|
特集 4. 大容量化するメイン・メモリを支える技術(1) |
|

ここまでのページでは、IAサーバの概要ならびに搭載されるプロセッサについて見てきた。続いて、メモリ・サブシステムについて考察していこう。
大量のデータを高速に処理するIAサーバでは、下表のような要件がメモリ・サブシステムに求められる。ここでは特にメイン・メモリにフォーカスしながら、要件を満たすための技術やその注意点、差別化のポイントなどを解説する。
| 要件 | 理由 | 対応する技術 |
| 大容量(高い拡張性) | できる限り大量のデータをメモリ上で処理することで、ディスク・アクセスの頻度を減らし、処理速度の低下を防ぐため。また、データの増大に応じてメモリ容量を増やせる必要もある | Registered DIMMによるメモリ・モジュールの大容量化、メモリ・バス系統の複数化によるメモリ・ソケット数の向上 |
| 優れた耐障害性と可用性 | メモリ・チップの故障やソフト・エラーが発生しても、メモリ上のデータの損失を防ぎ、かつ処理を継続させるため | ECCメモリ、Chipkill、メモリの二重化(ミラーリング)、ホットスペア、ホットスワップなど |
| 高いスループット | 高性能なプロセッサからの高速なメモリ・アクセスと、複数のI/Oデバイスとのデータ転送を同時に実行する必要があるため | メモリ・バス系統の増加によるバス幅拡大、より高速なメモリ・デバイスの採用 |
| IAサーバのメモリ・サブシステムにおける要件 | ||
| それぞれの要件を満たすための技術には相互に関連性があり、同時に実現しやすい(詳細は後述する)。 | ||
IAサーバに大容量メモリが必要なのはなぜ?
IAサーバで大容量のメモリが効果的なのは、ディスクへのアクセス頻度をなるべく減らして、処理速度を高める(処理速度の低下を防ぐ)場合である。
最近のハードディスクは以前より高速になったとはいえ、いまでもメイン・メモリ(半導体メモリ・チップ)と比べるとけた違いに遅いことに変わりはない。具体的には、シーケンシャルなデータ転送で数倍〜数十倍もハードディスクはメモリより遅い。ランダム・アクセスに至っては、ハードディスクだと磁気ヘッドのシークが生じるため数ms単位のタイムラグが生じ、メイン・メモリとの速度差はさらに広がる。ハードディスクにアクセスした瞬間にデータ転送速度は劇的に下がるため、アクセス頻度が高くなるほどIAサーバの処理速度は下がってしまうわけだ。
処理速度を維持するためには、必要とするアプリケーションのワーキング・セットやデータをなるべくメイン・メモリ上に配置(オン・メモリなどと呼ぶ)して、ハードディスクへのアクセス頻度をなるべく低く抑えるのが効果的だ。例えばファイル・サーバでは、クライアント側がアクセスしたファイルをディスク・キャッシュと呼ばれるメモリ領域に保存しておき、再度そのファイルがアクセスされたらディスク・キャッシュから転送することで、クライアントから見たアクセス速度を高めている。またデータベース・サーバでも、なるべくデータをオン・メモリにすることで高速化できる。
当然、扱うデータの容量によってIAサーバに要求されるメモリ容量も変わる。ごく小規模のネットワークを扱うエントリ・クラスから、全社規模のエンタープライズに向かうにつれて、下表のように最大メモリ容量は大きくなる。
| セグメント名称 | 最大メモリ容量 |
| エンタープライズ(ハイエンド) | 16G〜512Gbytes |
| ミッドレンジ | 4G〜64Gbytes |
| ワークグループ | 2G〜16Gbytes |
| エントリ・クラス | 2G〜4Gbytes |
| 2002年におけるIAサーバの最大メモリ容量 | |
| 2002年4月時点の現行機種と、2002年内に出荷予定のIAサーバ向けチップセットから、上記の値を割り出してみた。 | |
