【Pythonで学ぶデータ分析】ベイズ統計の考え方をやさしく学ぶ 〜 初めてでも流れが分かる入門編:やさしい推測統計(ベイズ統計編)
初歩から応用までステップアップしながら学んでいく『やさしいデータ分析』シリーズ第5弾はベイズ統計編。今回は、二項分布の確率についてベイズ的な手法で母数の推定や検定を行います。
データ分析の初歩から応用まで少しずつステップアップしながら学んでいく連載『社会人1年生から学ぶ、やさしいデータ分析』のシリーズとして、「記述統計と回帰分析編」「確率分布編」「推測統計(区間推定編)」「推測統計(仮説検定編)」に続いて、「ベイズ統計」が始まりました。今回は、「背中をさするなどのケア(タッチング)は癒やしに役立つのか?」という事例を基に、母数の推定や検定を行うための考え方や手順を解説します。
この連載では、簡単な事例を見ながら、ベイズ統計の考え方と分析の進め方を解説します。新しい用語や考え方が幾つも出てきますが、全てを理解しなくても大丈夫です。登場するたびに、分かりやすく丁寧に説明するので、その時点で分からないことがあっても気にせず、先に進んでください。回を追うごとに、少しずつ理解が深まります。どんな考え方で、どんな手順で分析を進めるのか、といった大きな流れをとらえてください。
連載:
この連載では、データをさまざまな角度から分析し、その背後にある有益な情報を取り出す方法を学ぶ『社会人1年生から学ぶ、やさしいデータ分析』シリーズの「記述統計と回帰分析編」「確率分布編」「推測統計(区間推定編・仮説検定編)」に続く「ベイズ統計編」です。
これまでの推測統計を土台に、近年活用が広がっているベイズ統計の考え方と分析手順を、古典的な手法との違いを整理しながら解説します。初めての方でも無理なく理解できるよう具体例を通して進めるとともに、ベイズ的なアプローチの特徴やメリットを実感できる構成とし、「どのように考え、どう使い分けるのか」に重点を置いて解説していきます。
筆者紹介: IT系ライターの傍ら、かつて、非常勤講師として東大で情報・プログラミング関連の授業を、一橋大でAI関連の授業を担当。まだ発展途上のようだが、生成AIへの質問と回答を分野ごとにまとめ、体系的に整理、補足しつつ、さらに個別の学びを促す記述を加えた資料を一貫して作成できるツールが実用レベルで本格的に使えるようになると、書籍の概念が変わるのではないかと思ったりしている。一斉授業だったものが、ユーザーに合った個別指導のできる書籍といったイメージ。そうなると、出版社のビジネスモデルも大きく変わり、私の仕事もなくなってしまいそうだけど、まあ、そのときは、縁側でお茶でもすすりながら、庭の景色を眺めて暮らすことにしようと思う。ウチには縁側も庭もないけど。
タッチングは癒やしに役立つのか 〜 ベイズ統計によるデータ分析の簡単な例
では、ごく簡単な例を使って、ベイズ推定の大きな流れを見ていきましょう。毎年、私は健康診断で胃の内視鏡検査を受けるのですが、その際に看護師の方が、緊張を解くために検査中ずっと背中をさすってくれます。確かに緊張が和らいでリラックスできるような気がするのですが、実際のところタッチング(背中をさするなどのケア)にはそのような癒やし効果があるのでしょうか。
実は、医療や看護の現場でタッチングが癒やしに役立つ、といった研究はちゃんとあります(近藤ら(2011)など)。ただし、効果があるとしても、状況と相手によるので、これ幸いとタッチするのは癒やしどころか犯罪です。十分ご注意ください(念のため)。
本格的な研究ではかなり話が複雑になるので、ここでは心拍数などの生理的な指標を使わず、ごく単純化した架空の事例を使って、タッチングの効果がどの程度あるかどうかをベイズ推定によって検討してみます(図1)。

図1 タッチングに癒やし効果はあるか
事前には癒やし効果があるかどうかわからなかったので、癒やし効果がある確率θは0〜1のどの値も同じぐらい取り得るものと考えた(ブルーの平坦なグラフ)。その後、アンケートを採ると、30人中23人が「リラックスできた」と回答し、7人が「リラックスできなかった」と回答した。単純に、癒やし効果がある確率θを23/30=0.767と考えず、θには不確実性があるものと考えて推定を行う(例えば、230/300でも0.767となるが、その方が不確実性は小さいと考えられる)。データが得られた後(事後)のθは0.767辺りに山のある分布となった(平均はもう少し左の0.75)。
