
第6回 IntelとCell/B.E.のベクトル演算
株式会社フィックスターズ
好田 剛介
2010/2/15
CPUの周波数の高速化競争が頭打ちになり、1コアにおける処理能力は限界となった。CPUの進化がマルチコア化に向かった結果、並列コンピューティングの門戸が開かれた(編集部)
ベクトル演算を使った高速化
ベクトル演算を積極的に用いてプログラムを高速化する方法を説明します。
CPUの持つベクトル演算という機能は、第2回「現代のプロセッサと並列実行」でも解説しましたが、おさらいしておきましょう。
ベクトル演算とは、CPUの持つ命令のうち、複数個の整数値や実数値に対して1つの演算を同時に実行させるものです。
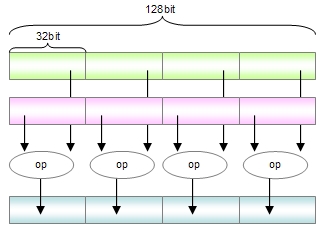
例えば、4個の32bitデータを1個の128bitデータにまとめ、op演算を行う場合のベクトル演算は、図1のようになります。
Intel SSE演算器
PCの世界で有名なIntelのプロセッサもベクトル演算を持っています。いわゆるx86アーキテクチャのベクトル演算としては、最初にMMXが登場しました。
Intelのプロセッサでは、複数のスカラデータをベクトルデータにまとめたものをパックドと呼んでおり、8bitデータをまとめたものをパックドバイト、16bitデータをまとめたものをパックドワード、32bitデータをまとめたものをパックドダブルワードと呼んでいます。
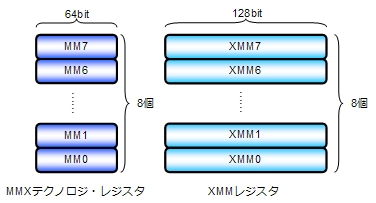
MMXでは、8個の64bitMMXレジスタに置かれた、パックドバイト、パックドワード、パックドダブルワードの整数に対してベクトル演算を行うことができました。
その後、同社はさらにベクトル演算を強化したSSEを世に送り出します。SSEでは、8個の128ビットXMMレジスタあるいはメモリに置かれた、パックド単精度浮動小数点数も扱えます。
SSE2では、パックド倍精度浮動小数点数を扱えるようになりました。SSE3では、ビデオ処理、複素数演算、スレッド同期等のために、SIMDデータの非対称処理、水平計算の簡易化、キャッシュライン分割ロード防止のための命令を扱えるようになりました。
SSSE3では、デジタルビデオと信号処理に関する命令が増えました。
SSE4.1では、ビデオ、画像処理、3Dを高速化する命令が追加となり、また、パックドダブルワード演算が強化されました。
SSE4.2では、いわゆる数値計算のための命令だけでなく、文字列操作のための命令もサポートされました。これによって、Cの標準ライブラリにあるstrlen()関数のような基本的な文字列操作について、SSEによる高速化が期待できます。
後にx86は拡張され、64ビット・モードを持つようになります。64ビット・モードではXMMレジスタが16個になりました。

以上のように、SSEは段階的にさまざまな命令やレジスタを追加しています。より詳しくは、Intelが提供している「インテル(R)64アーキテクチャーおよびIA-32アーキテクチャー最適化リファレンス・マニュアル」を参照してください。
ベクトル演算以外にも現行のx86系プロセッサの構造全般について丁寧に記載されている資料ですので、これから同プロセッサを学ぼうとする方に適していると思います。
Cell/B.E. SPE ベクトル演算器
PlayStation 3で有名なCell Broadband Engine(Cell/B.E.あるいはCBEあるいは単にCellと略される)もベクトル演算器を持っています。
Cell/B.E.は、PPEとSPEの2種類のコアを内包しています。PPEでは、VMXと呼ばれるベクトル演算器を持っています(ほかのPowerPC系プロセッサにおけるベクトル演算器の名称から、Altivecと呼ばれることもあります)。一方、SPEは、PPEとは独自の命令セット持っています。
SPEは、ベクトル演算を基本としたプロセッサで、四則演算などほとんどの命令はベクトル演算となっており、128bitレジスタのみを128個持っています。SPEの性能を引き出すためには、ベクトル演算を使いつつ128個あるレジスタを有効活用する必要があります。
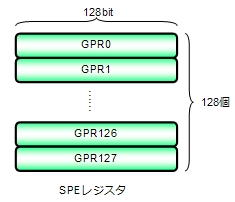
SPEのベクトル演算では、128bitのレジスタを8bit×16個、16bit×8個、32bit×4個、64bit×2個、128bit×1個の形で扱う命令があります。
SPEでスカラ演算を行いたい場合には、128bitレジスタ内の特定の場所(プリファードスロットと呼ばれる)にスカラデータを入れたベクトルデータに対してベクトル演算を行い、ベクトルデータの結果のうちスカラデータが格納されている場所を使用します。スカラデータを入れた以外の部分は、演算が行われるものの結果は捨ててしまいます。つまり、スカラ演算であっても、内部的にはベクトル演算が行われます。
Cell/B.E.に関するより詳しい情報はIBMが提供している「Cell Broadband Engine Programming Handbook」を参照してください。SPUのベクトル演算以外にもCell/B.E.系プロセッサの構造全般について丁寧に記載されている資料ですので、これから同プロセッサを学ぼうとする方に適していると思います。
また、フィックスターズでもCell/B.E.に関する総合的な情報を掲載しています。
1/2 |
| Index | |
| IntelとCell/B.E.のベクトル演算 | |
| Page1 ベクトル演算を使った高速化 Intel SSE演算器 Cell/B.E. SPE ベクトル演算器 |
|
| Page2 ベクトル演算のためのデータ構造 簡単なベクトル演算例(SPE on PlayStation 3) |
|
| Think Parallelで行こう! |
- プログラムの実行はどのようにして行われるのか、Linuxカーネルのコードから探る (2017/7/20)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。最終回は、Linuxカーネルの中では、プログラムの起動時にはどのような処理が行われているのかを探る - エンジニアならC言語プログラムの終わりに呼び出されるexit()の中身分かってますよね? (2017/7/13)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。今回は、プログラムの終わりに呼び出されるexit()の中身を探る - VBAにおけるFileDialog操作の基本&ドライブの空き容量、ファイルのサイズやタイムスタンプの取得方法 (2017/7/10)
指定したドライブの空き容量、ファイルのタイムスタンプや属性を取得する方法、FileDialog/エクスプローラー操作の基本を紹介します - さらば残業! 面倒くさいエクセル業務を楽にする「Excel VBA」とは (2017/7/6)
日頃発生する“面倒くさい業務”。簡単なプログラミングで効率化できる可能性がある。本稿では、業務で使うことが多い「Microsoft Excel」で使えるVBAを紹介する。※ショートカットキー、アクセスキーの解説あり
|
|
注目のテーマ





