大量データ処理時に知っておきたいAmazon DynamoDB活用テクニック4選:大規模プッシュ通知基盤大解剖(2)(2/3 ページ)
大規模プッシュ通知基盤について、「Pusna-RS」の実装事例を基にアーキテクチャや運用を解説する連載。今回は、アプリ単位でテーブル分割を行い「スループットの奪い合い」を防ぐ方法、「全件走査用テーブル」を用意して処理を効率化する方法、Amazon SQSやAWS CloudWatchと連携して「スループット超過エラー」を防ぐ方法、「並列スキャン」で読み取り速度を向上させる方法などを紹介します。
【2】「全件走査用テーブル」を用意して処理を効率化する
プッシュ通知のために使用しているDynamoDBのテーブルは、デバイス情報テーブルとプッシュトークンテーブルの2つがあり、それぞれ次のような設計になっています。
- デバイス情報を持つテーブル。主に次のカラムを持つ
- デバイスID(プライマリキー):クライアントアプリが内部で払い出す端末識別用のID
- デバイストークン:GCM/APNsへのプッシュ通知リクエスト用のトークンです
- アプリ付加情報:クライアントアプリが独自に付与したデバイス別のメタデータを格納します
- デバイスID逆引き用テーブル。主に次のカラムを持つ
- デバイストークン(プライマリキー)
- デバイスID
テーブル設計で特徴的なのは、デバイストークンの全走査用テーブルを用意している点です。このテーブルは、アプリに登録されたデバイスを全対象とするプッシュ通知配信機能などにおいて、GCM/APNsを介したプッシュ通知に必要なデバイストークンを全デバイス分取得するために利用しています。テーブルからトークンを全て取得する際には、後述する「Scan API」を利用しています。
Scan APIはデータサイズが大きくなるほど読み出し速度のパフォーマンスが低下するため、テーブルを分けることにより全件走査のパフォーマンスを効率化しているのです。
【3】Amazon SQSやAWS CloudWatchと連携して「スループット超過エラー」を防ぐ
DynamoDBでは、読み書き性能をプロビジョンドスループットとして設定できるため、その設定値を大きくした分だけ高い性能を得ることができます。一方で、予測しない負荷集中が起きたときなどに読み書きの速度がプロビジョンドスループットを超える場合、DynamoDBはAPIリクエストにおいて「スループット超過エラー」を返却するようになります。エラー発生時のリクエストで行うはずだったデータの読み書きは、当然ながら実行されません。
プッシュ通知を行うシステムの特性上、スマートデバイスからのシステムへのデバイス情報更新リクエストは、各端末へのプッシュ通知を行った直後に集中し、DynamoDBのデバイス情報テーブルへの負荷も急増します。このとき、負荷がスループット設定値を超えることで発生する大量のスループット超過エラーへの対策を考える上で、以下のような問題があります。
- スパイク的に発生する消費スループットの最大値に合わせてプロビジョンドスループットを高くするのはコスト的に無駄になってしまう
- スループット消費に合わせて動的にスループットを変更する仕組みも考えられるが、スループットを落とす設定リクエストが1日4回に制限されており、1日複数回発生する負荷のスパイクに追随しきれない
そこでPusna-RSでは、「Amazon SQS」(以下、SQS)のメッセージキューシステムを活用し、DynamoDBへの書き込みを非同期化することでスループット超過エラーの大量発生を防いでいます。具体例として、スマートデバイスからシステムへのデバイス情報登録処理を行う“デバイス登録API”周りの構成を下に示します。
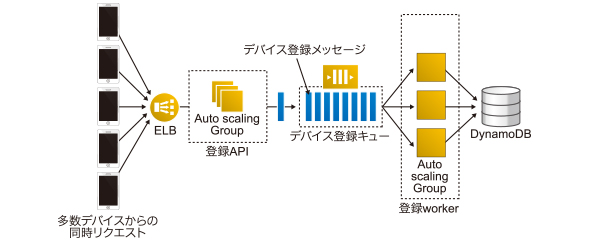
具体的な動作イメージは下のような順になります。SQSを使うことで、DynamoDBへの書き込み負荷を設定スループットに沿った形での平滑化を実現できています。
- スマートデバイスからのデバイス情報登録リクエストをデバイス登録APIが受信