この事例を見て、「おや、似たような話があったな」と気付いた方もおられると思います。実は、分野こそ違え、この事例は前回見た「スマホで買い物をしたときにクーポンが当選する確率」の推定と全く同じ構造になっています。しかも、数値も全く同じです。このように、問題の構造に注目すると、皆さんの身近にある事例にも適用できるものが多いことが分かると思います。自分とは関係のない分野の話になると、その時点で興味を失ってしまう人もいるかもしれませんが、同じ構造になっている問題はよくあります。ぜひ、「自分が取り組んでいる問題だと、こういうことに当てはまるな」などと想像してみてください。
さて、ベイズ統計では、ベイズの定理に基づいた以下のような式をパラメーターθの推定のために使います。xは観測されたデータです。今回の例では(前回の例でも)試行数nと成功数kですが、代表してxとだけ書いています。πやL、mは関数であることを表します。これらの文字の代わりに、全てpやfと書かれている場合もあるかもしれません。そのような表記だと意味が区別しづらいので、ここでは異なる文字を使っています。

さまざまな資料や記事に、このような式がイヤというほど掲載されているので、どこかで見たことがあるかもしれませんね。しかし、残念ながら、ベイズ統計を学ぼうと張り切って入門書をひもといたのに、この段階で挫折してしまった方も多かったのではないかと思います(筆者も最初はここで何度も何度も足踏みしました)。実は、この式が言っていることは、単に、
- データを観測する前はこう思っていたけど(事前分布)、データを観測したら、考えがこう変わった(事後分布)
ということです。私たちが日常でごく普通にやっていることですよね。前回も同じことを言いましたが「これまでは納豆なんて臭くて食べられないと思っていたが(事前分布)、最近の納豆を実際に食べてみると(データの観測)、全然臭くなかった(事後分布)」などと同じです。
「データを観測したら」の部分は、式にくっついている尤度関数や周辺尤度で表されています。尤度(ゆうど)という聞き慣れない用語にとまどってしまいますが、これは軽くスルーしてもらってけっこうです。これも前回お話したことですが、完全に理解してから先に進もうとすると、いつまで経っても先に進めないという悲劇を招くことがあります。事例などを見ているうちに、式の意味が少しずつ理解できるようになる、という気持ちで取り組んでいきましょう。取りあえずは、(1)式の意味をこれ以上深く考えずに「そういうものがあるんだ」程度の気持ちで受け入れることにしましょう。ここでは、ざっくりと割り切って、
- ベイズ推定でやるべきことは事後分布を求めること
- 尤度関数と事前分布が決まれば、事後分布は求められる
とだけ言っておきます。
周辺尤度はとりあえず無視します。事後分布が求められれば、その平均(期待値)を点推定したり、区間推定したりできます。といっても、式に含まれる各項の意味が気になるという方もおられると思います。一応、次のコラムで簡単に説明しますが、かなり長くなるので、先に実行例を見てから、(いつか)戻ってきてもらっても構いません。
コラム ベイズの定理によるパラメーター推定のための式を解剖する
上で示した(1)式の意味を各項に分けて簡単に説明しましょう。今回の事例で何を求めたかったかというと、癒やし効果がある確率θの分布です。つまり、(1)の式の左辺に記されたθの分布(事後分布)です。事後分布は枠で囲んだ部分ですね。
この式では、πは円周率ではなく、関数を表します。一般的な関数ではなく、確率密度関数(=全体の面積が1)であることを表すために、一般的に関数を表すfなどとは別の文字を使っているだけです。ただし、事後分布(θの分布)は、得られたデータから推し測るしかないので、π(θ | x)と表されています。……と言われると「え、どういうこと」と、なりますよね。これが最初のハードルです。が、クリアするのは簡単です。
