ビッグデータを企業のメインストリームで活用可能にするOracle Big Data SQLのインパクト:一つのSQLで全てのデータを検索可能に(2/3 ページ)
多様なデータの活用をシンプル、迅速、そしてセキュアに
もっとも、大量の、しかも多種多様なデータを分析するために、それぞれのデータの特性や活用方法に最適なテクノロジを組み合わせてシステム基盤を作るのは簡単なことではない。
「データ/システムのイングレーションが複雑になる上、データの準備にも相当の手間が掛かります。しかも、これまで基幹データベースで扱ってこなかったSNSなどの新たなデータソースを安全に利用するために、データセキュリティも確保しなければなりません。こうした新たなデータの活用に掛かる途方もない手間や時間、コストに大きな負担を感じている担当者は少なくないでしょう」(大橋氏)
とはいえ、これらの課題を解決しなければ、ビッグデータ活用の利を手中にすることはできない。そこで、この問題に悩む多くの企業に向けて、オラクルは「あらゆるデータへのアクセスをシンプルにし、なおかつデータのセキュリティを高めて、ビッグデータ活用のスピードを飛躍的に高めるテクノロジ」(大橋氏)を開発した。それがOracle Big Data SQLである。

Oracle Big Data SQLは、オラクルのHadoopアプライアンス「Oracle Big Data Appliance」の上で実行され、Oracle Big Data Appliance上のHadoopデータと、企業の基幹データを格納したOracle Databaseの双方に対して、Oracle SQLによる一括検索を可能にする。具体的には、Oracle Databaseに対してSQLクエリを発行すると、HadoopデータはOracle Big Data Appliance側で検索処理され、Oracle Database側の処理結果とともに検索結果が得られるという。
しかも、Oracle Big Data ApplianceのHadoopノードには、Oracle Exadataで実績のある検索処理の高速化技術「Smart Scan」が搭載されており、極めて高速に検索処理が実行される。
また、SQLクエリはOracle Databaseを介して発行されるため、Hadoop上のデータに対しても、Oracle Databaseが持つ高度なセキュリティ機能(例えば、データマスキングや厳格なアクセス制御など)が適用されるという。
今日、大量の非構造化データを処理する目的でHadoopを使う企業が増えている。しかし、Hadoop環境の構築や活用には特別なスキルが必要とされ、それが「分析対象(のデータソース)を広げることの難しさ」や「異なるデータソースのデータを組み合わせて企業のメインストリームで活用し、新たな知見を得ることの難しさ」につながっていると大橋氏は指摘し、Oracle Big Data SQLの意義を次のように説明した。
「Hadoop上でのデータ活用など、ビッグデータ活用で多くの企業が直面しているさまざまな問題を抜本的に解決するのがOracle Big Data SQLです。これを使うことで、新たなスキル/ノウハウを習得する必要がなくなり、多くのエンジニアや業務ユーザーが使い慣れたSQLによってHadoop上の多種多様な新たなデータと、既に利用しているOracle Database上のデータを組み合わせて活用できるようになります。結果として、真のビッグデータ活用が実現され、ビジネス価値を創出するチャンスが飛躍的に広がるのです」
Oracle DatabaseとHadoopは相互補完的な関係。両者を組み合わせることで強力なビッグデータ基盤を実現できる
 日本オラクル データベース事業統括 製品戦略統括 データベースエンジニアリング本部の能仁信亮
日本オラクル データベース事業統括 製品戦略統括 データベースエンジニアリング本部の能仁信亮「Hadoopには特有の強みがあり、Oracle Databaseにも得意分野と強みがあります。この両者の強みを生かした情報基盤を容易に構築できことがOracle Big Data SQLの大きなメリットであり、また魅力でもあります」──こう語るのは、大橋氏に続いて壇上に立ち、Oracle Big Data SQLの技術的な特徴を解説した日本オラクルの能仁信亮氏(データベース事業統括 製品戦略統括データベースエンジニアリング本部)である。
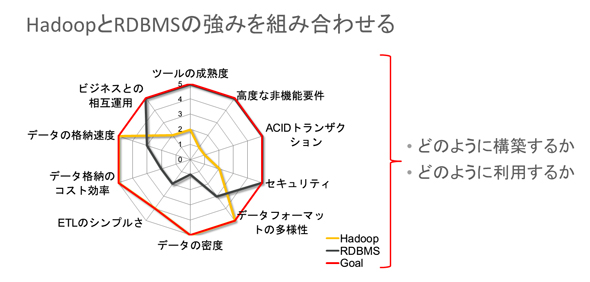
能仁氏によれば、Hadoopでは基本的に分散ファイルシステムが使われており、そのファイルシステム(HDFS:Hadoop Distributed File System)には任意のファイルをデータフォーマットの変換なしで格納することができる。これが、Hadoopの「多様なデータフォーマットへの柔軟な対応」「データ格納の高速性」「データ格納のコスト効率の高さ」「ETLのシンプルさ」といった強みにつながっているわけだ。
ただし、HadoopのHDFSにはデータがそのまま置かれるため、データを読み取る際にはデータ構造解析の処理が必要となる。それにより、データの読み取り/検索のパフォーマンスが悪くなる他、データの更新処理も苦手としており、ACIDトランザクションへの対応に課題がある。また、セキュリティやツールの成熟度も低く、業務システムとの連携や非機能要件への対応も不得手といったHadoopの特性を指摘した上で、能仁氏は次のように続ける。
「逆に、そうしたHadoopの弱点は、Oracle Databaseが強い部分でもあります。つまり、両者は相互補完的な関係にあり、それぞれの強みを組み合わせることで、これまでにない強力なビッグデータ基盤を構築できるのです」
Copyright © ITmedia, Inc. All Rights Reserved.
提供:日本オラクル株式会社
アイティメディア営業企画/制作:@IT 編集部/掲載内容有効期限:2014年9月24日
関連情報
驚異的なパフォーマンス、優れた運用効率、最高の可用性とセキュリティ、クラウド対応を実現するOracle Exadataとの統合、クラウド、可用性や運用管理など、次世代データベース基盤構築のために参考になる必見資料をまとめてご紹介いたします。





新着記事






![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。