ビッグデータを企業のメインストリームで活用可能にするOracle Big Data SQLのインパクト:一つのSQLで全てのデータを検索可能に(3/3 ページ)
Oracle Big Data SQLはOracle DatabaseとHadoopを論理的に統合する
それでは、Oracle Big Data SQLは、具体的にどのようなメカニズムによってHadoopとOracle Databaseの強みを融合するのだろうか。
そのメカニズムの中心を成すのは、HadoopとOracle Databaseのメタデータ連携である。端的にいえば、Oracle Big Data SQLでは、Hadoopのメタデータ(Hiveメタデータなど)をOracle Database側に取り込むことで、HadoopとOracle Databaseの論理的な統合を実現している。Hadoopのメタデータを取り込むことで、Hadoop上のどこに、どのような情報が存在するのかをOracle Database側で外部表として定義し、SQLで活用できるようになっているのだ。これにより、「ユーザー側からは、Hadoop上のデータとOracle Databaseのデータが、全てOracle Databaseのテーブルとして見える」という環境が実現される。

また、Oracle Database上からHadoopに対してSQLクエリが発行された際には、Hadoop(Oracle Big Data Appliance)側で多くの処理が実行される。
例えば、Hadoopの各ノードに分散したデータとOracle Database上のテーブルを結合して返すといったクエリが発行されたとしよう。このクエリはHadoopの各ノードに実装されたOracle Big Data SQLのコンポーネントが受け取り、HDFSからのデータの取り出しやデータ形式の解釈といった処理が行われる。それらのデータがSmart Scanによって必要最小限の行列に絞り込まれた後、Oracle Databaseに返されるのである。
「この処理フローは、Hadoopの特性にもフィットした、非常に効率性の高いものです」と能仁氏は語る。
「Hadoop上のデータを活用する際に高コストとなるのが、ファイルを読み取り、データ形式を解釈するプロセスです。それらのプロセスがOracle Big Data Appliance上で自動的に処理されるため、リソースの有効活用が可能となり、効率性が大きく高まります。また、行列の絞り込みもSmart Scanによって高速に実行されるので、Hadoopデータの処理プロセス全体が高速かつ効率的に実行されます」(能仁氏)

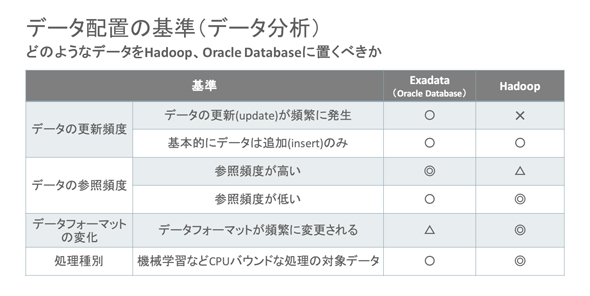
なお、能仁氏によれば、ビッグデータ分析を効率化するためには、データ配置の最適化が必須となる。具体的には、Hadoop(Oracle Big Data Appliance)とOracle Database上に、それぞれどういったデータを、どう配置するのかを十分に吟味しなければならない。その検討時の参考情報として、能仁氏は最後に次のような判断基準を紹介した。読者がHadoopとOracle Databaseによるビッグデータ環境を構築される際の参考にされたい。
以上、ここではOracle DBaaS&Big Data Summitにおけるセッションの内容を基に、HadoopとOracle Databaseの融合を実現するOracle Big Data SQLの特徴と、これが企業のビッグデータ活用にもたらす価値を紹介した。同製品が登場した今、ビッグデータの活用において最も高いアドバンテージを得ているのはOracle Databaseユーザーかもしれない。これをぜひ、既存のデータベース基盤を生かした新たなビジネス価値の創出に役立てていただきたい。
Copyright © ITmedia, Inc. All Rights Reserved.
提供:日本オラクル株式会社
アイティメディア営業企画/制作:@IT 編集部/掲載内容有効期限:2014年9月24日
関連情報
驚異的なパフォーマンス、優れた運用効率、最高の可用性とセキュリティ、クラウド対応を実現するOracle Exadataとの統合、クラウド、可用性や運用管理など、次世代データベース基盤構築のために参考になる必見資料をまとめてご紹介いたします。





新着記事






![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。