最大メモリ容量は、メモリ・チップの制御を担当するチップセットの仕様でおおよそ決まる。2002年中には、プロセッサが切り替わるのに伴い、多くのチップセットが新製品へ切り替えられることもあり、ほとんどのセグメントで最大メモリ容量は2倍以上と大きく向上している。特にエンタープライズ(ハイエンド)が大きいのはItaniumファミリ向け新チップセット(Intel 870など)によるものだ(Intel 870については、「ニュース解説:エンタープライズ重視のIntelを示したIDF Spring 2002 2. サーバ向けプロセッサの動向」参照)。
最大メモリ容量が少ないと、業務が拡大してIAサーバで扱うデータ容量が増大したときに対応しきれなくなる可能性がある。例えば、プロセッサ数を増やしても、メモリ容量がネックになり、必要なレベルまで処理能力が向上しないことも考えられる。メモリ容量についてもスケーラビリティを考慮すべきであることが分かるだろう。
容量を増やすための仕組み
エントリ・クラスは別としても、ワークグループ以上のIAサーバの最大メモリ容量はデスクトップPCと比べて非常に大きい。しかし、使っているメモリ・チップ自体は同等のものだ。最大容量を決める要因は、メモリ・モジュールとメモリ・バス(メモリ・モジュールとメモリ・コントローラを接続するバス)にある。
■Registered DIMMで単体容量と枚数の両方を増大
IAサーバで用いられるメモリ・モジュールは、Registered DIMM(RDIMM)と呼ばれるもので、デスクトップPCのDIMM(Unbuffered DIMM)とは仕様が異なる。
 |
| IAサーバに使われているRegistered DIMM(RDIMM)の例 |
| これはPC1600対応のRDIMM。基板端の金色の信号端子列脇に並ぶ3つの黒いチップ(通称「レジスタ」)がRDIMMの特徴で、メモリ・チップとメモリ・バスの間で信号の電流増幅やタイミング調整などを担う。 |
一般的に、メモリ・バスに接続しているチップが増えてくると、電気信号の波形が乱れていき、しまいには正常に信号が伝わらなくなる(データが化けたりチップが異常動作したりする)。そのため、1系統のメモリ・バスに接続できるメモリ・モジュールの枚数にはどうしても上限がある。
Unbuffered DIMMに比べてRDIMMは、1系統のメモリ・バスに装着可能なモジュール枚数が多く、また1枚のメモリ・モジュールに搭載可能な最大メモリ・チップ数も多い、という特徴を持つ。大雑把には、DDR SDRAM搭載DIMMの場合、メモリ・チップ1つの容量とメモリ・ソケット数が同じなら、Unbuffered DIMMに対してRDIMMは2倍の容量のメモリを装着できる。また、多数のメモリ・チップを実装する場合、RDIMMの方がより安定して動作するという。しかし、回路が追加されている分、RDIMMは高価である(この2種類のDIMMについては、「PCメンテナンス&リペア・ガイド:第3回 メモリ増設前の基礎知識 2. メモリにまつわるスペックの読み方」のコラムを参照)。
■複数のメモリ・バスを実装してメモリ・ソケット数を増やす
RDIMMだけでは、前述の通りデスクトップPCと比べて2倍程度しか最大容量を増やせない。そこで、独立したメモリ・バスを複数設けるという技術がIAサーバではよく用いられる。具体的には、メモリ・バスのインターフェイス回路を複数個、チップセットに内蔵させ、物理的に配線が独立しているメモリ・バスをそれぞれに接続する。すると装着可能なメモリ・モジュールの最大枚数は、(メモリ・バスの本数)×(1系統当たりの上限枚数)になり、大幅に最大メモリ容量を増やせる。
 |
| 2系統のメモリ・バスを持つIAサーバのメモリ・サブシステムの例 |
| これはメモリ・モジュールを搭載するための専用ドータ・カード(メモリ・コントローラはマザーボード側にある)。左右それぞれ4本のDDR SDRAM DIMMソケットがあるが、赤い矢印が表しているように、それぞれ別系統のメモリ・バスに接続されている。このドータ・カードには各系統につき4GbytesまでDIMMを装着できるので、合計8Gbytesまで実装できる。 |
