パーティショニングとパラレル処理は最高の相性:Oracleパーティショニング実践講座(3)(4/4 ページ)
本連載では、大規模データベースでのパフォーマンス・チューニングの手法として、Oracleパーティショニングを解説する。単なる機能説明にとどまらず、実機による検証結果を加えて、より実践的な内容をお届けする。(編集部)
パラレルDML
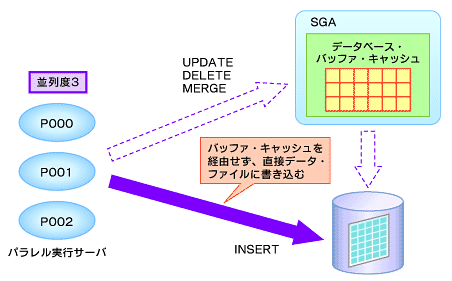
パラレルDMLでは、副問い合わせを含む行の追加(insert as select)、更新(update)、削除(delete)、問い合わせ結果からの追加更新(merge)の処理が可能です。また図12のようにinsert文はダイレクトロードインサート(バッファ・キャッシュを経由せずに直接データファイルに書き込む)の処理となります。
コラム:Oracleバージョンによる制限
Oracle9i Database R9.0.1以前までは、パラレルDMLの更新、削除、追加更新には以下の制限がありました。
- 操作するパーティション数を超える並列度で処理できない(パーティション数に限定)
- 非パーティション表に対してはパラレル化できない
Oracle9i Database R9.2.0以降ではこの制限がなくなり、以下のことが可能となりました。
- パーティション数を超える並列度でパラレルDMLを実行
- 非パーティション表に対してパラレルDMLを実行
コラム:セッション単位によるパラレル実行の指定
パラレル処理はSQL内に直接ヒント句を記述することで実行できますが、セッション単位で指定することも可能です。以下のalter文で、後続のSQL文をパラレルで実行できます。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
逆にenableをdisableにすることで使用禁止にできます。なおDMLに関しては、このalter session文を明示的に発行し、パラレルDMLを使用可能にした場合のみ、パラレル化できます。パラレルDMLを直接指定する場合、例えば次のように実行します。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
上記のSQLでは、リモート環境のemp_master表をローカルのemp表に挿入する処理をパラレルに実行します。
パラレルDMLとロールバック・セグメント
DMLをパラレルに実行する際、それぞれのパラレル実行サーバは独自のパラレル・プロセス・トランザクションで作業の一部を実行します。そのため、自動UNDO管理の代わりにロールバック・セグメントを使用する場合、パラレル実行サーバのトランザクションで利用されるロールバック・セグメントの競合を軽減しなければならない場合があります(図13)。
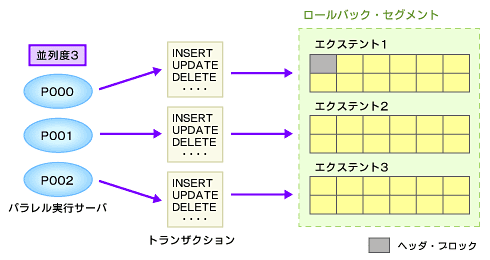
このような場合、パラレルDMLを実施する並列度以上のロールバック・セグメントを用意し、ロールバック・セグメントの競合が発生しないような環境を整える必要があります。
パラレルロード
パラレルロードは、主にSQL*Loaderで同一の表に同時にデータを挿入することを意味します。SQL*LoaderはCSV形式のデータをOracleの表に挿入(ロード)するユーティリティで、パラレルロードには2種類の方法があります。
従来型ロードの分割
従来型ロードとは、insert文を実行してCSVデータをデータベースにロードする操作です。リスト3の場合、CSV形式の入力ファイルを3つのSQL*Loaderがそれぞれ読み込み、表に対して並列ロードすることを表しています。このケースでは制御ファイルが同じであるため、すべてのデータが同じ表にロードされますが、複数の表に同時にロードすることもできます。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
パラレルダイレクトロード
バッファ・キャッシュを経由せずに直接データファイルに書き込むダイレクトロードを、複数のSQL*Loaderで並列して実行することをパラレルダイレクトロードと呼びます。SQL*Loaderの「parallel」オプションを「true」に設定することで、ダイレクトロード時に複数の同時セッションによって同じ表にデータをロードすることを許可します(リスト4)。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
このようなSQL*Loaderのパラレルロード処理は、データベースの移行やDSSおよびDWHなどのETL処理で利用されています。
パラレルData Pump Export/Import
Oracle 10gからリリースされたData Pump Export/Importユーティリティ(以下、Data Pump)は、従来のExport/Importユーティリティと比べてより高速にデータをロード/アンロードすることが可能となりました。この高速なData Pumpをパラレル化することにより、さらに処理能力を向上させることも可能です。
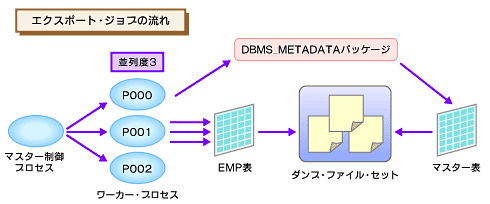
Data Pumpでは一連の処理をジョブとして扱います。Data Pumpのそれぞれのジョブが実行されると、まず1つのジョブにつき1つのマスター制御プロセスが作成されます。このプロセスはData Pumpのジョブの実行と順番の割り当てを制御します。
ワーカープロセスは、ジョブの実行開始要求を受け取ると同時にマスター制御プロセスに作成されるプロセスで、マスター制御プロセスが要求する処理を同時に実行します。パラレル処理の場合には、このワーカープロセスが複数起動する仕組みとなっています。
最後に
今回はパラレル処理の概要を中心に、機能、特徴、考慮点などをご説明しました。大規模データを高速に処理するためには、パラレル処理が非常に有用で、さまざまな活用方法があることはもちろんですが、何よりもパーティショニング環境において、その効果を最大限に発揮できることがお分かりいただければ幸いです。
次回は、パラレルクエリ、パラレルDDL、パラレルDML、パラレルロード、パラレルData Dumpのそれぞれの検証結果を紹介します。
Copyright © ITmedia, Inc. All Rights Reserved.