索引を作成したのにパフォーマンスが悪いケース:Oracle SQLチューニング講座(7)(2/3 ページ)
本連載では、Oracleデータベースのパフォーマンス・チューニングの中から、特にSQLのチューニングに注目して、実践レベルの手法を解説する。読者はOracleデータベースのアーキテクチャを理解し、運用管理の実務経験を積んでいることが望ましい。対象とするバージョンは現状で広く使われているOracle9iの機能を基本とするが、Oracle 10gで有効な情報も随時紹介していく。(編集局)
使用している索引の問題
多くの場合、索引スキャンによって大きくパフォーマンスを改善することができますが、索引スキャンも万能ではありません。「実行計画を確認すると、索引スキャンを行っているにもかかわらず処理速度が遅い」「全表スキャンよりも処理が遅い」という場合もあり得ます。ここではどのような場合にそのような事態となり得るのか、例を挙げて説明していきます。
索引列のデータの偏り
索引スキャンの方が全表スキャンよりパフォーマンスが悪い、というのはどのような場合かを考えてみましょう。まず、第2回「SQLチューニングの必須知識を総ざらい(前編)」で説明した、レコードへのアクセス方法を思い出してください。
HWM(High Water Mark:最高水位標)までのすべてのレコードを読み込む全表スキャンと、ROWID情報を取得して、そのROWID情報を基に表のレコードを読み込む索引スキャンでは、レコードへのアクセス方法が大きく異なります。そのため、それぞれのメリットを生かせる状況を理解して、適切に使い分ける必要があります。
図4は、検索するレコードの割合によって、索引スキャン、全表スキャンの処理速度がどのように変わっていくかを表した一例です。索引スキャンと全表スキャンの処理速度は、検索レコードの割合が増加するにつれて差が縮まり、ある時点を境に逆転していることが分かります(逆転する時点は、索引列のデータやデータ長によって異なってきます)。
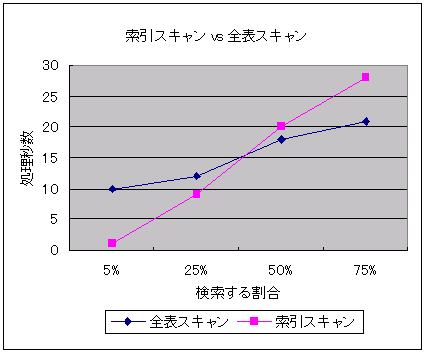
索引を使用しているにもかかわらず、意図したパフォーマンスが得られない場合には、図4のように検索レコードの割合が多過ぎる可能性が考えられます。そのような場合には、DBA_TABLESビューやDBA_TAB_COLUMNSビュー、DBA_HISTOGRAMSビューなどに格納されている統計情報注2から表に格納されているレコード件数や、ある列には何種類のデータが存在しているのかといった情報を確認することができます。もしくは、以下のようにSQLを実行することでもデータの偏りを確認することができます。
注2:統計情報
統計情報は、DBMS_STATSパッケージもしくはANALYZEコマンドで取得します。なお、統計情報を取得した表や索引にアクセスする場合、コストベースオプティマイザが利用されるので注意が必要です。詳細は第5回「SQLチューニングの基盤となる統計情報」を参照してください。

図5の結果から、値が「99999」であるレコードが3件しかないのに対して、値が「EEEEE」であるレコードは5万件と全レコード件数の半分を占めており、「INFO_TXT」列には大きなデータの偏りがあることが分かります。それでは、実際にパフォーマンスにどれだけの違いが出てくるのかを見てみましょう。
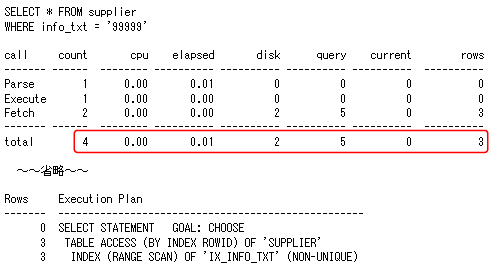
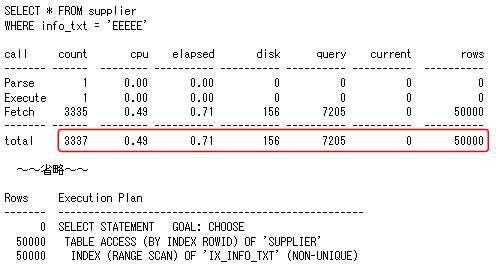
図6、図7の赤線で囲った部分を比較すると、どちらも同じ索引スキャンを行っているにもかかわらず、実行時間、アクセスブロック数に大きな違いが出ていることが確認できます。「INFO_TXT = '99999'」の条件にて検索する場合には、索引スキャンが効率的であることが分かります。

図8は、FULLヒントを使用して全表スキャンを行った場合の実行計画になります。図7と比較すると、「elapsed」が約2分の1、「disk」は約4分の1となっており、検索レコードの割合が多い場合には全表スキャンの方が効率的であることが分かります。これは、全表スキャンがマルチブロック読み込みを行っているのに対して、索引スキャンではシングルブロックアクセスを行っているためです。その結果、索引スキャンでは同じブロックを何度もアクセスすることになるため、アクセスブロック数が増加しています。
このように、条件値により最適な実行計画が異なる場合、データ分布の統計情報を取得(索引列のヒストグラムの取得)し、コストベースのアプローチを行います。その結果、オプティマイザに適切な実行計画を選択させるために情報を提供することができます。例えば、条件に一致する件数が全件数のほとんどを占めるようなSQLでは全表スキャン、条件に一致する件数が少ない場合には索引スキャンといった実行計画をオプティマイザが判断します。
Copyright © ITmedia, Inc. All Rights Reserved.