「|」の意味は「条件付き」ということです。π(θ | x)を日本語で読み下すと、「xというデータが得られたときの、θの分布を表す確率密度関数」ということになります。何も難しいことをいっているわけではありません。私たちがやりたいことを、ごく普通に「幾つかのデータを求めてください。すると、癒やし効果が得られる確率θの分布が求められますよ」と言っているだけです。具体的には、30回中23回がリラックスできたのであれば、癒やし効果が得られる確率θがどのような確率密度関数に従って分布するかが求められるというわけです(先走って答えだけ書くと、α=24,β=8のベータ分布です)。そうすれば、平均を点推定することも、全体の何パーセントかが含まれる確率を求める(つまり区間推定を行う)こともできますね。なお、ベータ分布については後で解説します。
次に進みましょう。目的とする左辺の分布(事後分布)は、式の右辺を計算すれば求められます。というわけで、右辺を見てみます。まず、事前分布です。以下の枠で囲んだπ(θ)の部分ですね。
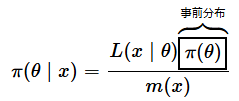
これは「こうなるだろう」とあらかじめ想定される確率θの分布です。何も分かっていないのであれば、θは0〜1の間のどの値も同じように取り得る、ということになりますね。つまり、一様分布になるわけです。ベータ分布でα=1,β=1を指定すれば一様分布になるので、今回はその設定を利用します。ただし、すでに何らかの研究や信じるに値する根拠があって、θの値はもっと大きいはずだとあらかじめ分かっている場合もあるかもしれません。その場合はベータ分布のαとβの値を調整します。例えば、α=5,β=3などのようにαの値を大きくすれば、山が右の方にある分布になります。またαとβの値を大きくすると事前分布の影響が大きくなります(つまり、これまでの知見などを強く反映できるということです)。
ところで、なぜベータ分布を使うのでしょうか。それは、ベータ分布の台(確率変数の取り得る値)が0〜1なので、確率の分布を表すのに適しているからです。さらに、上で少し触れたようにαとβの値を変えることによって、さまざまな形の分布や事前の確信度が表せるからです。事前分布(や事後分布)は、「確率θが0〜1の範囲でどのように分布するか」ということなので、このような性質を持つベータ分布がうってつけだというわけです。このことについては、確率分布編のこちらの記事でも解説しました。もちろん、パラメーターの分布が今回の事例と異なる場合には別の分布が使われます(が、それは今後のお話です)。ともあれ、第2のハードルもクリアですね。
続いて、第3のハードルとなる尤度関数です。以下の枠の部分です。

LはLikelihood(尤度)の頭文字です。この尤度関数は、文字通り「尤度」つまり、尤もらしさ(もっともらしさ)の関数です。「ちょっと待ってくれ! 尤もらしさって何なんだ!」と思われますよね。確かに、えらくあいまいな表現のように思われます。この「尤もらしさ」というのは、観測された値をそのパラメーターがどの程度うまく説明できるか、という意味です。
さらに、L(x | θ)という式も要注意です。単純に読み下すと「θが与えられたときのxの分布」と読めてしまいますが、そういうことではありません。xはすでに与えられており(30人中23人がリラックスできた)、それに対して、あるθを決めたとき、データxが得られることがどの程度尤もらしいかを表す分布です。ちょっと何言っているのか分からない……ですよね。後で、具体例を使って説明します。気にせず進めましょう。
この例では、尤度関数は、二項分布(試行数n、成功数k、成功確率θ)と同じ形の関数になります。具体的に書くと、以下のようになります。左辺のxは本来はn,kと書くべきですが、xで代表しています。
この尤度関数は二項分布と同じ形をしていますが、変数はθです(二項分布の変数はxですね)。xの関数ではなく、θの関数なので、混乱を避けるためにL(θ)とだけ書くこともよくあります。細かいことを言うなら、本来はL(θ| x)と書いた方が、意味がスッキリするのですが、ベイズの定理と合わせた書き方にすると上のようになるということです。なお、二項分布では成功確率をpと表すことが多いですが、ここでは、母数を一般的に表すのに使われるθという表記をそのまま使っています。
