Loading
|
@IT|@IT自分戦略研究所|QA@IT|イベントカレンダー+ログ | |
|
Loading
|
|
|
| @IT > Linuxの真実、Windowsの真実(9) |
|
企画:アットマーク・アイティ 営業企画局 制作:アットマーク・アイティ 編集局 掲載内容有効期限2004年12月31日 |
|
|
|
|
|
これまで本シリーズでは、主に中小規模の情報システム構築を想定して、LinuxとWindowsそれぞれの特徴と長所・短所を検討し、特に間違った先入観が持たれやすい点について是正を試みてきた。 中小規模の情報システムは、大規模な基幹情報システムとは異なり、事業部や部門、あるいは中小事業者などの単位で、草の根的に誕生し、発展していくケースが少なくない。当初このような情報システムは、互いをよく知る少人数のチームで使われることが多いため、「とにかく動いて必要な機能要件を満たすこと」が最優先され、アクセスの集中による負荷への対処や、万一のシステム障害を見越した可用性への対処などはあまり考慮されないものだ。しかし場合によっては、ビジネス環境の急速な変化などによって、当初想定していた規模を大きく超える負荷がかかるようになったり、サービス停止によって引き起こされる金銭的被害のリスクが大きく高まったりする場合がある。 特にSOA(Service Oriented Architecture)に基づく情報システム連携が注目される昨今、従来なら単独で稼働していたシステムが、より大きなシステムの一部として活用される可能性は広がっている。情報システム投資を長い目で無駄にしないためには、目の前にあるユーザー・ニーズを満たすばかりでなく、こうした将来の発展も念頭に置く必要がある。 今回は、基本的に単体のコンピュータで構成された中小規模のサーバから、可用性や負荷耐性などをOSレベルの機能で一段進めたクラスのシステムを念頭に、情報システムの可用性とスケーラビリティに注目し、LinuxとWindowsを取り巻く環境を比較してみよう。
両OSを比較する前に、可用性とスケーラビリティについて簡単に説明しよう。 「可用性(アベイラビリティ)」とは、サービスのダウンタイム(停止時間)に関するリスクを指すものだ。「可用性が高いシステム」といえば、サービス・ダウンタイムのリスクが低いシステム、つまりサービスを停止することなく、連続稼働できる能力に優れたシステムということになる。 「スケーラビリティ」とは、「リソース追加によって処理量を増大できる能力」のことである。スケーラビリティは、例えば「1分かかっていた処理が30秒で完了する」といったたぐいの単純な処理速度を指すわけではない点に注意が必要だ。スケーラビリティは、一定の負荷に対する応答速度ではなく、応答速度を犠牲にすることなく、より高い負荷に耐えられる能力を意味している。 スケーラビリティの高いシステムとは、「ボトルネックを効率よく解消できるシステム」と言い替えることができる。これは簡単なようだが、現実のボトルネックは、ハードウェアやソフトウェア、アプリケーションの構成など、主にシステムの構成にかかわる要因のほか、システムの利用パターンや負荷状況などが密接にからみあって露呈するため、場所の特定は容易ではなく、リソースの追加によるネックの解消も簡単ではない。当然ながら、本来のネックではない部分にいくらリソースを投入したところでネックは解消されない(例えばハードディスクへの読み書きがネックになっているときに、いくらプロセッサ・パワーを追加しても意味はない)。スケーラビリティの高いシステムなら、わずかな追加投資によるリソース追加などで処理能力を高められるケースでも、スケーラビリティに乏しいシステムでは、システム全体の刷新に迫られ、莫大な再投資が避けられなくなることもある。 リソースの追加方法には大きく2種類がある。このうち1つは、例えばプロセッサ・パワーの増強やメモリの増加など、1台のコンピュータに対してリソースを追加する「スケール・アップ」と呼ばれる方法だ。スケール・アップの余地は、対応最大メモリ・サイズ、マルチプロセッサ対応能力などによって決定される。もう1つは、複数のサーバからなるサーバ・ファームにサーバを追加することで、アプリケーションの処理能力を高める「スケール・アウト」と呼ばれる方法である。通常はクラスタリング・テクノロジを利用してサーバの追加を行う。クラスタリングでは、負荷の高い処理を効率よく多重化する機能や、処理の多重化を実施してもデータの整合性を保証する機能などが提供される。ただしスケール・アウトによって処理能力向上を実現するには、ベース・システムだけでなく、上位のアプリケーション側も、特定のプロセスによる処理(例えば排他的なファイル・アクセス)が、ほかのプロセスの処理に影響を及ぼさないようにしなければならない。 システムのスケーラビリティを高めるためには、ボトルネックがある場所と状態などに応じて、スケール・アップやスケール・アウトを柔軟に選択し組み合わせられるようにする必要がある。
