Hadoop用リアルタイムクエリエンジン Impalaのポテンシャルをレビューした:Databaseテクノロジレポート(4/4 ページ)
2012年10月24日に発表されたばかりのHadoop用リアルタイムクエリエンジンをいち早くレビュー。次期CDHに組み込まれる予定の新機能をどう使いこなす?
ベンチマーク結果
Hadoop MapReduce+HiveとImpalaのそれぞれの場合について、ベンチマークした結果を表2と表3に示します。平均処理時間は5回測定した平均値です。
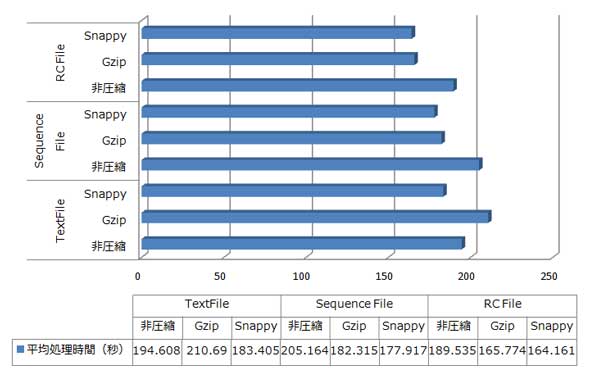
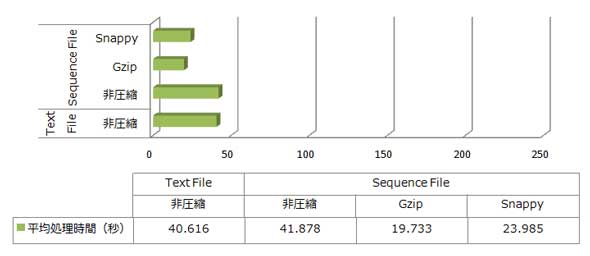
Hadoop MapReduce+Hiveで最も高速に処理できたのは、Snappyで圧縮されたRCFileの場合で約164秒でした。一方、Impalaで最も高速に処理できたのは、Gzipで圧縮されたSequenceFileの場合で約20秒でした。つまり、最も処理時間が短い組み合わせ同士を比較すると、ImpalaはHadoop MaReduce+Hiveよりも8倍以上も高速に処理できました。
まとめ:アドホックなクエリ処理には十分、ただし処理データの設計には注意
今回、ClouderaからリリースされたImpalaとHadoop MapReduce+Hiveの性能比較を行いました。
HiBenchというベンチマークツールを使用し、15台のクラスタ構成でSELECTクエリの処理時間でベンチマークした結果、Impalaは、まだβ版である現段階でもHadoop MapReduce+Hiveよりも8倍高速にクエリを処理できることが分かりました。
今後、CDH5にパッケージングされる見込みのImpalaの正式版では、Hiveストレージフォーマットとして、カラム指向の「Trevni」や「RCFile」がサポートされる予定です*7。そのため、今回のベンチマーク結果よりもさらに高速に処理できることが期待できます。
一方、手動によるアドホックなクエリを実行する分には、現状のβ版でも十分に利用できますので、もし現状のHadoop MapReduce+Hiveの処理時間が業務遂行上のボトルネックとなっているのであれば、利用を検討する価値はあるかもしれません。
ただし、高速な処理性能を維持する点では注意が必要です。
今回の検証では、1億レコードのテーブルを利用してベンチマークを行いましたが、実はHiBenchのデフォルト設定で生成される10億レコードのテーブルを利用したベンチマークも少しだけ試しました。そのベンチマークではスワップ処理が頻発したため、ImpalaはHadoop MapReduce+Hiveよりも2倍程度しか高速に処理できませんでした。
このことから、テーブルのレコード数が増えれば、もっと差が縮まると予想されます。つまり、高速な処理性能を安定して維持するためには、処理対象となるデータ量に応じてクラスタを設計・構築する必要があるといえます。
*7 本稿*1を参照。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 ネットアップがClouderaと協業、エンタープライズ領域でのビッグデータ活用は進むか
ネットアップがClouderaと協業、エンタープライズ領域でのビッグデータ活用は進むか
Clouderaがネットアップと協業。Hadoopシステム運用向けのサーバ類やストレージを一括で提供するソリューション展開とともに、技術交流も深めるという。 Hadoop+Oracleで構築:米国立がん研究所、「政府機関ビッグデータソリューション賞」受賞
Hadoop+Oracleで構築:米国立がん研究所、「政府機関ビッグデータソリューション賞」受賞
CTO Labsは11月20日、「Government Big Data Solutions Award」の受賞機関に、米国立がん研究所(NCI)のフレデリック国立研究所が選ばれたと発表した。 イベントレポート:Hadoop普及のキモは既存「言語」の取り込みにある
イベントレポート:Hadoop普及のキモは既存「言語」の取り込みにある
Hadoopを使ったビッグデータ分析はエンタープライズ領域に本当に浸透する? Clouderaはエンタープライズ市場の開拓に向けて着実に開発を進めているようだ SQLライクなクエリがHiveの10倍速に:ClouderaがHadoop用リアルタイムクエリエンジンを発表
SQLライクなクエリがHiveの10倍速に:ClouderaがHadoop用リアルタイムクエリエンジンを発表
Hadoop用のリアルタイムクエリを高速に実現するプロダクトがApacheライセンスで登場。リアルタイムデータクエリとBI的な利用を両立させる手法に選択肢が広まる