バッチアプリケーション設計のポイント:Oracle技術者のためのバッチアプリ開発講座(1)(1/3 ページ)
データベースの運用に当たって、効率のよいバッチアプリケーションが作成できるかどうか、は大きな課題です。本連載では、Oracle Databaseの管理運用を前提に、効率のよいバッチアプリケーション作成のためのテクニックを紹介していきます。
バッチ処理の抱える問題
オープン系技術の導入によって、企業システムのフロントエンド(画面周り)は大きく進化を遂げました。しかし、バックエンド(サーバ周り)でのバッチ処理は、今日でもさまざまな問題を抱えています。
最も深刻な問題は、バッチの処理性能が著しく低下してしまうことでしょう。業務のIT化が進むにつれて、データベースに蓄積されるデータ量はどんどん増加する傾向にあります。また、Webなどで多様なサービスを展開するには、データをさまざまな形式に加工/集計する必要があります。
この2つのマイナス要因によって、既存のバッチアプリケーションにかかる負荷はますます高くなっています。その結果、夜間のバッチ処理が終了せず、翌日の業務がストップする場合もあります。
さらに、ビジネスの状況は刻一刻と変化します。当然、必要な情報も頻繁に変化するでしょう。新たな情報が必要になれば、その元となるデータもこれまでとは違う形式に加工/集計しなければなりません。結果として、バッチアプリケーションの改修作業も頻繁に発生することになります。
仕様書の修正やテストの実施を含めると、簡単な改修内容であってもそれなりの工数が必要になります。しかし、もたもたしているとビジネスチャンスを逃してしまうかもしれません。
本連載では、このようなバッチ処理の問題を解決するうえで知っておきたいバッチアプリケーション開発のポイントやテクニックについて解説します。単なるデータの保管場所としてしか利用されない傾向のあるデータベースを有効活用すれば、バッチアプリケーションの実装効率や処理性能は飛躍的に向上します。日々のバッチ処理の高速化や効率化に取り組んでいるOracle技術者の皆さんに、ぜひとも読んでいただきたいと思います。
第1回の今回は、バッチアプリケーションを設計するうえで考慮するべき4つのポイントについて解説します。
バッチアプリケーションは定型処理の組み合わせ——開発方針で処理効率が変わる
流通業の販売物流システムや製造業の生産管理システム、銀行の勘定系システムなど、企業の基幹業務システムには大規模なバッチ処理が数多く存在します。これらのバッチ処理は一見とても複雑に見えますが、そのほとんどは定型的な処理の組み合わせにすぎません。
バッチ処理は、大ざっぱにいってしまえば「入力」→「加工」→「出力」というたった3つの工程からなります。各工程には表1のようなお決まりの処理パターンがあります。
| 工程 | 詳細 |
|---|---|
| 入力 | ファイルからの入力 |
| データベースからの入力 | |
| 加工 | データの抽出 |
| データの削除 | |
| データの加工 | |
| データの集計 | |
| データの結合 | |
| データのマージ | |
| 出力 | ファイルへの出力 |
| データベースへの出力 | |
| 表1 バッチアプリケーションの定型処理 | |
表1を見て分かるとおり、まず、処理対象のデータをファイルやデータベースを経由して取得します(ファイルからの入力/データベースからの入力)。次に、必要なデータのみに絞り込み(データの抽出/削除)、加工や集計処理を行い(データの加工/集計)、ほかのデータと組み合わせます(データの結合/マージ)。最後に、作成したデータをファイルやデータベースに保存します(データベースへの出力/ファイルへの出力)。
バッチ処理の設計では、このような定型処理へのブレイクダウン作業がメインとなります。目的の結果を得るために、どの定型処理をどのような順番で実行すれば最も効率よく処理を行えるかを検討しておく必要があります(図1)。
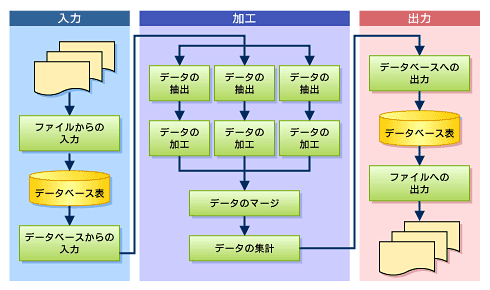
バッチアプリケーションが定型処理の組み合わせにすぎないということは、開発方針によって生産性に大きな差が出ることを意味します。すべてのアプリケーションをゼロから作成していては、同じような処理を何度もコーディングすることになってしまい、お金と時間の無駄です。そこで考えられるのが、定型処理を部品化してすべてのバッチアプリケーションで再利用する、という考え方です。こうしておくことで、品質の高いアプリケーションを簡単に大量生産できます。
Copyright © ITmedia, Inc. All Rights Reserved.