
XML&Webサービス開発事例研究(2)
リレーショナルDBへの挑戦
〜設計変更に強いネイティブXMLデータベース〜
| XMLとWebサービスの事例を紹介していく本シリーズの第2回は、ネイティブXMLデータベースを取り上げる。“データベースならOracle”という固定観念が通用しない情報系システム開発の事例から、新たなビジネスチャンスを考察してみたい。(編集局) |
編集局
2003/11/29
| 主な内容 |
システムインテグレータ(以下、SIer)が開発案件の特性に応じてネイティブXMLデータベース(以下、NXDB)を提案しても、顧客の「データベースならOracleでいいんじゃないの」と一言で却下されてしまう状況は多い。Oracleに代表されるリレーショナルデータベース(以下、RDB)は確かに信頼性やパフォーマンスにおいて顧客の信頼を勝ち得ているのは間違いない。しかし、これまで紙ベースで利用されてきたデータをWeb経由で利用したいといった情報系の開発案件に対して、すべてRDBを採用すればよいのだろうか。
本稿ではNXDBの強みが発揮された事例として、米国での2つの開発事例をレポートしよう。どちらも当初はRDBを前提にSIerが見積もりを作成したところ、膨大な運用コストの発生が明らかになり、NXDBへリプレイスされた。RDBさえあれば、すべてのシステムを作成できる、あるいはなにがなんでもRDBにデータを格納すればよい、といったRDB神話が崩れ去った事例である。
最初に紹介するのは、米国における自動車事故のデータ分析システム開発である。顧客の要求は“Excelのように”データのくし刺し検索をしたいというシンプルなものだった。
やっかいな非定型データを扱うシステムの開発
日本では交通事故の処理は警察庁の管轄であるが、米国では州ごとに異なる法律に従って事故処理を行っている。現在、全米50州のうち36州で個人情報を除いた事故データをCSV形式で一般に公開している。自動車保険会社や自動車メーカーは、この事故データをさまざまに分析して商品開発やマーケティングに活用したいと思っており、あるSIerにシステム開発を依頼した。
CSVデータをRDBに格納する場合、この事故データはいくつかの点で大きな問題を抱えていた。
- データ項目が不統一である(州ごとに違う)
- 州の法律が変わる可能性がある(項目追加の可能性)
- データを分析してみるまで、どの項目にインデックスを張ればよいか分からない
データ項目の不統一については、リスト1の2件の事故データを比較してみれば分かる。1件目はメリーランド州(<State> MD </State>)で、2件目はニューヨーク州(<State> NY </State>)である。
<?xml version="1.0"?> |
| リスト1 自動車事故データのXMLファイルから2件分を掲示した。1件目はメリーランド州、2件目はニューヨーク州で、項目の不一致個所を赤字で示している(空要素タグは調査項目にないことを示す)。 |
事故原因としてメリーランド州には「野生動物との衝突」(<Animal_Fatalities> 2 </Animal_Fatalities>)という項目があるが、ニューヨーク州にはないので空要素タグである(<Animal_Fatalities/>)。ほかにも、<Build_Month-Year>、<Tire_Miles>に違いが見られる。たった2つの州を比べただけでもこれだけ集計されている項目が異なっている。