Linuxプラットフォームでは、さまざまなベンダから提供されるソフトウェアを利用して、クラスタリングによる負荷分散や可用性向上を図ることが可能だ。これらは無償製品から有償製品までさまざまで、用途と目的、予算などに応じて柔軟に構成を選択できる。Linuxベースのクラスタリング・ソリューションの詳細については、下記の記事が参考になる。
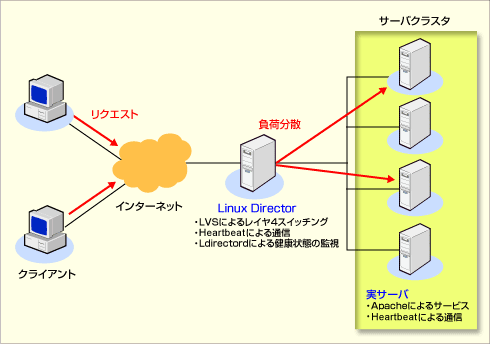
ひとくちにクラスタリング・システムといってもさまざまな形態があるが、小〜中規模クラスのシステムでよく目にするのは、ECサイトなど、多数のクライアントからの同時接続を処理するWebアプリケーションで、WebサーバをTCP/IPレベルのネットワーク・ロードバランス(NLB:Network Load Balance)で多重化し、負荷分散を実現するケースだろう。 ソフトウェアのライセンス・コストを圧縮したいなら、すべてオープン・ソース・ベースの無償ソフトウェアで構成することも可能だ。この場合は、Linux Virtual Server(以下LVS)でNLBを構成し、NLBを構成する複数サーバの正常動作と障害時の自動対応などをHeartbeatとLdirectordで実装するのが最もポピュラーだろう。 LVSは、TCP/IPベースのスイッチング機能を提供し、Webサーバやメール・サーバなどのネットワーク・サービスの負荷分散を可能にするソフトウェアで、ボランティア・ベースのプロジェクトで開発され、GPLでソースも提供されている。LVSをインストールしたLinuxコンピュータが「Linux Director」となり、受け取ったパケットを検査し、クラスタに参加するWebサーバやメール・サーバなどにパケットを分散配信する。
Heartbeatは、“heartbeat”と呼ばれるクラスタ構成用のプロトコルを実装した製品である。Heartbeatを組み込むと、クラスタを構成するコンピュータ間でメッセージが一定の間隔で送受信されるようになる。そして特定のコンピュータからのメッセージを受信しなくなったら、そのコンピュータに障害が発生したとして、別コンピュータでの代替処理などの回避措置を取れるようにする。またLdirectordは、特定のURLを定期的にリクエストし、応答に予測された文字列が含まれているかをチェックし、実サーバの稼働状態を監視するデーモンである。LVSは、このLdirectordの監視報告をもとに複数サーバ間での負荷分散を実施する。 LVSに加えHeartbeat、Ldirectordとも、オープン・ソース・ベースで開発されており、以下の各コミュニティのサイトから無償でソフトウェアを入手できる。なお、これら3つのソフトウェアは、Ultra Monkeyプロジェクトのホームページから一括して入手することも可能だ(Ultra Monkeyのホームページ)。
■インストールと初期設定 そしてインストール後の初期設定では、環境に応じて3つのソフトウェアの設定ファイルを調整しなければならない。これにはネットワークやクラスタリング・テクノロジに対する深い知識が不可欠である。ドキュメントも用意されているが、開発主体であるコミュニティにそれぞれ散在している。統合的な設定、運用管理ツールも存在しない。うまく稼働にこぎ着けたとしても、障害時の対処においても高い技術力が必要であるし、構築したシステムのスケーラビリティは、それを構成する各ソフトウェアの最小公倍数的なものにならざるを得ない。 有償製品を使えば、より容易な初期設定や運用管理が可能かもしれない。しかしその場合、大きな障害なく対応できるシステムのスケーラビリティは、選択した製品がカバーする領域に限定されてしまう。必要なら、ほかのベンダが提供する製品に乗り換える手もあるが、それには多大な移行コストが発生する可能性が高い。
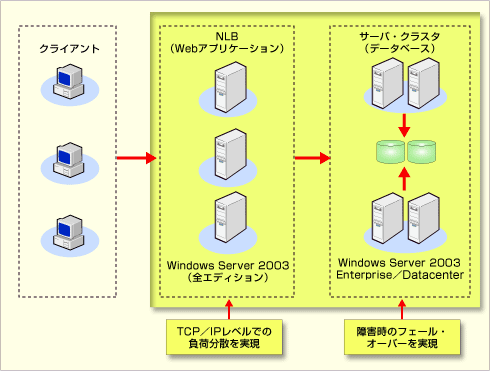
