ƒfپ[ƒ^ƒxپ[ƒXƒTپ[ƒo‚جOS‚ئ‚µ‚ؤLinux‚ًچج—p‚·‚éƒPپ[ƒX‚ھ‘‚¦‚ؤ‚¢‚éپBLinux‚إ“®چى‚·‚é7‚آ‚جژه‚بƒٹƒŒپ[ƒVƒ‡ƒiƒ‹ƒfپ[ƒ^ƒxپ[ƒX‚ًڈذ‰î‚·‚éپBگ»•i“±“ü‚جچغ‚جژQچl‚ة‚µ‚ؤ‚ظ‚µ‚¢ - ƒfپ[ƒ^ƒxپ[ƒXٹضکA‹Lژ–ˆê——