一方、「車種名(Vehicle_Miles)」「メーカー名(Vehicle_Manufacturer)」「事故を起こした日付(Failure_Date)」など、共通する項目もあり、全体の70%くらいは共通して残りがバラバラという、非常に構造化しにくいデータであることが分かる。
さらに、集計される項目が州の法律改定によって変更されるリスクがあるという点も運用コストの面から無視できない。一般のシステム開発であればデータ構造の変更は、顧客の企業1社のみの都合に限られるが、この事例の場合、36州のそれぞれに変更リスクがあるわけだ。
仮に36州ごとにテーブルを1つずつ作成したとしても、くし刺し検索のパフォーマンスが問題になるのは容易に想像がつく。かといって、テーブルを正規化しインデックスを作成してしまうと、今度はデータ構造の変更時に大きなコストが発生する。さらに、未整理の状態であるこのデータについて、システム設計時にどの項目が頻繁に参照されるか予測できない。
これらの点を考慮した結果、このSIerはRDBの採用を断念せざるを得なかった。イニシャルコストは吸収できたとしても、運用コストを考えた場合、とてもRDBでは対応できないと判断したのだ。
NXDBによるソリューション
この案件でRDBに代わってデータベースに採用されたのは、NeoCore XMSというNXDBである。製品の詳細については「XMLデータベース製品カタログ 2003 〜ネイティブXMLデータベース編〜」を参照いただきたい。NeoCore XMSの特徴は
- 整形式(Well-Formed)XMLを格納できる(スキーマ設計不要)
- 独自のDPP(Digital Pattern Processing)技術によりすべてのエレメントにインデックスを張り、なおかつ高速なアクセスを実現する
の2点である。
NXDB製品は、RDBと違ってあらかじめ格納するデータの構造を定義する必要はない。格納するデータの制約はXMLの文法に従っていること、つまり整形式のXMLであればよい。この自由度の高さは、システム設計時に格納するデータ構造が決定していなくても開発を開始できるというメリットを生む。またデータはNXDB製品ごとに異なる内部構造であっても、ユーザーから見ればいわゆるDOMツリーをそのまま格納する形式なので、データに新たな項目が追加されても、あるエレメントに子エレメントを追加するだけのことで、データベース自体になんら変更を加える必要はないのだ。
上記の開発案件に即していうならば、州ごとに異なるデータ項目は<Automobile_Complaints>要素の子要素として格納されるので、項目が不統一であっても問題ない。開発者が注意を払ったのは同じ意味を持つ項目については同じ要素名を付ける、という点のみだった。例えば車種は<Vehicle_Miles>、メーカー名は<Vehicle_Manufacturer>といった具合だ。全項目の70〜80%を共通の要素名でくくることができたので、さまざまな条件でくし刺し検索が可能になった。
データ分析の実際
以下に、開発されたクライアント・アプリケーションを紹介しよう。ちなみに、このシステムはJavaで作成されており、およそ1〜2人月程度であったという。このアプリケーションを使ったデータ分析を再現してみよう。
