 標準化目前:注目のXML問い合わせ言語
標準化目前:注目のXML問い合わせ言語
XQuery 〜前編
本記事では、XMLのデータモデルを解説し、過去のXML問い合わせ言語を振り返りつつ、最新のXQueryの基本的な機能や概要をお届けする。
戌亥稔
ビーコンIT
2002/2/9
| XML問い合わせ言語とデータモデル |
2001年5月に私が執筆した書籍『実践XMLデータベース構築』(戌亥稔・田中聡・田中行広共著 オーム社)の中には、XML問い合わせ言語について説明した章があります。この章の執筆を始めたのは2000年の12月ごろで、本文には、そのころのXML問い合わせ言語の状況について「XMLの問い合わせ言語としては、複数提案されていますが、実際に標準化に近いとされているものはありません」と記述してあります。
しかしそれから約1年の間に、W3CのQueryワーキンググループからはXMLの問い合わせ言語として、以下の3つのワーキングドラフトが提出されました。
| 2001年2月15日 | 「XQuery: A Query Language for XML」 |
| 2001年6月7日 | 「XQuery 1.0: An XML Query Language」 |
| 2001年12月20日 | 「XQuery 1.0: An XML Query Language」 |
2001年12月20日に提出されたワーキングドラフト「XQuery 1.0: An XML Query Language」には、XSLワーキンググループとのジョイントワークであるということが示されており、実際に同じく2001年12月20日に提出されたワーキングドラフト「XML Path Language (XPath)」は、XQueryと多くの部分で共通しています。また、XQueryについては複数のデータベースベンダがサポートを表明していることからも、このXQueryが、XMLの問い合わせ言語として最も標準化に近い存在であることがいえるでしょう。
本記事では、今回と次回の2回にわたって、こうしたXMLの問い合わせ言語の現状を、技術的に解説したいと思います。今回は、XMLの問い合わせ言語とはどのようなものか、過去から現在までにどのような問い合わせ言語が検討されてきたのか、そして現在のXQueryの開発のベースとなる、XMLの問い合わせ言語に対しての要求仕様とはどのようなものか、といったことをXMLのデータモデルを参考にしながら解説します。次回は、実際にXQueryとはどのようなものなのか、XQuery 1.0の仕様、そしてXQueryの今後について解説をする予定です。
■問い合わせ言語の役割
私は常々、リレーショナルデータベースが多くの技術者たちに受け入れられてきた理由は2つあると考えています。1つ目は、ODBCやJDBCといったAPIが統合されてきたこと、そしてもう1つは、SQL(Structured Query Language)という標準の問い合わせ言語が存在したことです。
XMLには、XML文書へのAPIとしてDOMやSAXがあります。データベースのAPIという観点ではこれらはまだまだ不十分であるにしても、この2つのAPIはプログラマに広く受け入れられています。今後もXMLのAPIはDOM、SAXを中心として、さらに良いものが、提案されてくることを私も期待しています。
一方でXML文書への問い合わせ言語としては、いままでXPathが大きな役割を果たしてきました。しかしながら、XPathでは特定の文書の中を検索することはできても、複数の種類のXML文書を扱えないなど、問い合わせ言語として考えた場合には明らかな限界もあります。そこで、(XMLデータベースに格納された)XML文書への問い合わせを想定した、新しい問い合わせ言語が必要とされているのです。
■XML問い合わせ言語が求められる理由
XMLの最も重要な特徴の1つは、さまざまなデータソースからなる異なった種類の情報を、タグ付けによってXML文書形式で表現できる柔軟性です。この柔軟な特性を生かすためには、問い合わせ言語にもさまざまな種類のXML文書からデータを抽出したり、それを解釈できる柔軟な機能が必要となります。
例えばBtoBによる取引を行うと、見積もり依頼書や製品一覧や発注書など、あらゆる情報がさまざまな形式のXML文書として送られてきます。これを受け取った担当者は、何種類もある大量のXML文書の中から、自分の必要な情報だけを選択することが必要になってくるでしょう。
また、社内で作ったXML文書形式の資料を、社外のサプライヤーなどに公開することも、今後多くの企業が行っていくことでしょう。するとサプライヤーは、公開された大量のXML文書の中から必要な情報を抽出できるようにならなければなりません。