具体例で、尤度関数の意味を確認しましょう。例えば、n=30, k=23の場合、θ=0.5に対するL(x | θ)の値は、
となります。θ=0.5であることの尤もらしさが0.0019だというわけです。言い方を変えると、θ=0.5という値は、n=30, k=23というデータが観測されることを0.0019だけうまく説明できる、ということになります。同様に計算すると、θ=0.7に対するL(x | θ)の値は0.121です。従って、θ=0.7の方が、θ=0.5よりも0.121/0.0019≒64倍、尤もらしい(n=30, k=23というデータをよりよく説明できる)ということになります。「んー、まだピンとこない」という方も多いかもしれませんが、大丈夫です。尤度関数の意味があやふやでもベイズ推定はできます(もちろん、ゆくゆくは理解した上で使ってほしいのですが)。
最後は、周辺尤度ですね。以下の枠の部分です。

mはmarginal(周辺)の頭文字です。これについては、関数の形にはなっていますが、式を展開すると(ここではしませんが)、θで積分した値、つまり、定数になります。そして、これは全体の面積を1に調整するための係数(正規化定数)となっています。最初の(1)式全体を説明付きで再掲すると以下のようになります。

この式全体を少し俯瞰(ふかん)して見てみましょう。左辺は確率密度関数なので、全体の面積が1です。しかし、右辺の分子は全体の面積が1になりません。そこで、m(x)で割って全体の面積を1にしているということです。「それは分かったけど、周辺尤度の何が『周辺』なの?」と疑問に思われる方も多いと思います。それが最後のハードルとなりますが、こんなハードルなんてなかったものと考えてもらっても構いません。実際、このハードルを迂回してゴールにたどりつく方法があるからです(これも今後のお話です。また、「周辺」の意味については次回お話しします)。
タッチングが癒やしに役立つ確率をベイズ推定しよう
(1)式に従って、事後分布を求める方法には、解析的に求める方法(数式を計算して事後分布のパラメーターを求める方法)もありますが、事前分布と尤度関数の組み合わせによっては、周辺尤度を求めるのが難しく、解析的に事後分布のパラメーターを求めることが難しくなる場合があります。そのような場合には、MCMC(マルコフ連鎖モンテカルロ)法などによるシミュレーションが行われます。
今回の事例は、解析的に事後分布のパラメーターを求めることができるので、簡単です。まず、そのプログラムを見てみましょう。詳しい計算方法は省略しますが、この例のように、事前分布がベータ分布で、尤度関数が試行回数n、成功回数kの二項分布の形になっている場合は、事後分布のαに当たるパラメーターが、α+kとなり、事後分布のβに当たるパラメーターが、β+n−kとなるので、
- 事前分布: Beta(α, β)
- 事後分布: Beta(α+k, β+n−k) (2)
という極めて簡単な形になります(Betaはベータ分布を表します)。要するに、(1)式の右辺を計算すると、(2)式で表される左辺の事後分布Beta(α+k, β+n−k)が得られる、ということです。ちなみに、事前分布が(尤度関数と組み合わせたときに)事後分布と同じ形になるものを共役事前分布(きょうやくじせんぶんぷ)と呼びます(その場合、解析的に事後分布が求められます)。
ところで、二項分布の話なのに、なぜベータ分布が登場するのか、と怪訝(けげん)に思った方も多いのではないかと思います。この辺りもベイズ統計のハードルになっているようですが、簡単な話です。二項分布は、成功数kを横軸に取ったような確率分布ですよね。しかし、ここで知りたいのは母数である成功確率θの分布です。つまり、θを横軸に取ったような確率分布を求めたいわけです。成功確率θは、文字通り「確率」なので、0〜1の値を取るはずです。このθが変数となっていて、0〜1の範囲のそれぞれの値が「どの程度尤もらしいか」を表す分布を求めたいということです。すでに述べたように、ベータ分布は台(変数の取り得る値の範囲)が0〜1で、パラメーターα,βの指定により、さまざまな形の分布が表せるので、このような「確率がどう分布するか」を表すのに適しているというわけです。うーむ、よく分からんという方は、とりあえず、二項分布の母数θを推定するにはベータ分布を使うと都合がいい、と覚えておいてもらってもけっこうです。
