オプティマイザの判断ミスを疑ってみよう:Oracleパフォーマンス障害の克服(4)(3/3 ページ)
Oracleデータベースの運用管理者は、突発的に直面するパフォーマンス障害にどうやって対処したらよいか。本連載は、非常に複雑なOracleのアーキテクチャに頭を悩ます管理者に向け、短時間で問題を切り分け、対処法を見つけるノウハウを紹介する。対象とするバージョンはOracle8から9iまでを基本とし、10gの情報は随時加えていく。(編集局)
データの分布・量に偏りのある表でのオプティマイザの挙動
では、リスト9のデータをtest_tableに挿入して、データ分布・量を変化させると、オプティマイザはどのような判断を下すでしょうか。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
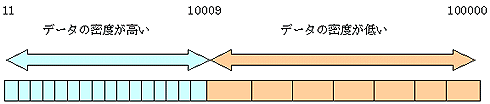
この表は、11から10009までは1つずつデータが増分で入っているためデータの密度は高く、以降から100000までは100ずつの増分でデータの密度が低いと考えられます。この表にANALYZEコマンドを実行し、データ10件を取得する検索を行います。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***

「INDEX (RANGE SCAN) OF 'IDX_TEST_TABLE' (NON-UNIQUE) (Cost=2 Card=2)」と表示され、データ密度の高い範囲の検索では、索引が使用されたことが分かります。次は、データ密度の低い範囲を検索してみます。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***

同じ10件のデータを取得しているにもかかわらず、フル・スキャンを採用していることが「TABLE ACCESS (FULL) OF 'TEST_TABLE'(Cost=3 Card=100 Bytes=1200)」から分かります。索引を使用するよりも、対象範囲の表データを直接取得した方が検索にかかるコストが低いと判断されたということです。このようにコストベースを採用したオプティマイザは、統計情報によりデータベース内のデータの傾向も判断し、どちらの検索コストが低いかを判断していることが分かります。
オプティマイザの判断ミスを発見するオプティマイザの判断ミスを発見する
ただし、ここでのコストは単純に取得データ全体にたどり着くまでのアクセスパスを判断しているだけで、パフォーマンスやサーバに対する負荷まで考慮していません。リスト11のSQL文にヒント文注1 を使って、強制的に索引を使用させる検索を行ってみましょう。
注1:ヒント文
SQL文に直接使用したいインデックスを記述し、オプティマイザに指示を送るコメント。コメントアウト文で記述する。オプティマイザのルールよりも優先されるため、インデックスを使った検索が明らかに有効なときに使用すると、パフォーマンスやサーバの処理負荷軽減につながる。ただしANALYZEを正しく行い、更新が頻繁でデータの偏りが大きいデータベースに通常業務で使用すると、ANALYZEの効果が薄れるため十分注意する。
リスト12のSQL文では「/*+ INDEX(テーブル名 インデックス名) */」がヒント文です。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***

ヒント文を使用したことで、索引を使用したテーブルのスキャン「TABLE ACCESS (BY INDEX ROWID) OF 'TEST_TABLE'(Cost=5 Card=101 Bytes=1212)」と索引の範囲検索「INDEX (RANGE SCAN) OF 'IDX_TEST_TABLE'(NON-UNIQUE) (Cost=2 Card=101)」が行われています。図6のフル・スキャンでは「Cost」パラメータが「3」だったのに対し、図7のインデックス・スキャンでは「Cost=5」になっています。つまり、オプティマイザはフル・スキャンの方が有効だと判断していた、ということになります。
では、実際このオプティマイザの判断は正しかったのでしょうか。ユーザーが期待するようにレスポンスが速く、なおかつサーバに対する負荷は本当に軽く済んだのでしょうか。実はこの検索はリスト11のフル・スキャンよりも、リスト12のインデックス・スキャンの方がサーバに対する負荷は低いと考えられます。
図6と図7の画面下部に表示されている「統計」の「consistent gets」というパラメータは、「SELECT文でアクセスしたバッファキャッシュのブロック数」です。つまりメモリ上に展開されたテーブルデータを見つけるまでにアクセスしたメモリブロック数です。リスト11のSQL文ではこの「consistentgets」は「32」であり、ヒント文を使用したリスト12では「5」でした。つまり、コストをベースにした判断では有効であると判断されたリスト11は、実際にはより多くの処理(メモリブロックのアクセス)を行っていたのです。
もちろんオプティマイザが正しい判断をする場合もありますが、このような逆効果になることも十分あり得るわけです。これもパフォーマンス障害時の問題切り分けに有効な判断材料の1つとなります。
今回は、サーバがANALYZEコマンドで得られる統計情報をどのように判断して実行計画を作成しているかを確認しました。障害発生時は、SQL文だけでなくOracle側の設定に起因する問題もあることを知ることが重要です。次回はメモリ(データベース・バッファキャッシュ、共有プールなど)に関連した問題の解決方法を解説します。(次回に続く)
Copyright © ITmedia, Inc. All Rights Reserved.