|
特集 2. 多様なIAサーバ向けプロセッサを把握する(1) |
|

プロセッサが最も重要なコンポーネントの1つ、という点ではIAサーバもデスクトップPCと変わらない。例えばIAサーバをアプリケーション・サーバとして運用する場合、プロセッサの性能はサーバ全体の性能に大きな影響を及ぼす。しかしIAサーバの場合、プロセッサに求められる要件はそれ単体の性能だけではない。ここでは、IAサーバのためのプロセッサの要件について解説し、次に世代交代の時期にあるIAサーバ向けプロセッサのラインアップと将来のロードマップについて説明しよう。
IAサーバにマルチプロセッサが必要な理由
クライアントPCでは、ハイエンド・デスクトップPCやPCワークステーションで2プロセッサ構成(2ウェイ構成とも呼ぶ)をサポートしている場合があるが、市場全体からすれば数は非常に少ない。一方、IAサーバでは2基以上のマルチプロセッサ構成をサポートする製品は決して珍しくなく、エントリ・クラスを除けば標準装備といっても過言ではない。これは、プロセッサ性能に関するスケーラビリティを確保するためだ。
サーバ・システムの性能を高めるには、サーバ単体で性能向上を図るスケール・アップと、サーバの台数を増やして性能向上を図るスケール・アウトという2種類の方法がある。どちらが優れているかはアプリケーション次第であり、例えばデータベースならスケール・アップの方が適しているといわれている。
ではスケール・アップでサーバ・システムの性能を高めるとして、プロセッサによる性能向上の方策としては、
(1)プロセッサ単体の性能を高める
(2)同時に稼働させるプロセッサの数を増やす
の2つが考えられる。(1)では、クロック周波数を高めたり、1クロックあたりに実行できる命令の数を増やしたりするなどの方法があるものの、現実的には使用する半導体の性能や集積度、コストなどの制約により、単一のプロセッサだけで実現できる処理能力には限界がある。実際、プロセッサを含む半導体の性能は、おおよそ18〜24カ月で2倍というペースで向上しているが、それより早いペースで業務が拡大するなどしてサーバの負荷が増大した場合、(1)の方法だけでは対処しきれない。また、プロセッサ単体の性能を向上させるためには、Pentium III Xeon(Pentium IIIベースのIAサーバ向けプロセッサ)からIntel Xeon(Pentium 4ベースのIAサーバ向けプロセッサ)に変更するなど、大きなアーキテクチャの変更が伴うことが多く、実際にはプロセッサ単体ではなく、サーバ全体を交換せざるを得ない場合もある。
一方(2)では、プロセッサ数を増やした分だけ整数倍で性能が向上するわけではない(通常、数が増えるほど性能向上率は下がっていく)ものの、サーバの負荷増大に合わせてプロセッサ数を増やしていくことで、必要な性能を維持できる。より多くのプロセッサを搭載できるIAサーバを選べば、それだけ性能向上の幅、すなわち性能に関するスケーラビリティを確保できるわけだ。大雑把にいって、ワークグループ・サーバでは最大2基、ミッドレンジ・サーバでは最大4基、エンタープライズ・サーバでは8〜32基、といった具合に、サーバの規模に応じてプロセッサを搭載できるようになっている。
マルチプロセッサの実現方法
IAサーバにおけるマルチプロセッサ・システムの実装は、4ウェイ以下の場合と4ウェイより多い場合で大きく異なる。その違いはIAサーバの開発/製造コスト、ひいては販売価格に大きく影響する重要なポイントだ。まずは4ウェイ以下の場合の実装方式を見てみよう。
 |
| IAサーバにおける2〜4ウェイ構成 |
| これはIntel製IAサーバ向けプロセッサの例で、バス共有型SMP(Symmetric MultiProcessor)といえる。プロセッサの外部バス(プロセッサ・バス)を介して最大4基のプロセッサとチップセットを信号線で直結している。シンプルな構成ゆえコストは比較的安価だが、各プロセッサからメモリへのアクセスが増加すると、アクセスがお互いに競合して性能が下がりがちになる。 |
この方式の特徴は、各プロセッサが平等に扱われる点だ(SMP:Symmetric MultiProcessor、対称型マルチプロセッサと呼ばれる)。メイン・メモリは全プロセッサから平等に共有され、アクセス速度も同じならメモリ・アドレス空間も同じである(UMA:Uniform Memory Architectureと呼ばれる)。単一のプロセッサ・バスに各プロセッサを接続していくので、プロセッサ1基当たりの追加コストは比較的安価に済む、というメリットがある。