Windows Server 2003は、すべてのエディションにネットワーク・ロードランス(以下NLB:Network Load Balance)の機能が標準で搭載されている。前出のNLBの例なら、Windows Server 2003だけでシステムを構築することが可能だ。 システムの可用性を高めたければ、Windows Server 2003 Enterprise Edition、Datacenter Editionを利用して、サーバ・クラスタを構築できる。サーバ・クラスタは、連結動作するように構成された複数のサーバ・コンピュータ群で、一部のサーバがダウンするなどクラスタ内で障害が発生すると、リソースがリダイレクトされ、作業負荷が再分散されてサービスは継続される。完全にシームレスなサービスの継続は難しいが、簡単な操作(例えばブラウザでの画面の更新など)でユーザーは作業を再開できる。 もちろん、NLBとサーバ・クラスタを組み合わせることも可能だ。これらのテクノロジを組み合わせることで、高いスケーラビリティを実現するとともに、ハードウェア障害(コンピュータ本体やディスク・ストレージなど)やソフトウェア障害(アプリケーションのダウンなど)などでもサービスを継続できる高い可用性を実現することができる。
今回の想定環境からははずれるが、さらに一歩進んだスケーラビリティが必要なら、サーバ・ソフトウェアのApplication Center 2000を利用することで、コンポーネント・ロードバランス(CLB:Component Load Balance)を実現することも可能だ。CLBクラスタでは、アプリケーションをCOM+コンポーネントのレベルで複数のサーバに分散させることができる。より上位のアプリケーション・レベルでスケーラビリティを意識した設計を導入すれば、NLBなど低位インターフェイス層レベルでの並列化では実現できない高度なリソースの最適化が可能になる。例えばアプリケーションの一部が特定のステート(=状態)に依存して動いている場合、NLBだけでは処理を多重化することはできないからだ。 このように、スケーラビリティを実現するためのテクノロジや製品がワンソースで実現できるところがWindowsの大きな魅力である。開発主体は1つなので、スケール変更時の負担も、まったくの別製品に移行する場合よりは小さい。また構成がパターン化しているため類似の導入実績も多く、実績に基づく情報を頼りにシステムの運用管理できる可能性が高い。 またWindowsプラットフォームでは、マイクロソフトを始めさまざまなソフトウェア・ベンダが提供するサーバ管理ソフトウェアを統合できるのも大きなメリットだろう。まもなく発表が予定されているMicrosoft Operations Manager 2005(MOM 2005)を利用すれば、クラスタを構成するサーバ・コンピュータやアプリケーションの状態をセンター・コンソールのGUIで集中的に管理することができる。これにより障害の発生やサーバ負荷の状態、フェイルオーバーの発生などを素早く認識し、対処できるようになる。
規模の大小にかかわらず、企業で使用する情報システムは、連続的かつ安定的な業務処理の責を担っている。通常の状態で正しく動くことは当然として、万一の障害時のリスクをいかに低減するか、将来的な負荷の増大に柔軟に対応できるスケーラビリティをどうするかは、どのような情報システム開発においても検討されなければならないテーマだ。 今回に限らず全般的にいえることだが、Linuxでのシステム構築では、さまざまなソフトウェアを選択できるという柔軟性に優れ、初期ライセンス料を小さくできるものの、最適な構成を目指すにはOSや関連ソフトウェア、ネットワークに関する踏み込んだ知識が必要であり、開発主体が異なるソフトウェアを組み合わせた際に発生する障害や、将来の予想外のサポート終了などのリスクをエンド・ユーザーが背負う必要がある。この点シングル・ベンダで統合的なシステム構築が可能なWindowsでは、製品選択の幅はそれほど広くなく、初期のソフトウェア・ライセンス・コストは高いが、代わりに可用性やスケーラビリティを必要に応じて容易に実装可能な柔軟性のあるシステムが構築でき、長期的なサポートも約束されている。 これは机上の空論ではない。インターネットに公開された各種エンタープライズ・システム向けのベンチマーク結果がこれを裏付けている。例えばERPソフトウェアとして高いシェアを持つSAPのベンチマーク・テスト(SAP Business Information Warehouse Standard Application Benchmark)において、Windows Server 2003は1位にランクされている(2004年11月16日現在)。またトランザクション性能を評価するTPC-Cベンチマーク・テストでは、Windows Server 2003+SQL Server 2000をベースとするシステムが上位ランクに多数ランクインしており、コストパフォーマンスでも最高の成績を残している(同じく2004年11月16日現在)。 プラットフォームの選択においては、長期的な視野にたった情報投資の効率化を考慮する必要がある。
|
|