ベータ分布は連続型の関数なので、例えば、θがちょうど0.5である確率が求められるわけではありません。確率密度関数の値は、その値が得られる確率そのものではなく、その値の近くの値がどの程度得られやすいかを表すものでしたね。なお、累積分布関数の値を求めれば、例えばθ ≤ 0.5などの、ある範囲に入る確率は得られます。
以下のコードは、事前分布をα=1,β=1のベータ分布(一様分布と同じ形になる)とし、30人中23人がリラックスできたという場合(試行回数n=30、成功回数k=23)の例です。この場合、(2)式に当てはめると、事後分布のパラメーターがα=1+23, β=1+30−23、つまり、α=24, β=8と計算されます。これらの値を基に事前分布と事後分布を可視化し、平均の点推定値と95%信用区間を求めています。
サンプルプログラムはこちらにあります。リンクを開くとPythonのプログラムが表示されるので、最初のコードセルをクリックし、[Shift]+[Enter]キーを押してプログラムを実行すると、結果が表示されます。コードの詳細については、リスト内のコメントや下のキャプションを参照してください。
import numpy as np
from scipy.stats import beta
import matplotlib.pyplot as plt
# 観測されたデータ
n = 30 # 試行回数
k = 23 # 成功回数
# 事前分布(prior)のパラメーター
alpha_prior = 1
beta_prior = 1
# 事後分布(post)のパラメーター
alpha_post = alpha_prior + k
beta_post = beta_prior + n - k
# 事前分布と事後分布の確率密度関数を求める
theta = np.linspace(0, 1, 500)
pdf_prior = beta.pdf(theta, alpha_prior, beta_prior) # 事前分布
pdf_post = beta.pdf(theta, alpha_post, beta_post) # 事後分布
# 事前分布と事後分布を可視化する
plt.figure(figsize=(10, 6))
plt.plot(theta, pdf_prior, label=f"prior:a={alpha_prior},b={beta_prior}")
plt.plot(theta, pdf_post, label=f"posterior:a={alpha_post},b={beta_post}")
plt.xlabel("theta")
plt.ylabel("Density")
plt.legend()
plt.show()
この事例では、事後分布のパラメーターalpha_postとbeta_postが簡単に求められるので、それを基にグラフを描けばよい。scipy.statsモジュールに含まれるbeta.pdfはベータ関数の確率密度関数の値を求める関数。numpyモジュールのlinspace関数を使ってthetaの値を0〜1の範囲で500個に刻み、確率密度関数の値をそれぞれプロットする。
実行結果は図2のようになります。

図2 事前分布と事後分布のグラフ
リスト1を実行した結果。事前分布はpriorと書かれたブルーのグラフ(一様分布)、事後分布はposteriorと書かれたオレンジのグラフ。0.767辺りに山のある分布となっている。データを観測することにより、事前分布(α=1,β=1のベータ分布=一様分布)が、事後分布(α=24,β=8のベータ分布)に更新された。
さらに、平均(期待値)を点推定と区間推定してみましょう。ベータ分布の平均(期待値)はα / (α + β)という公式で求められます。信用区間については、ベータ分布の累積分布関数の逆関数を使って求めます。コードは以下の通りです。