このように、XML文書形式で、交換されたり、格納されたり、表現されてくる情報が増えてきた場合、XML文書が大量に格納されたデータソースに対してインテリジェントな問合せを発行できることが、非常に重要になってくるのです。これが、柔軟なXML問い合わせ言語が求められる大きな理由でもあります。
■XML問い合わせ言語とデータモデル
SQLに代表される問い合わせ言語は、それを扱うデータモデル(情報の持ち方)と深い関係を持っています。リレーショナルデータモデルに基づいて定義された問い合わせ言語がSQLであり、オブジェクト指向のデータモデルに基づいて定義されたのがOQL(Object Query Language)です。XMLのデータモデルはリレーショナルデータモデルともオブジェクト指向のデータモデルとも違い、階層型のデータモデルです。それゆえXML専用の問い合わせ言語として、SQLやOQLではない新しい問い合わせ言語が必要であるとされています。
その1つの提案として、「XML Information Set」をベースとした、XMLのQueryデータモデルが複数のワーキングドラフトとして提出されています。特に最新のデータモデルは、XSLワーキンググループとXML Queryワーキンググループのジョイントワークとして提出されています。
| 2000年5月11日 | 「XML Query Data Model」 |
| 2001年2月15日 | 「XML Query Data Model」 |
| 2001年6月7日 | 「XQuery 1.0 and XPath 2.0 Data Model」 |
| 2001年12月20日 | 「XQuery 1.0 and XPath 2.0 Data Model」 |
XMLは、半構造型データと構造型文書を混在させることが可能です。例えば、インターネット上のホームページなどで公開されている情報には、文書と(表などの)データが混在して表現されているページなどがあります。こうした2つのデータ構造を混在させられるのはXMLの大変強力な特徴でもありますが、問い合わせ言語として要求される機能は、これとはかなり違います。
この2つのデータ構造に対する問い合わせ言語の例として、XQuery以前に提案された、半構造型データのモデルを基に開発されたXML-QLや、構造型文書を基に開発されたXQLなどがあります。これらがどのような問い合わせ言語かは、後述する予定です。
■XMLの基本データモデルはツリー構造
問い合わせ言語の解説に入る前に、XMLのデータモデルに関して、特にXML Queryに関連する部分に絞って解説をしましょう。XML Queryデータモデルの詳細についてはW3Cのテクニカルレポートを参考にしてください。
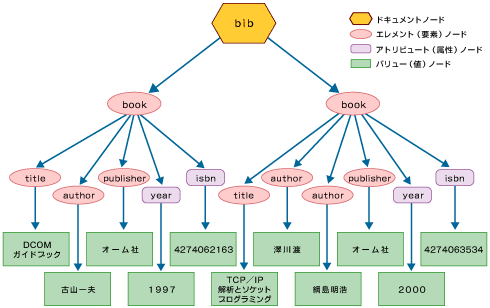
XMLのデータモデルはツリー構造を示します。以下のXML文書は本のタイトル、著者、出版社を表します。このXML文書は図1のように表すことができます。図1の中のbibノードはドキュメントノードを表していますが、XPathのRootノードと同じです。
<?xml version"1.0"
encoding="shift-jis" ?> |
|
リスト1 典型的なXML文書の例
|
 |
|
図1 順番を持たないXMLデータモデル
|
リレーショナルモデルでは、行(Row)と列(Column)を持つテーブルにデータが格納され、テーブルは関係(リレーション)を持ちます。例えば、従業員テーブル(列=従業員番号、名前、入社年度、年齢)はそれぞれの従業員が持っている属性情報です。また、部門構成テーブル(列=部門コード、従業員番号)は、それぞれの従業員と部門との関係を表します。また、テーブル(もしくは関係を持つ複数のテーブル)に対して発行された問い合わせの中間結果や最終結果も、行列を持つテーブルとして表されます。
それに対してXMLでは、親子もしくは子孫関係にあるノードからなるXML文書にデータが格納されます。図1で示すと、bookノードの子ノードtitleは「本のタイトル」を表し、「執筆者」はbookノードの子ノードauthorで表されます。“title”と“author”は、同じbookノードの子ノード(親ノードが同じ)であるという関係を持ちます。このようにXMLではデータが階層化されており、それらの親子や子孫関係を特定したり、そのパスをナビゲーションできることが重要となります。そして、検索の中間結果や最終結果も、やはりXML文書の構造を持って作成される必要があります。
XML文書のツリー構造の中で、もう1つ注目してほしいことがあります。それは、bibのノードが、その子ノードとして2つのbookエレメントを持つことです。左のエレメントは「DCOMガイドブック」というデータを持ったtitleエレメントを持ち右側のエレメントは「TCP/IP解析とソケットプログラミング」というデータを持つtitleエレメントを持ちます。
