PostgreSQL 9系の目玉、「レプリケーション機能」を試す:もう一度始めたい人のPostgreSQL(2)(1/2 ページ)
今回からは、PostgreSQL 9系で実装されたさまざまな新機能を実際に操作する手順を紹介していきます。まずは、PostgreSQL 9系の目玉機能、レプリケーション機能を設定し、その動作を確認してみましょう。
前回はPostgreSQL 9系に加わった新機能を簡単に紹介しました。今回からは、それぞれの主要な機能を実際に操作し、動作を確認していきます。
連載2回目では、PostgreSQL 9系の目玉機能であったレプリケーション機能の動作確認を行います。
なお、本連載では各サーバへのPostgreSQLのインストールとデータベースクラスタの初期化については省略します。PostgreSQLのインストール方法については、こちらの記事をご参照ください。取り扱っているPostgreSQLのバージョンは8.3.1と少々古めではありますが、インストール作業の流れに変化はありません。
最新版の入手方法と注意点
執筆時点での最新版は、以下のページからダウンロードできます。
注意点は、PostgreSQLのユーザーを作成するcreateuserコマンドが、対話モードがデフォルトでなくなったということです。上記の記事と同様に、createuserコマンドで対話モードを利用する場合は、--interactiveオプションを付け加えるようにしてください。
[postgres]$ createuser --interactive user1 Shall the new role be a superuser? (y/n) n Shall the new role be allowed to create databases? (y/n) y Shall the new role be allowed to create more new roles? (y/n) n
今回は図1のような、稼働系サーバ1台と待機系サーバ2台を用いた非同期レプリケーションによるクラスタ構成を構築します。稼働系→待機系→待機系と、カスケードレプリケーションを行います。
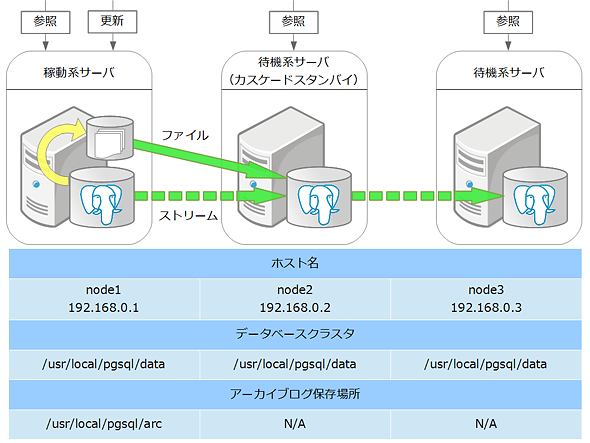
レプリケーションについては、ストリーミングレプリケーションとログシッピングを併用します。これにより、ストリーミングレプリケーションが途絶えたとしても、稼働系のアーカイブログが転送され、より堅牢な構成となります。
ただし、ログシッピングを用いる場合は、アーカイブログの転送経路として別途scpやNFSなどを用意する必要があります。また、本構成では各サーバがデータベースクラスタとアーカイブログの格納領域を持ちます。しかし、アーカイブログが書き込まれるのは稼働系サーバだけである点に注意してください。
稼働系サーバの設定作業
それでは稼働系サーバとなるnode1サーバの設定から進めていきましょう。
レプリケーション専用のDBユーザーである「repli」を作成します。
[postgres@node1 ~]$ createuser -P --replication repli Enter password for new role: # パスワードを入力。今回はrepliとする。 Enter it again: # パスワードを入力。今回はrepliとする。
createuserコマンドに -Pオプションを指定し、ログインパスワードを設定しています。今回は便宜的にユーザー名と同じ「repli」とします。また、--repolicationオプションを指定し、REPLICATTION権限を付与しています。
psqlコマンドでデータベースに接続して、¥(バックスラッシュ)コマンドを実行してみてください。REPLICATION権限のみを持ったユーザー、repliが追加されていることが確認できます。
[postgres@node1 ~]$ psql -d postgres -U postgres
psql (9.2.4)
Type "help" for help.
postgres=# \du
List of roles
Role name | Attributes | Member of
-----------+------------------------------------------------+-----------
postgres | Superuser, Create role, Create DB, Replication | {}
repli | Replication | {}
user1 | Create DB | {}
------------------------------------------------------------------------
続けてpostgresql.confの設定を行います。以下の通りパラメータを修正します。postgresql.confは、データベースクラスタのディレクトリ内に存在します。
| 変更するパラメータ | パラメータの説明 |
|---|---|
| listen_addresses = '*' | 接続を待ちうけるIPアドレス |
| wal_level = hot_standby | トランザクションログレベル |
| archive_mode = on | アーカイブモードの有効化 |
| archive_command = 'cp "%p" "/usr/local/pgsql/arc/%f"' | トランザクションログをアーカイブする際のコマンド |
| max_wal_senders = 3 | 待機系サーバの数 |
| wal_keep_segments = 5 | アーカイブログの最小保持数 |
| hot_standby = on | ホットスタンバイ機能の有効化 |
| logging_collector = on | ログ出力の有効化 |
| log_line_prefix = '%t [%a:%p] ' | ログの各行頭の出力フォーマット |
archive_commandで設定されている%pは、コピー対象となる個々のトランザクションログファイルの絶対パスに置き換えられます。また、%fはファイル名のみに置き換えられます。max_wal_sendersが「待機系サーバ+1」の値になっている理由は、後の手順でレプリケーションプロトコルを使ってベースバックアップを取得する、pg_basebackupコマンドを使うためです。hot_standbyは待機系サーバで設定するパラメータですが、ここで設定してしまいましょう。稼働系サーバはこのパラメータを無視するので問題ありません。
また、レプリケーション構築に直接は関係ありませんが、logging_collectorでPostgreSQLのログが出力されるようにします。log_line_prefixの%tはタイムスタンプ、%aはアプリケーション名、%pはプロセスIDに置き換えられます。ログはサーバプロセスを起動するたびに、データベースクラスタディレクトリ下に"pg_log/postgresql-YYYY-MM-DD_HHMMSS.log"として出力されます。
pg_hba.confの設定を行います。以下のパラメータを追加します。pg_hba.confはデータベースクラスタのディレクトリ内に存在します。
| TYPE | DATABASE | USER | ADDRESS | METHOD |
|---|---|---|---|---|
| host | replication | repli | samenet | md5 |
これにより、レプリケーション専用ユーザーであるrepliで、稼働系サーバのサブネット内の待機系サーバが、稼働系サーバへ接続できるようになります。
以上の設定が完了したら、サーバプロセスを再起動します。
[postgres@node1 ~]$ pg_ctl restart waiting for server to shut down.... done server stopped server starting
Copyright © ITmedia, Inc. All Rights Reserved.