 |
| 図1 <state>要素を集計した検索(クリックで拡大します) |
図1では、全件検索から州(state)項目について、出現回数の合計をグラフに表示している。単純に事故件数の多い州を降順にソートしてみると、テキサス州(TX)、カリフォルニア州(CA)、フロリダ州(FL)、アリゾナ州(AZ)といった気温の高い州に事故が多発していることが分かった。
次に、検索条件を車種(Vehicle_Model)として全州をくし刺し検索すると、フォード社製のEXPLORERが多く、6割くらいを占めることが分かった。これは何か異常な事態が起こっていると想像できる。
ではなぜフォード社製のEXPLORERというモデルに事故が多いのか。この分析を行うために、クエリの検索条件式に<Vehicle_Model>=EXPLORERを加える。すると気温の高い州が上位を占めた。そこで気温の高い州の傾向を分析する、といった手順で絞り込みをかけていく。同じ州(state)タグの中はOR条件で検索し、AND条件で車種などを加えるといった検索条件だ。タイヤのモデル(<Tire_Model>)で集計するとファイアストーン社製のATXというタイヤに事故が多いことが分かった(図2)。ファイアストーン社はブリヂストン社の子会社で、ATXの品質に問題があり、全米で大型訴訟になった件はご記憶の方も多いだろう。
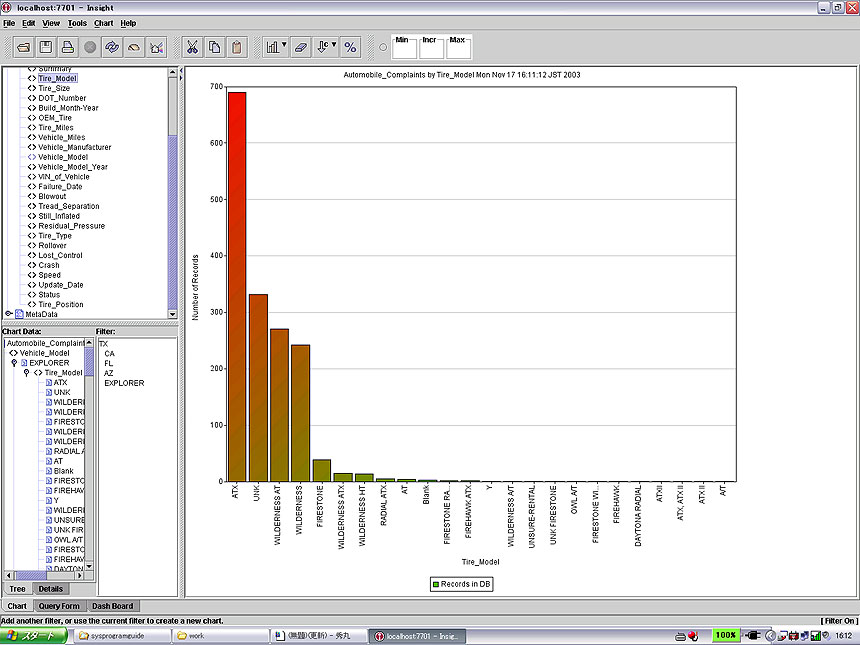 |
| 図2 絞り込み検索の条件は<state>をTX、CA、FL、AZ、<Vehicle_Model>をEXPLORERとし、<Tire_Model>を集計した(クリックで拡大します) |
図2で使用したクエリのXPath式をリスト2に示す。
|
| リスト2 気温の高い4州でEXPLORERの起こした事故について、装着していたタイヤをモデルごとに集計するXPath式 |
この事例では、顧客はどんな事故原因が多いのか、Excelでできる単純なくし刺し検索をしたかっただけである。ところが、扱うデータが非定型であると、RDBではデータ設計に多くの工数をとられる。顧客はなぜこの程度のことを実現するのに高額な開発費を請求されるのか理解できないだろう。顧客の要求とRDBの設計上の思想との乖離(かいり)が生じているのだ。
本稿で紹介するもう1つの事例は、データベースのスキーマ変更が多発する帳票アプリケーションだ。電子申請を実現するには、帳票のイメージをWeb画面に出し、入力されたデータをデータベースに格納していくという流れになる。帳票のようなドキュメント系のデータであればXMLがデータフォーマットとして適しているのは容易に理解できるだろう。
スキーマ設計から解放されたNXDB
NXDBのRDBに対する優位点の1つは、スキーマの設計変更に強いことである。構造化データの格納を前提としたRDBでは、システム設計の時点でデータ構造が明確に規定できていなければ、そもそも設計作業に入ることすらできない。さらに、システムの運用中に発生するデータ構造の変更要求に対しては、多大なコストが発生する。RDBは経理・財務システムなど事前にデータ構造を明確に定義でき、それが将来にわたって安定していることを前提としたデータベースであるといえよう。