# 平均の点推定と区間推定(上のコードを実行した後で実行すること)
# 点推定(事後分布の平均):公式 alpha / (alpha + beta)による
post_mean = alpha_post / (alpha_post + beta_post)
# 区間推定(95%信用区間)
ci_low, ci_high = beta.ppf([0.025, 0.975], alpha_post, beta_post)
# 結果の表示
print(f"平均:{post_mean:.3f}")
print(f"95%信用区間: [{ci_low:.3f}, {ci_high:.3f}]")
# theta <= 0.5である確率も求められる
prob_le05 = beta.cdf(0.5, alpha_post, beta_post)
print(f"theta <= 0.5である事後確率: {prob_le05:.4f}")
# 出力例:
# 平均:0.7500
# 95%信用区間: [0.5890, 0.8814]
# theta <= 0.5である確率: 0.0017
ベータ分布の平均(期待値)は公式で求められるので簡単。95%信用区間は累積分布関数の値が0.025となるθから0.975となるθまでの範囲。scipy.statsモジュールに含まれるbeta.ppf関数を使ってベータ関数の累積分布関数の逆関数の値を求めればよい。さらに、累積分布関数の値を求めるbeta.cdf関数を使ってθが0.5以下である確率も求めてみた。
前回のおさらいになりますが、この結果で重要なのは、信用区間は母平均が95%の確率でこの範囲に入っていることを表している、ということです。
古典的な手法での信頼区間は、そうではありませんでした。「信頼区間を求めることを何回も繰り返すと、95%の回で母平均がその信頼区間に含まれる」ということでしたね。なんとも奥歯にモノのはさまったような表し方をしないといけなかったかと思います。古典的な手法では、母数は定数で、信頼区間が動くものと考えられるからです。
一方、ベイズ統計では、母数を確率変数としてモデル化しており、データが観測された後では信用区間は動かないので、素直に「95%の確率で信用区間に入っている」と言うことができます。従って、リスト2の最後のコードのように、θ ≤ 0.5である確率なども求められるわけです。ただし、0.5と比較することに意味があるかどうかは、タスクによって異なります。例えば、これまでの研究や経験から、70%(=0.7)以上の人が「リラックスできた」と答えなければ効果があるとみなせない、とするなら、θ ≥ 0.7である確率を求めるべきです。
タッチングが癒やしに役立つかどうかをベイズ二項検定で調べよう
厳密には検定とは異なる考え方ですが、古典的な検定に代わる簡単な方法として実務的によく使われているものに、ROPE(Region Of Practical Equivalence)と呼ばれる方法があります。例えば、θが0.5と差があるかどうかを調べる場合、ある程度幅を持たせた範囲、例えば、0.45 ≤ θ ≤ 0.55が完全に信用区間に含まれているか(いないか)を調べます。この例であれば、[0.45, 0.55]は、95%信用区間の[0.5890, 0.8814]の外にあるので、差があるとみなせます。
また、古典的な検定に対応するものとしては、ベイズ因子(ベイズファクター)によるモデル比較があります。ベイズ因子は2つの仮説(モデル)の周辺尤度の比で求められるのですが、前回少し触れたSavage-Dickey(サベージ・ディッキー)法では、ある点(例えば、0.5)における事前分布と事後分布の確率密度関数の値の比によって簡単に求めることができます。ここでは、過去の経験から、タッチングしない場合にはリラックスできる確率が1/2=0.5であることが分かっていたものとします。その場合、タッチングした場合の効果を吟味するための帰無仮説と対立仮説は以下のようになります。
- 帰無仮説H0: θ = 0.5
- 対立仮説H1: θ ≠ 0.5