- 登録APIはリクエストからDynamoDBへ書き込みたいメッセージをSQSに登録
- SQSに登録されたメッセージをデバイス登録Workerが取得
- デバイス登録Workerがテーブルの設定スループットを超えない速度でメッセージをDynamoDBに書き込み
この構成では、スループット超過エラーによるDynamoDBへ読み書き失敗を防ぐことができますが、スループット値を超える負荷が続いた場合は、書き込みリクエストに対し処理が追いつかないのでSQSにメッセージがたまり続けてしまう状況になってしまいます。
このように、SQSへメッセージが滞留するのを防ぐために、キューにたまったメッセージ数が一定を超えるとアラートとなる監視設定を「AWS CloudWatch」で行っています。アラートの頻度や傾向に応じてスループット値の設定を見直すことで、データ登録が遅延し過ぎることによってプッシュ通知システム全体に影響が出ることのないよう安定した運用ができています。
前述の通り、DynamoDBでデバイス情報を登録するテーブルは、Pusna-RSを利用するクライアントアプリごとにそれぞれ存在しています。初めは複数テーブルに対し、処理用のキューは1本しか用意しておらず、サービス開始時、Pusna-RSの利用頻度がそれほど高くない時期は複数アプリテーブルに対する書き込み処理でも1つのキューで処理を十分に平滑化できていました。
ところが、Pusna-RSの利用頻度が高くなってくると、処理が詰まってしまう問題が起き始めました。キューが1本しかないために、書き込み処理が遅延しているアプリ別情報テーブルが1つでもあると、キューに滞留したメッセージの詰まりが他のアプリ情報テーブルへの書き込み処理に波及し、雪だるま式にキューが詰まってしまうためです。
1つのアプリへの負荷がシステム全体の処理を遅延させてしまう状況は絶対に避けなければならないので、キューをアプリケーションごとに用意するようにして、アプリ単体の負荷が局所的になるように対策しました。この教訓から言えることとして、処理時間や負荷の異なる処理は1つのメッセージキューにまとめず、複数のメッセージキューに分けるようにするのがSQSで処理を平滑化するためのコツだと思いました。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 AWS「Mobile Push」を発表、1つのAPIで各社の端末にプッシュ通知が可能に
AWS「Mobile Push」を発表、1つのAPIで各社の端末にプッシュ通知が可能に
モバイル端末OS向けのプッシュ機能を発表。単一のAPI操作で主要端末へのプッシュ通知機能を利用できる。 BaaSを使えばアカウント認証やプッシュ通知は、もう面倒くさくない
BaaSを使えばアカウント認証やプッシュ通知は、もう面倒くさくない
ここ2年ほどの間で広まってきたクラウドサービス「BaaS(Backend as a Service)」。バックエンドにリソースを割かずに済むBaaSの機能としてデータストア、ソーシャルサービスとの連携、認証機構、プッシュ通知などをiOSアプリから使う方法を解説。 Chrome拡張機能にpush通知をしよう
Chrome拡張機能にpush通知をしよう
簡単なGoogle Chrome拡張機能を作成し、それにGoogle Cloud Messaging for Chrome機能を追加しましょう。 AndroidビームとPush通知で最強のO2Oアプリを作る
AndroidビームとPush通知で最強のO2Oアプリを作る
今注目の「O2O」について、現状や概要を紹介し、O2Oを利用したAndroidアプリを作る際に必要な技術要素を1つ1つ解説していきます。今回は、O2Oの技術要素の1つとして、Push NotificationとNFCについて、実際にアプリに組み込んだ例を示しながら解説します。 Androidのウィジェットにノーティフィケーションするには
Androidのウィジェットにノーティフィケーションするには
 Push Notificationを使ったiPhoneアプリ13選
Push Notificationを使ったiPhoneアプリ13選