これに対してXMLデータをツリー構造のまま格納できるNXDBは、データ構造に変更があったとしても、DOMツリーに部分木を付け足すだけで済むため、影響を受けるのはXMLデータを加工/表示するアプリケーション側のみである。例えば、10年前から運用している顧客マスターに携帯電話番号という項目を加える場合、NXDBなら新たに要素を追加すればよく、RDBのようにテーブルの変更やインデックスの作り直しといった作業は発生しない。
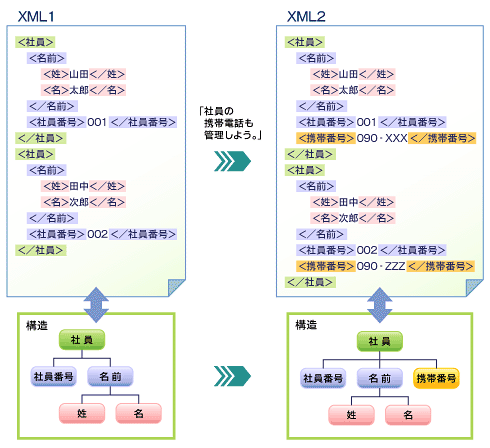 |
図3 XMLに要素が新たに追加されたときのデータ構造の変化 |
まず図4を見てもらおう。これはアドビ社の電子フォーム設計ツール、Adobe Form Designerで作成された申請書のサンプルだ。
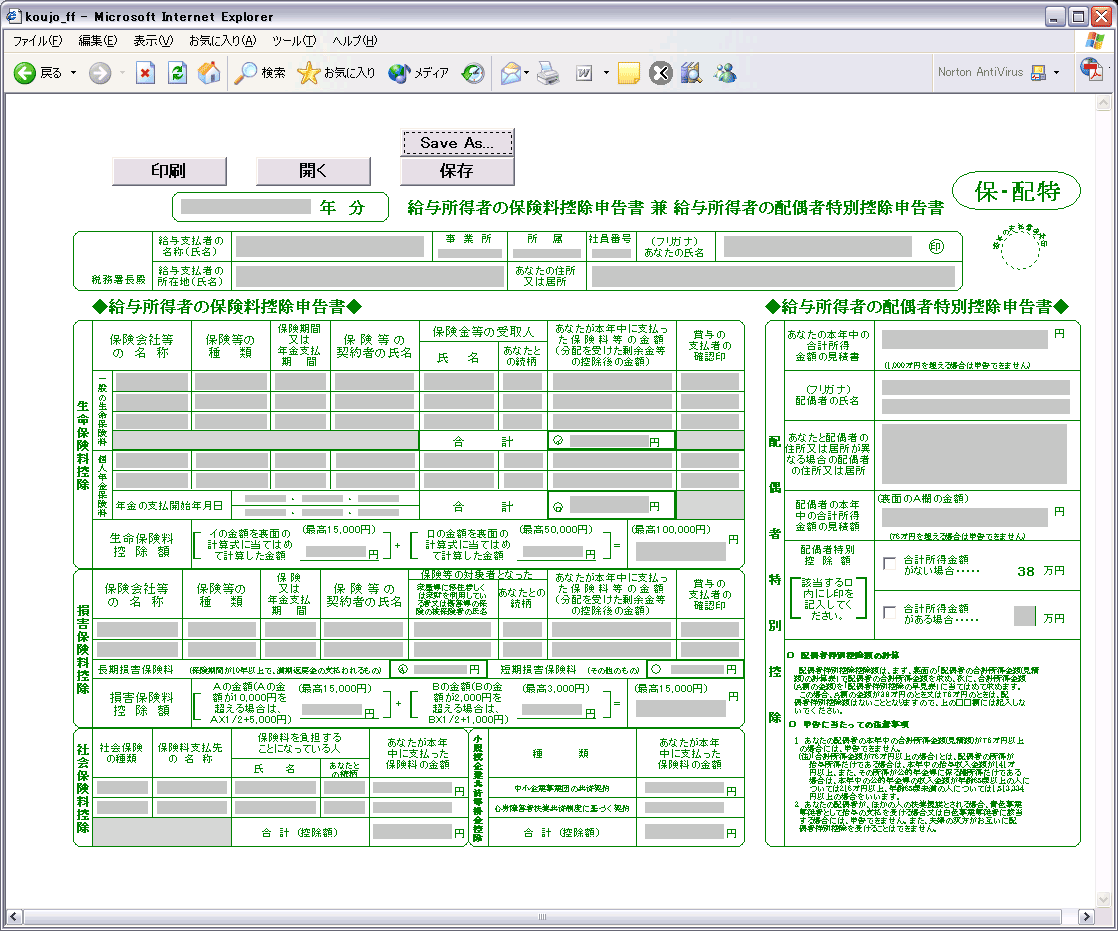 |
| 図4 年末調整でおなじみの申請書を電子フォーム化したサンプル(クリックで拡大します) |
このような申請書では、1つの画面に多数の入力フォームがある。データフローとしては、まずこのフォームをXMLデータとしてアプリケーションが受け取ることになるだろう。RDBを前提としたシステムでは、XMLで受け取ったデータを分解してRDBの表にマッピングしていく方法が考えられる。あるいは、CLOBなどのRDBのデータ型として、テキストデータで全部入れてしまう方法もある。前者ではテーブルを正規化してデータを格納するのは非常に工数を要するのは想像に難くないし、後者は検索パフォーマンスが落ちる。
開発期間が6カ月から6週間に短縮
これも米国の開発事例になるが、75種類の申請書を電子化するという案件で、アプリケーションがXML化されたデータを受け取り、それをデータベースに格納し、集計やワークフロー管理などをするアプリケーションを作るというRFP(提案依頼書)が出た。
1つの帳票をRDBのテーブルとして設計するだけでも大変だが、なおかつそれを75種類作らなければならない。くし刺し検索をする以上、75個のテーブルを作ればよいわけではなく、テーブルを分割して正規化しなければならない。開発期間はどんなにSIerが頑張ったとしても6カ月、BIツールのような洗練された画面を作るとなると8カ月は要すると見積もられた。
ところが、NXDBを採用すれば、すでにXML化されたデータを受け取るので、データベースの設計にかかる工数は必要ない。作り込みが必要なのは、ユーザーインターフェイスと検索部分の作り込みだけだった。開発期間はOracleで6カ月かかるといわれたものが6週間に短縮できたという。
開発期間の短縮だけではない。カットオーバー後の運用フェイズに入ってからも、法令の変更に伴うシステム変更は必ず生じる。変更は管轄行政機関から発せられ、変更を実施する期日も決められてしまうので、それまでにシステムを改修しなければならないわけだ。XMLでデータを格納していれば、新しい項目が追加されてもアプリケーション側の修正だけで対応できる。
この開発を請け負ったSIerは、変更コストをOracleの半分と請求しているそうだが、実際には20%のコストで済んでいるという。