実際の実験計画では、統制群として「タッチングをしない群」を設けて、どちらの群が癒やされた(リラックスできた)比率が大きかったかを比較するのが一般的です。しかし、ここでの事例はあくまでベイズ二項検定の考え方を紹介するためのもの、ということでこのまま進めましょう。この例では、事前分布も事後分布もベータ分布なので、確率密度関数の値は簡単に求められます。以下のようなプログラムになります。
# ベイズ因子BF10を求める(最初のコードを実行した後で実行すること)
prior_density = beta.pdf(0.5, alpha_prior, beta_prior)
posterior_density = beta.pdf(0.5, alpha_post, beta_post)
# Savage-Dickey法によるベイズ因子:θ=0.5に対する確率密度関数の比を求める(信用区間のコードにこのコードを追加した)
BF10 = prior_density / posterior_density
print(f"ベイズ因子BF10: {BF10:.3f}")
# 出力例:
# ベイズ因子BF10: 17.014
事前分布と事後分布のそれぞれについて、scipy.statsモジュールに含まれるbeta.pdf関数を使ってベータ関数の確率密度関数の値を求め、それらを使って「事後÷事前」の値を求めるとよい。結果はBF10=17.014となる。このことは、対立仮説H1が、帰無仮説H0の約17倍支持されることを意味する。
ベイズ因子BF10は、対立仮説H1が、帰無仮説H0の何倍支持されるかという指標です。逆に、ベイズ因子BF01は、帰無仮説H0が、対立仮説H1の何倍支持されるかという指標になります。BF10は、ある点における事前分布の確率密度関数の値÷事後分布の確率密度関数の値で求められ、BF01はその逆数となっています。ベイズ因子の値をどのように評価するかについては、以下のようなJeffreys(1961)の評価尺度が目安としてよく使われます。
| ベイズ因子 | 評価 |
|---|---|
| 1〜3.2 | ほとんど言及する価値はない |
| 3.2〜10 | 実質的な証拠となっている |
| 10〜32 | 強い証拠となっている |
| 32〜100 | 非常に強い証拠となっている |
| > 100 | 決定的な証拠となっている |
Jeffreys(1961)によるベイズ因子の評価尺度。上の例であれば、BF10=17.014なので、対立仮説H1を支持する「強い証拠」となっている。ただし、この評価尺度はあくまで目安であることに注意。文献によっては、3.2や32の代わりにキリのいい3や30として掲載している場合もある。
この例では、BF10の値が17.014となり、Jeffreysの評価尺度により、対立仮説H1が強く支持されることが分かりました。つまり、タッチングにより癒やし効果が得られる確率は0.5ではないといえます(この例は、いわゆる両側検定に対応する結果ですが、実質的に「0.5よりも大きい」と言っていいでしょう)。
ちなみに、H0をθ=0.7として計算してみると、BF10=0.265となり、その逆数を求めるとBF01=3.777となります。つまり、H0に対する「実質的な証拠となっている」というわけです。このことは、θ=0.7(癒やし効果がある確率は0.7である)ということを実質的に支持している、ということになります。このように、帰無仮説を支持する証拠の強さを評価できるのも、ベイズ的な手法の利点です。
最後に、ちょっと難しめのお話です。Savage-Dickey法には、仮説がネストしており、対立仮説の事前分布が連続型であり、パラメーターが1つである、といった制約があります。「仮説がネストしている」というのは、帰無仮説H0が対立仮説H1の特殊な値であるということです。この例では、H0はθ=0.5で、H1はθ ≠ 0.5だったので、その条件を満たしていないように思われます。しかし、ベイズ検定での対立仮説H1を正確に表すと「θはパラメーターα,βのベータ分布に従う」なので(前回、ちらっとお話ししましたね)、θ=0.5がその特殊な値になっていることが分かります。また、対立仮説の事前分布は連続型のベータ分布で、検定したいパラメーターもθだけなので、Savage-Dickey法が使えるというわけです。じゃあ、この方法が使えない場合はどうしたらいいの、という疑問も湧き起こるかと思いますが、それについても、連載の中で見ていきます。