しかし、限られた帯域を持つプロセッサ・バスを全プロセッサが共有するので、メモリ・アクセスの競合が生じやすく、プロセッサ数に対する性能向上率が悪化する原因になりがちだ*2。かといってプロセッサ・バスの速度を上げて帯域を広くし、競合を抑えようとすると、電気信号の正常な伝送が難しくなり、プロセッサ数を増やせなくなる。上図の方式では、現時点でプロセッサ数は4基が上限のようだ。
| *2 AMDは、サーバ/ワークステーション向けプロセッサ「Athlon MP」にて、2基のプロセッサをそれぞれ独立したバスでメイン・メモリと接続する方式を採用している。原理的には上図のバス共有型より性能が優れているが、バスの本数が増えるため、プロセッサ数が増えると技術的難易度も実装コストも高くなるという難点もある。(Athlon MP対応チップセットは2ウェイまでのサポートであり、4ウェイ対応チップセットはまだ登場していない)。 |
では4基を越えるマルチプロセッサ・システムは、どのようにIAサーバで実現されているのか? 実はさまざまな実装方式があり、標準と呼べるものは定まっていない。下図は比較的採用例の多い実装方式である。
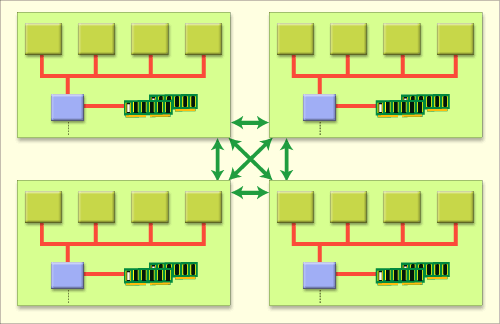 |
| 4ウェイを超えるマルチプロセッサ・システムの実装方式の例 |
| これは最大16ウェイの場合の例。最大4ウェイのバス共有型SMPシステムを基本のモジュールとし、これを複数用意して高速なバスやスイッチで相互接続する。各プロセッサはモジュールをまたいでメモリ・アクセスが可能だ。メインフレームのスイッチ技術をベースとするものが増えてきている。 |
要は、前述した4基までのバス共有型SMPシステムを1モジュールとし、モジュール単位で増設していくことでプロセッサ数を増やすという方式である。図の真ん中は各モジュールを相互に接続する回路で、例えば左上のモジュール内にあるプロセッサが右下のモジュール内のメモリにアクセスする、といったことを可能とする。基本的に各プロセッサは、全モジュールに搭載されているメモリにアクセス可能であり、メモリ・アドレス空間も共有している。ただしモジュールをまたいだメモリ・アクセスは、モジュール内でのアクセスより遅くなる(こうしたメモリ・アーキテクチャはNUMA:Non Uniform Memory Architectureと呼ばれる)。
この方式のメリットは初期投資額を抑えつつ、スケーラビリティを確保できることだ。具体的には、負荷が軽い当初は1モジュールだけ装備し、業務が拡大して負荷が重くなってきたらモジュールを追加してプロセッサ数を増やせる。最初から8〜16プロセッサを搭載可能なハードウェアを用意するのに比べ、原理的には初期投資額を抑えられるわけだ。
ただし、モジュールを追加したときの性能向上率は、モジュール間の相互接続の部分がどれくらい高速に通信できるかによって、大きく左右される。つまり、この相互接続の部分の性能がシステム全体の性能に大きく影響を及ぼす。各メーカーは独自にこの相互接続の部分を開発しており、コモディティ化しつつあるIAサーバの中でもメーカーの独自性が色濃く残っている数少ない部分といえる。逆にいえば、まだ標準化されていないこともあり、4ウェイまでのバス共有型SMPシステムに比べて開発/実装コストは非常に高い。現状では、コストより性能やスケーラビリティを非常に重視するエンタープライズ(ハイエンド)・サーバに限定された技術といえる。
こうした4基を越えるマルチプロセッサ実装方式は、もともとメインフレームなどのために開発された技術であり、それがIAサーバにも実装されるようになってきたといえる。これからエンタープライズ(ハイエンド)・サーバ市場に切り込むIAサーバにとって、重要な武器となるはずだ。
|
SMPシステムのプロセッサは同じもので揃える |
| 関連リンク | |
| Athlon MPの製品情報ページ | |
| 「System Insiderの特集」 |
- Intelと互換プロセッサとの戦いの歴史を振り返る (2017/6/28)
Intelのx86が誕生して約40年たつという。x86プロセッサは、互換プロセッサとの戦いでもあった。その歴史を簡単に振り返ってみよう - 第204回 人工知能がFPGAに恋する理由 (2017/5/25)
最近、人工知能(AI)のアクセラレータとしてFPGAを活用する動きがある。なぜCPUやGPUに加えて、FPGAが人工知能に活用されるのだろうか。その理由は? - IoT実用化への号砲は鳴った (2017/4/27)
スタートの号砲が鳴ったようだ。多くのベンダーからIoTを使った実証実験の発表が相次いでいる。あと半年もすれば、実用化へのゴールも見えてくるのだろうか? - スパコンの新しい潮流は人工知能にあり? (2017/3/29)
スパコン関連の発表が続いている。多くが「人工知能」をターゲットにしているようだ。人工知能向けのスパコンとはどのようなものなのか、最近の発表から見ていこう
|
|