ここで右側のbookノードを説明する場合に「2冊目の本は『TCP/IP解析とソケットプログラミング』で、2人の執筆者がおり、1人目は澤川渡さんで2人目は綱島明浩さんです。」ということができるでしょうか? 本の1冊目、2冊目というのはどちらのノードを指し、執筆者の1人目、2人目はどちらのノードを指すのかをこのデータモデルでは表すことができません。このデータモデルを「順番を持たないXMLデータモデル」と呼ぶことにします。
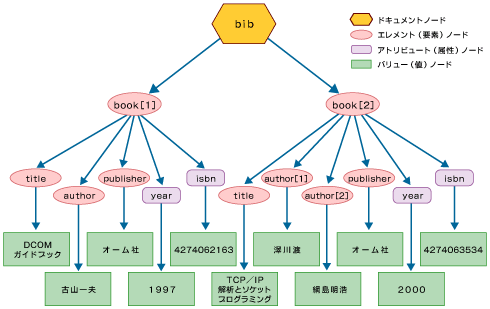 |
| 図2 順番を持つXMLデータモデル |
|
コラム データタイプとコレクションの追加
|
| 2001年12月20日にワーキングドラフトとして出された「XQuery
1.0 and XPath 2.0 Data Model」では、データタイプとドキュメントコレクションの考え方が追加されています。
データタイプの例として、図1と図2のバリューノードは「ストリングバリュー」と呼ばれる型を持ったバリューとして表すことが可能です。 また、図1と図2をドキュメントのコレクションで表した場合、bookをドキュメントノード(ルートノード)として表すことが可能です。この場合、ノードの順番はデータモデルの中で定義されているSequenceを使い、ドキュメントのコレクションはドキュメントノードのSequenceとして表すことができると記述されています。 |
図2はbook、authorにそれぞれ配列の要素番号を付けています。これによって「1冊目、2冊目」や「1人目、2人目」という順番を確定することができます。構造化文書ではこの順番が大きな意味を持つ場合があります。例えばお医者さんが使用するカルテで考えてみましょう。カルテには、病気について過去どのような症状に対してどのような処置を施したかが記録されています。ある患者の病状を振り返るときに、最後に処置したことは何か? 最後に注射をしたのはいつか? 病院に最初に運び込まれたときに行った処置は何か? またその後、症状がどのように変わったか? など順番を意識した問い合わせをする必要があります。これはカルテのようなメディカルレポートだけではなく、一般に構造化文書が持っている特徴です。
これらのXMLが持つ独特のデータモデルをベースとした問い合わせ言語が、XQuery以前にいくつか提案されてきました。その中で代表的な「XML-QL」と「XQL」を、次項で解説します。
| 1/6 |
| Index | |
| 注目のXML問合せ言語「XQuery」 | |
| XML問い合わせ言語とデータモデル ・問い合せ言語の役割 ・XML問い合わせ言語が求められる理由 ・XML問い合わせ言語とデータモデル ・XMLの基本データモデルはツリー構造 |
|
| XQuery以前に提案された問い合わせ言語 ・XML-QL ・XQL ・XML問い合せ言語として必要な機能 ・QuiltとXQuery |
|
| 2つの表現式、PathとFLWR ・表現式はシーケンスで表される ・Path表現式 ・FLWR表現式 |
|
| FLWR表現式の詳細 ・XQueryを試せるアプリケーション ・for句とlet句の違いは繰り返し ・Path表現式とFLWR表現式の違い コラム:複数のXML文書をXMLデータベースでどう扱うか? |
|
| SQLとXQueryはどう違う? ・リレーショナルモデルの演算とは ・XQueryの演算 |
|
| XQueryにおけるリレーショナルの演算 ・リレーショナルモデルの演算とは ・XQueryの演算 ・トランスフォーメーション ・次の課題は更新系の命令 |
|
- QAフレームワーク:仕様ガイドラインが勧告に昇格 (2005/10/21)
データベースの急速なXML対応に後押しされてか、9月に入って「XQuery」や「XPath」に関係したドラフトが一気に11本も更新された - XML勧告を記述するXMLspecとは何か (2005/10/12)
「XML 1.0勧告」はXMLspec DTDで記述され、XSLTによって生成されている。これはXMLが本当に役立っている具体的な証である - 文字符号化方式にまつわるジレンマ (2005/9/13)
文字符号化方式(UTF-8、シフトJISなど)を自動検出するには、ニワトリと卵の関係にあるジレンマを解消する仕組みが必要となる - XMLキー管理仕様(XKMS 2.0)が勧告に昇格 (2005/8/16)
セキュリティ関連のXML仕様に進展あり。また、日本発の新しいXMLソフトウェアアーキテクチャ「xfy technology」の詳細も紹介する
|
|