ところで、今回の例ならExcelでもできるじゃないかと思われる方も多いと思います。上でも触れたように、事後分布のパラメーターが解析的に計算できる場合は、たいていの場合Excelでも計算できます。しかし、周辺尤度の計算が難しい場合には、そういうわけにはいきません。その場合は、シミュレーションを行って事後分布を求めます。上の例では、わざわざシミュレーションを行う必要はないので、今回は紹介しませんが、あえてやってみた場合のプログラム例をサンプルファイルの4番目のコードセルに含めておきました。ただ、現時点でコードを見ても、わけが分からないだけだと思われるので、特に解説はしないことにします。サンプルファイルを参照していただき「次回以降、連載を読み進めれば、こういったコードも理解でき、自分で書けるようになるんだ」と思っていただければよいかと思います。
今回は、二項分布の母数(成功確率)のベイズ推定、ベイズ二項検定の考え方と手順について解説しました。今のところはあまり意味を考えずに手順を追いかけていますが、これから少しずつ意味についても見ていきます。無理なくステップアップできるように、単純なものが少しずつ積み上げていくつもりです。
次回は、母平均のベイズ推定/ベイズ検定です。製造されたお菓子(具体的にはシュークリーム)の母平均を推定し、母平均が100グラムであるかどうかを検定するといった実用的なお話をします。どうぞ、お楽しみに!
今回使った主な関数
引数も主なものだけを掲載します。引数に「=値」と書かれたものは既定値(例:=True)を表します。
linspace: 等差数列を作成する
- モジュール: numpy
- 形式: linspace(start, stop, num=50, endpoint=True)
- 引数:
- start: 初項の値。リストや配列を指定すると複数の等差数列が作成できる
- stop: 末項の値。リストや配列を指定すると複数の等差数列が作成できる
- num: startからstopまでを幾つに区切るかを指定する
- endpoint: 末項を含む場合はTrue、含まない場合はFalse
beta.pdf: ベータ分布の確率密度関数の値を求める
- モジュール: scipy.stats
- 形式: beta.pdf(x, a, b)
- 引数:
- x: 確率変数の値。リストや配列を指定すると複数の値が求められる
- a: 分布の形状を表すパラメーター(分布の右側《1に近い方》に重みが加わる)
- b: 分布の形状を表すパラメーター(分布の左側《0に近い方》に重みが加わる)
beta.cdf: ベータ分布の累積分布関数の値を求める
- モジュール: scipy.stats
- 形式: beta.cdf(x, a, b)
- 引数:
- x: 確率変数の値。リストや配列を指定すると複数の値が求められる
- a: 分布の形状を表すパラメーター(分布の右側《1に近い方》に重みが加わる)
- b: 分布の形状を表すパラメーター(分布の左側《0に近い方》に重みが加わる)
beta.ppf: ベータ分布の累積分布関数に対する逆関数の値を求める
- モジュール: scipy.stats
- 形式: beta.ppf(x, a, b)
- 引数:
- x: 累積確率の値。リストや配列を指定すると複数の値が求められる
- a: 分布の形状を表すパラメーター(分布の右側《1に近い方》に重みが加わる)
- b: 分布の形状を表すパラメーター(分布の左側《0に近い方》に重みが加わる)
参考文献
近藤浩子, 小宮浩美, 浦尾悠子. (2011). 癒し技法としてのタッチの受け者と施行者における効果に関する研究. 東京医療保健大学紀要, 7(1), 1-10.
Jeffreys, H. (1961). Theory of probability(3 ed.). Oxford: Oxford University Press.
Copyright© Digital Advantage Corp. All Rights Reserved.