Cephがスケールできる理由、単一障害点を排除する仕組み、負荷を減らす実装:Ceph/RADOS入門(4)(2/4 ページ)
Ceph/RADOS が採用しているCRUSH、Paxosといった、分散したデータから正しく応答するための仕組みを支えるアルゴリズムの概要を学びながら、挙動を見ていきます。
Paxosインスタンスによるクラスターマップの合意形成(Paxos合意アルゴリズム)
クライアントがmonitorからクラスターマップを取得することは分かりましたが、複数のクラスターマップの内容がクラスター内で差異を生じないようにする必要があります。このため、Ceph/RADOSではクラスターマップの変更に「Paxos」という合意アルゴリズムを使用して管理します。
Ceph/RADOSのmonitorのような状態を持つソフトウェアの冗長化では、命令の順序が変わるとレプリカの状態が異なってしまいます。そこで、常にi番目の命令として何を採用するかについて、冗長化したmonitor間で合意を取る必要があります。Ceph/RADOSでは、1つの値に対して合意を取る一連の処理をPaxosインスタンスと呼びます。
ここでは詳細を省きますが、Leslie Lamport氏の論文「Paxos made simple」*から、処理内容を要約すると、次のようになります。
* Leslie Lamport「Paxos made simple」,01 Nov 2001.(リンクはPDFデータ)
「Paxos made simple」(Leslie Lamport, 01 Nov 2001)の要約
- PaxosはLeslie Lamport氏が考案したConsensus(合意)アルゴリズム
- 「状態」を持つソフトウェアの冗長化において、命令の順序が変わるとレプリカの状態が異なってしまうので、i番目の命令として何を採用するかに対して合意を取る必要がある
- インスタンス=「1つの値」に対して合意を取る一連の処理
- プロセス=合意を取るメンバー
プロセスの役割分担:- Proposer:値を提案する
- Accepter:値を受理する
- Learner :値の合意が取れたことを確認する
- 提案ID=値vが提案された順番nのこと
- ルール
- P1a:Accepterはnより大きなPrepareリクエストを受理していないとき、またはそのときに限りIDがnの提案を受理できる
- P2c:Proposerから値vを持つID=nの提案が出た場合、次のようなAccepterの集合Sが存在しなければならない
- 集合Sには過半数のAccepterが含まれる
- 集合Sに含まれるどのAccepterもまだIDがn未満の提案を受理していない
- 集合Sに含まれるAccepterが受理したIDがn未満の提案のうち、一番大きなID=mを持つ提案の値はvである
- フェイズ1
- Prepare(n)メッセージ=今後、IDがn未満のメッセージをAccepterに無視してもらうためにProposerがAccepterに送るメッセージ
- Promiseメッセージ=Prepareメッセージの返信。Accepterが現在受理しているIDと値
- フェイズ2
- Accept(n,v)メッセージ=ProposerがAccepterに値vを提案するメッセージ
- Accepted(n,v)メッセージ=Accepterが値vを受理したことを告げるメッセージ
- 各Learnerが過半数かどうかを判定(メッセージがロストするとインスタンスのやり直しが必要になる)
Paxosアルゴリズムの詳細は省略しますが、monitorはクラスターマップへの変更をPaxosインスタンスに書き出すことで、monitor間でクラスターマップの変更が同じになるようにしています。monitorはPaxosインスタンスに変更をWriteし、readはKVSを直接参照します。
CRUSHアルゴリズム(2)「オブジェクト」「プール」「Placement Group(PG)」
オブジェクトはプール名とオブジェクト名の組み合わせで特定します。プールは、オブジェクトの用途ごとにオブジェクト名前空間を分ける仕組みです。
クラスター(Ceph Storage Cluster)の構築が完了した時点で、3つのデフォルトプール「data」「metadata」「rbd」が作成される他、新たなプールの作成や既存のプールの名前変更・削除、プールのスナップショットの取得・削除などが可能です。
プールの属性としてデータ冗長度(オブジェクトのレプリカ数)、クラスター内にオブジェクトおよびレプリカを配置する仕方(後述するPlacement Group数やCRUSHルール番号)、所有者などを設定することができます。
ここで言及しているオブジェクトやレプリカがどのようなものかというと、実体はいずれもOSD上のファイルとして扱われます。各オブジェクトには、可用性を持たせるためにレプリカを複数のOSD上に置いています。Ceph/RADOSでは、あるオブジェクトのレプリカを置くOSDセットのパターンをPlacement Group(PG)といいます。
PGはプールを作成するとOSD数に応じた数が自動的に定義されます。クラスター内でOSD間の負荷の偏りを減らすために、OSDごとに50〜100のPG(データ冗長度で割って最も近い2のべき乗に切り上げる)を定義することが推奨されています。PGの数は後から増やすことができますが減らすことはできません。PGはPG番号で特定します。
オブジェクトとOSDのマッピングは直接的ではなく間接的に行われます。つまり、オブジェクトはいったんPGにマッピングされ、PGがOSDにマッピングされます。これはオブジェクトごとにOSDとのマッピングを管理する方法に比べて、メタデータの量を減らし、スケーラビリティと性能を向上させるための工夫です。
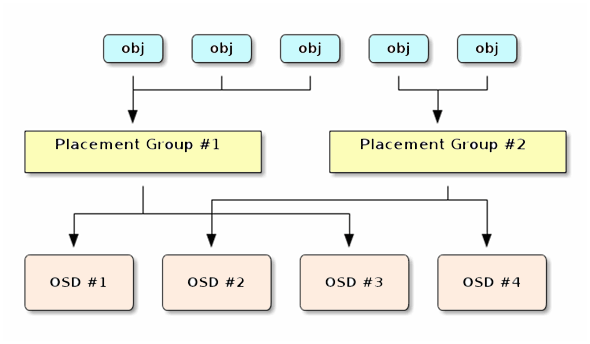
オブジェクトとPGのマッピングは次のような順で行われます。
- クライアントがプール名とオブジェクト名を入力
- CRUSHがオブジェクト名をハッシュ
- CRUSHがハッシュ値(mod PG数)でPG番号を得る
- CRUSHがプール名からプール番号を得る
- CRUSHがPG番号の先頭にプール番号を追加
Copyright © ITmedia, Inc. All Rights Reserved.