多段階認証、多要素認証から不正アクセス対策を考える:認証強化は誰のため?(3/4 ページ)
利用者本人を特定するために用いられる多要素認証は、ユーザーの利便性を下げる可能性があります。まずは多要素認証の必要条件を知り、利便性と安全性のバランスを取るにはどうすべきかを考えます。
試行回数での検知を行う→特殊な状況でしか有効ではない?
Web Application Firewall(WAF)と呼ばれる機器には、認証の試行回数を「IPアドレスごとに1分間に3回まで」というような制限をかけることができます。ここで、例えばパスワードが「数字4桁」であるサイトを例にとって、試行回数での制限が有効であるか考えてみます。
数字4桁であれば、パターンの総数は1万通りです。1アカウントの認証を突破する時間は最大で55時間強、1万アカウント存在するシステムであればすべてのアカウントの認証を突破するのに最大で60年強かかることになります。1万アカウントすべての認証を突破するには時間がかかりますが、特定のアカウントの認証を突破するには現実的な時間であるため、強固なセキュリティとは言い切れないでしょう。また、これは試行回数を最大1分間に3回という制限をかけているにすぎないため、パスワードリスト型攻撃やソーシャルエンジニアリングで聞き出したIDやパスワードを悪用したアクセスは、1アカウントにつき1回の試行でしかないため、対処することはできません。
そもそも、失敗回数の計測では、不正に入手したIDとパスワードを悪用したアクセスと正規のユーザーからのアクセスを見分けることはできないため、この対策では焼け石に水にしかなりません。
そこで、認証成功から、不正かどうかの判別を行う手法について考えてみます。
ところで、「ログイン後の行動」は?
認証におけるリスクを判断する材料は、
- IDとパスワードといったログインに必要な情報
- Cookieやブラウザー固有の情報といったブラウザーが保有している情報
- アクセスしてきた場所や過去のユーザーの行動といったログイン後の行動情報
などです。1はログイン時にユーザーが入力する必要がありますが、2と3は自動的に取得できるという特徴があります。
これらの情報、特に自動的に取得した情報をベースに、リスクを判断することはできないでしょうか。ログインの成否は1.のみでの判断であるため、検知に限界がありましたが、残りの2.と3.を利用することで不正なアクセスかどうかを判断できます。
「リスクベース認証」でさらに検知精度を上げる
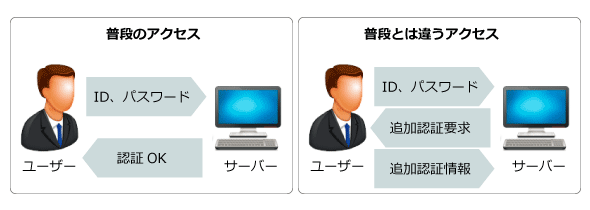
認証に成功するアクセスの中からユーザーの環境変数や行動パターンを分析し、不正かどうかのリスクを判別する手法として「リスクベース認証」があります。これは普段のアクセスからブラウザーの種類やIPアドレスのパターンを読み解き、普段とは違ったアクセスを見つけ出す付加認証の一種です。
リスクベース認証は、普段は通常のパスワード認証だけなので、ユーザーへの負担が小さいというメリットがあります(図2)。実際に「Yahoo!」や「Facebook」をはじめ、大手銀行(三菱東京UFJ銀行、みずほ銀行、りそな銀行、ゆうちょ銀行)でも導入されています。
リスクベース認証、Yahoo! での例
Yahoo! に実装されているリスクベース認証では、不審なアクセスを検知しても付加認証を実施せず、メールでユーザーへ通知する対策が取られています。これは、不正アクセスを検知して対応できるようにするための施策といえます。
さらにリスクベース認証とは別に、Yahoo! の場合は最終ログイン時刻や過去のログイン履歴を表示しています。これまでならばシステム管理者しか気付くことのできなかった不正アクセスを、ユーザー自身で気付くことができる仕組みです。
リスクベース認証、Facebookでの例
Facebookに実装されているリスクベース認証では、不審なアクセスを検知したらマトリクス認証と「友達当てクイズ」を用いて認証を実施しています。「友達当てクイズ」とは、友達登録されている人の写真がランダムに表示され、表示された友達が誰であるのかをクリックで選択するものです
「友達当てクイズ」はSNSならではの方式だといえますが、本人にも判断がつかない場合があります。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 いま、高まるアイデンティティ管理の重要性
いま、高まるアイデンティティ管理の重要性
加速するクラウドの普及と相まって、増加し続けるIDとパスワード。アイデンティティ情報に関わる運用コストの増加や不正アクセスなどの問題は、多くの企業にとって悩みの種となっています。導入費用を抑えてこれらの問題を対策するためには、OSSによるアイデンティティ管理システムの導入が有効です。 不正ログインを食い止めろ! OpenAMで認証強化
不正ログインを食い止めろ! OpenAMで認証強化
多発するパスワードリスト攻撃による不正ログインに対しては、リスクベース認証やワンタイムパスワード認証を含む多要素認証が効果的です。今回はオープンソースのアクセス管理ソフトウェアであるOpenAMの概要と、OpenAMが提供するリスクベース認証(アダプティブリスク認証、デバイスプリント認証)、ワンタイムパスワード認証(OATH/YubiKey認証)について解説します。 OpenIG、OpenDJと連携したOpenAMの新機能
OpenIG、OpenDJと連携したOpenAMの新機能
今回は、OpenAMの姉妹製品で既存アプリケーションを改修せずにシングルサインオンを可能にする「OpenIG」と、OpenAMのデフォルトデータストアである「OpenDJ」について解説します。 面倒だけど避けては通れない、いまこそ考える「パスワード使い回し対策」
面倒だけど避けては通れない、いまこそ考える「パスワード使い回し対策」
パスワードはなぜ使い回されるのか。IPAとJPCERT/CCはパスワード使い回しの現状を解説し、利用者とサービス事業者に向け、新たなキャンペーンを開始する。