現時点でNXDBの採用事例の8割は、本稿で紹介した2つの事例のようにRDBに入れにくいデータを扱ったもの、あるいはシステム設計の時点でデータ構造を完全に決定できない事例だといわれている。開発をしながら、さらに運用しながらデータを変更していけるという点が、NXDBの生かしどころとなる。逆に、顧客側にXMLデータが大量にあり、それを高速に検索したいといった事例は、すでにデータ構造が決まっておりRDBにマッピングできるため、NXDBが採用されるケースは少ないという。むしろ帳票システムのように、いますぐにシステム化したいのにRDBに入らない、といった顧客からの引き合いが強い。
検索パフォーマンスの問題
NXDB、あるいはオブジェクトデータベースにつきまとう問題は、検索パフォーマンスである。XMLツリーをトラバースして目的のデータにたどり着くDOMプログラミング式の検索では、データ量の増大に比例してパフォーマンスが劣化する。XMLデータは一般にデータ量が膨大になりやすい傾向にあり、検索パフォーマンスはNXDB最大の弱点といわれてきた。
NXDBベンダ各社は、それぞれの独自技術で検索パフォーマンス向上の対策を施している。詳しくは「XMLデータベース製品カタログ 2003 〜ネイティブXMLデータベース編〜」を参照していただきたいが、本稿で取り上げたNeoCore XMSは独自のインデックス技術、外部インデックスによる高速検索を目指すTaminoやEsTerra、メモリキャッシュを用いるSonic XISなど、各社各様の取り組みが見られる。
現時点において、あるいは将来においても、NXDBの検索パフォーマンスはRDBに追い付くのは難しいだろう。ただし、開発コストや運用コストの削減は、Webベースの情報系システムでは重要な優位性となる。検索パフォーマンスとのトレードオフとして個別案件ごとに判断すべき問題なのである。
◇
今回は一般的にマイナーな存在と思われているNXDBを取り上げて、その市場性を考察してみた。情報系システム開発でXMLは不可欠のデータとなっている現状を見れば、もう少しNXDBの活躍する場面は増えてもよいのではないか。本稿でNXDBへの認識を新たにしてもらえれば幸いである。
| 取材協力 三井情報開発株式会社 鉢蝋吉久 |
■関連記事
・XMLデータベース製品カタログ 2003
〜ネイティブXMLデータベース編〜
〜XML対応リレーショナルデータベース編〜
■連載
1. Webサービスで運用するRFID制御システム
2. リレーショナルDBへの挑戦
3. BIソリューションを支えるXML/Webサービス
| 「XML&Webサービス開発事例研究」 |
- QAフレームワーク:仕様ガイドラインが勧告に昇格 (2005/10/21)
データベースの急速なXML対応に後押しされてか、9月に入って「XQuery」や「XPath」に関係したドラフトが一気に11本も更新された - XML勧告を記述するXMLspecとは何か (2005/10/12)
「XML 1.0勧告」はXMLspec DTDで記述され、XSLTによって生成されている。これはXMLが本当に役立っている具体的な証である - 文字符号化方式にまつわるジレンマ (2005/9/13)
文字符号化方式(UTF-8、シフトJISなど)を自動検出するには、ニワトリと卵の関係にあるジレンマを解消する仕組みが必要となる - XMLキー管理仕様(XKMS 2.0)が勧告に昇格 (2005/8/16)
セキュリティ関連のXML仕様に進展あり。また、日本発の新しいXMLソフトウェアアーキテクチャ「xfy technology」の詳細も紹介する
|
|