この技術は、後述するメモリの転送速度向上や耐障害性の向上とも連動しており、前述のIAサーバのメモリ・サブシステムに対する3つの要件すべてを実現するのに役立つ。それに、半導体技術の進歩により、複数のメモリ・バスをサポートする回路をチップセットに集積させるのも比較的容易になってきたこともあって、最近のミッドレンジ以上のIAサーバでは複数のメモリ・バスの実装が一般化している。2002年登場のIAサーバの場合、ワークグループは1〜2系統、ミッドレンジは2〜4系統、エンタープライズ(ハイエンド)は4〜8系統以上のメモリ・バスをそれぞれ装備するだろう。
メモリの耐障害性向上技術のスタンダード「ECC」
前のページに記したメモリ・サブシステムに対する要件のうち、最も重要なのは「優れた耐障害性と可用性」といえるだろう。何も対策なしでメモリに障害が生じると、重要なデータが失われたり、プログラムが暴走してシステムがハングアップし、サービスが止まってしまったり、というIAサーバにとって深刻な事態を招くからだ。いくら大容量かつ高速なメモリでも、ちょっとした障害でIAサーバが機能しなくなってしまうのでは使い物にならない。
メモリの耐障害性を高めるには、メモリに障害が生じてデータの損失というエラーが生じたことを「検出」し、エラーの起こったデータを「訂正」して元に戻す、という技術が不可欠だ。現在、PCやIAサーバで一般的に用いられているメモリ障害の検出・訂正技術は、ECC(Error Correcting CodeあるいはError Check and Correct)と呼ばれるものだ。ECC自体はメモリだけではなく通信やデータ記録などでも使われるエラー検出・訂正の手法の1つで、元のデータに対してデータの正当性を検出するためのコードを別途生成して付加しておき、エラーの検出や訂正に利用するというものだ。
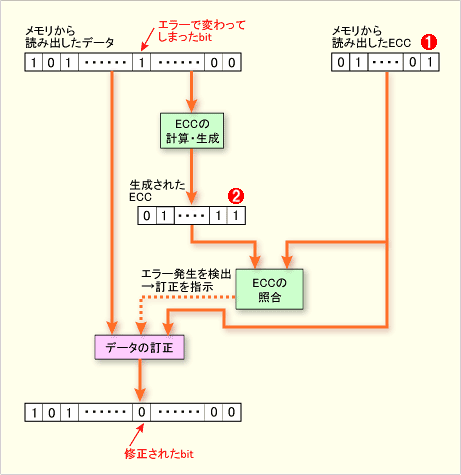 |
| ECCメモリの動作の概念図 |
| これは、ECCメモリからデータが読み出される際のエラー検出/訂正の仕組みを、概念として表したものだ(実際の回路の動作とは異なる部分がある)。メモリにデータが書き込まれる際、チップセット内蔵のメモリ・コントローラは、そのデータからハミング・コード(Hamming Code)と呼ばれるコードを生成して、元のデータと同時にメモリに書き込む( |
もちろん、ECCメモリでも無制限にエラーの検出やデータの訂正ができるわけではない。単位となるデータのbit数と、生成するハミング・コードのbit数に応じて、検出/訂正できるbit数は増減する。現在の汎用的なECC対応DIMMの場合、64bitのデータに対して8bitのECCを保存できるよう設計されているが、これだと1bitの訂正と2bitの検出が可能だ。逆にいえば64bitのデータ中、同時に2bitでエラーが生じると訂正はできず、データが失われることになる。また3bit以上エラーが発生すると、ほかのケース(正常/1bitエラー発生/2bitエラー発生)と混同してしまい、エラーの検出すらできない可能性がある。
| 関連記事 | |
| エンタープライズ重視のIntelを示したIDF Spring 2002 2. サーバ向けプロセッサの動向 | |
| 第3回 メモリ増設前の基礎知識 2. メモリにまつわるスペックの読み方 | |
| 「System Insiderの特集」 |
- Intelと互換プロセッサとの戦いの歴史を振り返る (2017/6/28)
Intelのx86が誕生して約40年たつという。x86プロセッサは、互換プロセッサとの戦いでもあった。その歴史を簡単に振り返ってみよう - 第204回 人工知能がFPGAに恋する理由 (2017/5/25)
最近、人工知能(AI)のアクセラレータとしてFPGAを活用する動きがある。なぜCPUやGPUに加えて、FPGAが人工知能に活用されるのだろうか。その理由は? - IoT実用化への号砲は鳴った (2017/4/27)
スタートの号砲が鳴ったようだ。多くのベンダーからIoTを使った実証実験の発表が相次いでいる。あと半年もすれば、実用化へのゴールも見えてくるのだろうか? - スパコンの新しい潮流は人工知能にあり? (2017/3/29)
スパコン関連の発表が続いている。多くが「人工知能」をターゲットにしているようだ。人工知能向けのスパコンとはどのようなものなのか、最近の発表から見ていこう
|
|





